
Esta vez realizaremos unas consultas por uniones no sin antes dar una breve explicación de la integridad referencial, una característica de las bases de datos relacionales, siempre de la manera más sencilla posible.
Para los que el orden es importante esta serie de artículos sobre PostgreSQL 9.1 comienzan acá y la manera de conectarnos al servidor vía phpPgAdmin se describe aquí.
Pues bien, comenzemos ya: tenemos creadas dos tablas llamadas students y phone_numbers y como bien lo describe sus nombres en inglés, sirven para almacenar datos de estudiantes y sus números telefónicos. Como cada persona puede tener varios teléfonos (casa, trabajo, móvil, fax, etc.) y a su vez cada una de esas ubicaciones hoy en día pueden tener varios números diferentes (en mi caso tengo 2 en casa, 3 en el trabajo y uno celular) no tiene sentido crear campos para cada uno de ellos en la tabla students porque no sabemos cuántos va a tener cada inviduo. Cualquiera me puede rebatir diciendo que aunque sea debería suministrar un número de teléfono para alguna emergencia en clase (desde el punto de vista de este ejercicio donde somos una Academia de Software Libre) pero ni con eso contaría yo, es decir, puede darse el caso que no tenga ningún teléfono (hermosa es la película «Enemy of the State» ojalá la disfruten tanto como yo la disfruté en 1999). Es por tanto que en la tabla students no dejamos ningún campo para almacenar el o los que nos suministren y los guardaremos en la tabla phone_numbers teniendo cuidado de guardar de quién es cada cual.
Observemos que al seleccionar la tabla phone_numbers desde phpPgAdmin haciendo click en «constraints» («restricciones») descubriremos el trabajo que hizo Visual Paradigm traduciendo nuestro organigrama a la base de datos:
 Como en la entrada anterior agregamos algunos datos de los estudiantes tenemos dicha tabla de ejemplos de la siguiente manera:
Como en la entrada anterior agregamos algunos datos de los estudiantes tenemos dicha tabla de ejemplos de la siguiente manera:
 De nuevo hacemos click en la tabla phone_numbers e insertamos un registro tal como lo hicimos en la entrada anterior, sólo que en este caso y cuando lleguemos al campo idstudent automáticamente aparecerá una lista de los estudiantes que ya tenemos registrados, en este caso identificados del 1 al 4:
De nuevo hacemos click en la tabla phone_numbers e insertamos un registro tal como lo hicimos en la entrada anterior, sólo que en este caso y cuando lleguemos al campo idstudent automáticamente aparecerá una lista de los estudiantes que ya tenemos registrados, en este caso identificados del 1 al 4:
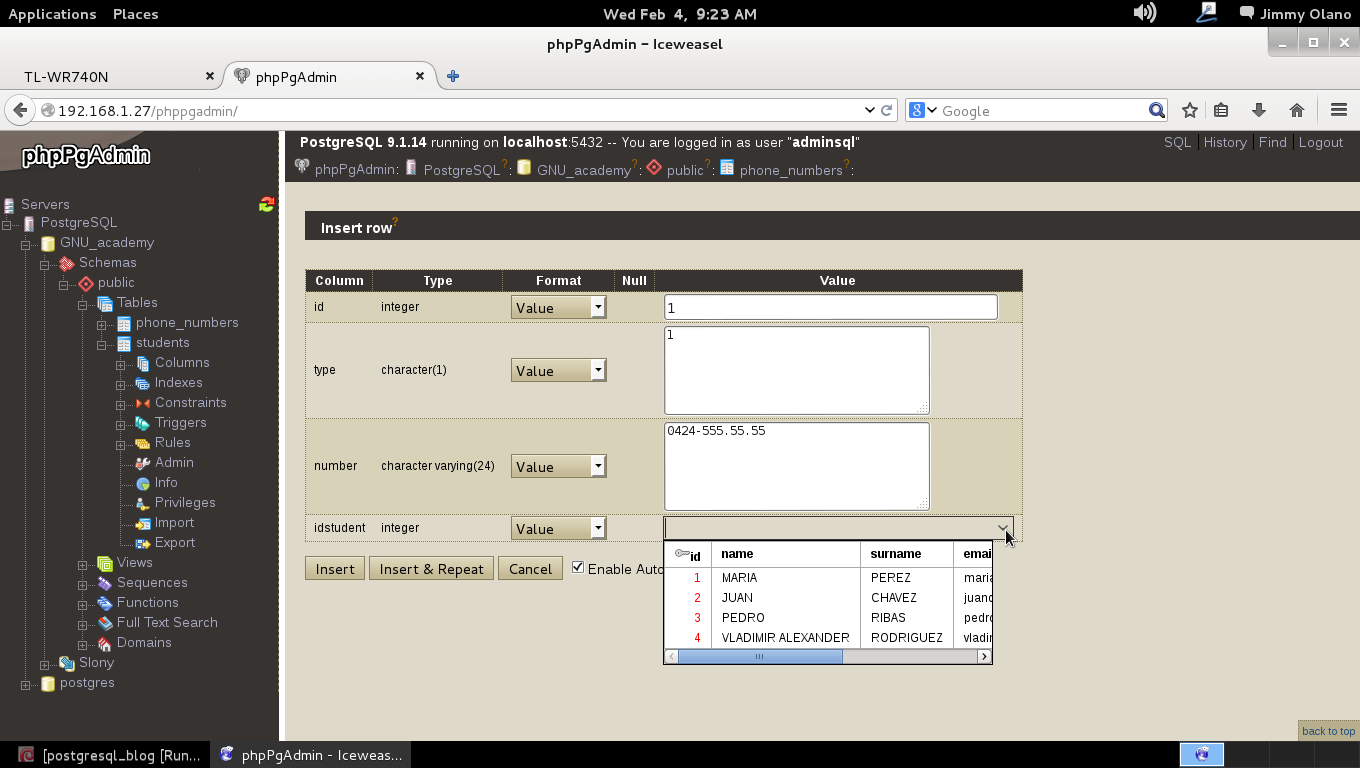 Para probar si la base de datos funciona correctamente en su integridad referencial colocaremos el idstudent = 5 (que aún no está registrado) y le damos click a «insert»:
Para probar si la base de datos funciona correctamente en su integridad referencial colocaremos el idstudent = 5 (que aún no está registrado) y le damos click a «insert»:
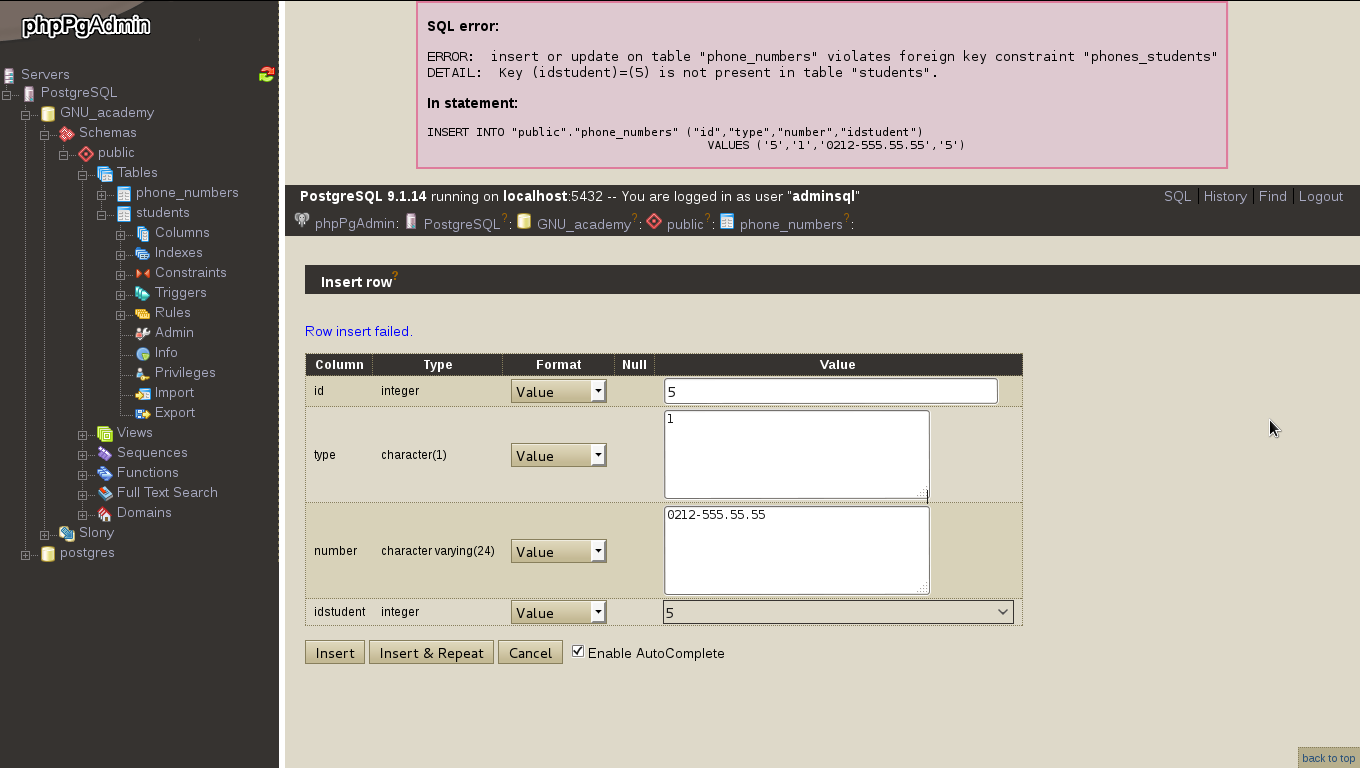 ¡Oh, sorpresa! nos devuelve un mensaje de error y no es para menos ¿para qué querríamos guardar un número de teléfono si no sabemos quién es su propietario? (a menos que trabajeís como detective, hay «caso de casos»).
¡Oh, sorpresa! nos devuelve un mensaje de error y no es para menos ¿para qué querríamos guardar un número de teléfono si no sabemos quién es su propietario? (a menos que trabajeís como detective, hay «caso de casos»).
Desistimos pues en nuestro intento de «embasurar» nuestra base de datos y procedemos a colocarles a los tres números telefónicos que insertemos un idstudent cualquiera entre 1 y 4 y al poco rato tenemos una bonita matrícula lista para clases (aunque falta agregar cursos, aulas, profesores, horarios… «Roma no se construyó en un solo día» reza el refrán, vamos poco a poco).
Una vez hecho esto ya estamos listos para hacer unas consultas entre ambas tablas y con propósitos didácticos ejecutamos la primera consulta (y de manera similar a nuestra entrada anterior):
SELECT students.name, phone_numbers.number
FROM students, phone_numbers
WHERE students.id = phone_numbers.idstudent;
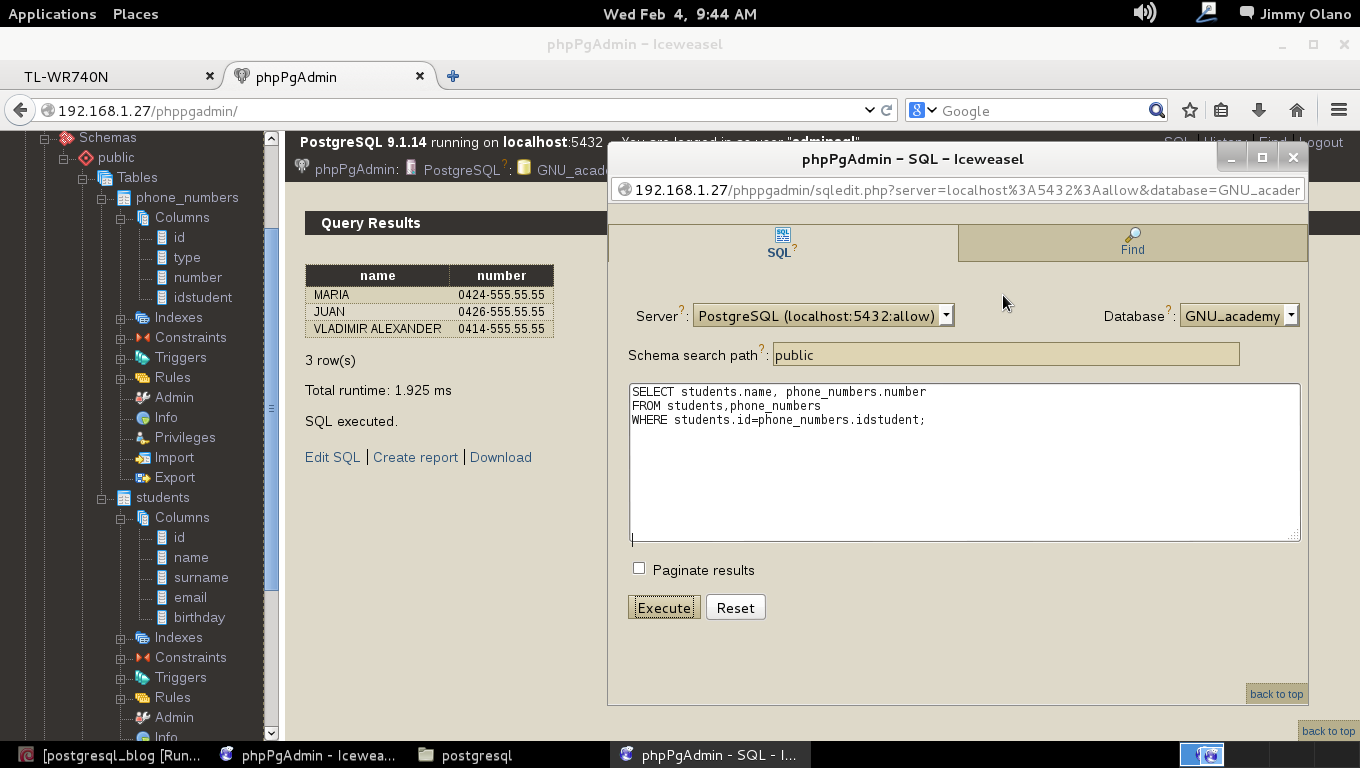 La consulta está en escrita en tres líneas pero la base de datos «sabe» que la misma termina cuando alcanza el punto y coma «;» y dicha manera de escribirla nos proporciona legibilidad para desglosarla y explicarla, línea por línea:
La consulta está en escrita en tres líneas pero la base de datos «sabe» que la misma termina cuando alcanza el punto y coma «;» y dicha manera de escribirla nos proporciona legibilidad para desglosarla y explicarla, línea por línea:
- La primera línea ordena que seleccione «SELECT» los campos «name» de la tabla «students» (de allí el punto como unión) e igual con «number» que pertenece a la tabla «phone_numbers». Esta sintaxis permite que, por ejemplo, dos campos con el mismo nombre en diferentes tablas sean identificados sin ambigüedad alguna.
- La segunda línea «FROM» instruye de cuáles tablas sacarán los datos.
- La tercera línea «WHERE» está el condicional: para cada estudiante que devuelva el o los números telefónico(s) registrado(s) relacionados entre sí por el identificador numérico.
Como sólo insertamos tres números telefónicos pues sólo tres estudiantes con teléfonos será lo que veremos (en este caso para cada estudiante un solo número telefónico que sería el caso más común). ¿Pero y si queremos visualizar TODOS los estudiantes, tengan o no número telefónico registrado?
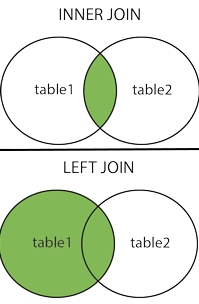
Uniones o «JOIN»:
En el lenguaje SQL existe el comando JOIN con sus prefijos INNER, LEFT y RIGHT haciendo la salvedad que «JOIN» = «INNER JOIN» y será el primero que veremos para realizar la misma consulta que hicimos con el condicional WHERE:
SELECT students.name, phone_numbers.number
FROM students
INNER JOIN phone_numbers
ON students.id=phone_numbers.idstudent;
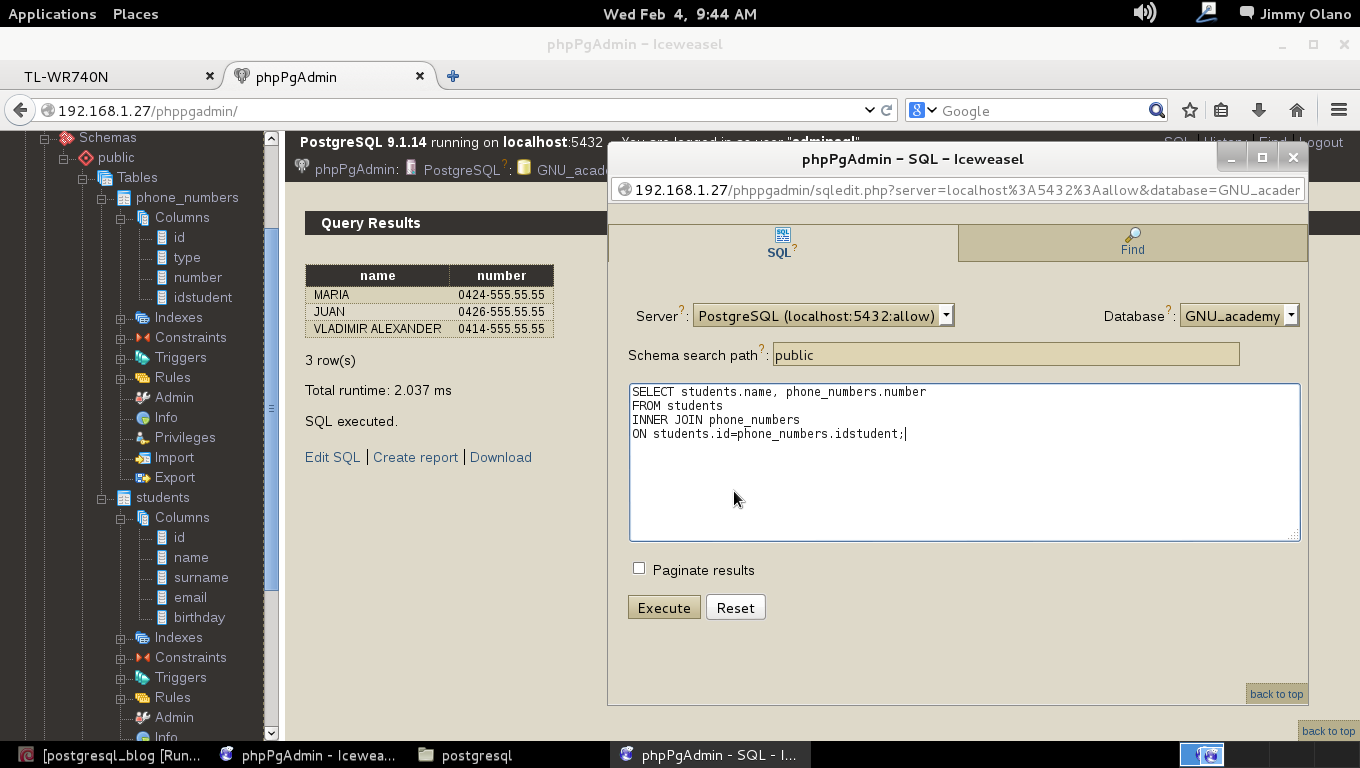
De nuevo desglosamos y analizamos línea por línea (recordad el para qué sirve el punto y coma al final de la consulta):
- La primera línea solicitamos los campos que nos interesan de ambas tablas, cada uno con su espacio de nombres para evitar confusiones.
- La segunda línea específicamos la tabla «principal» (esto tendrá sentido más adelante) es decir los estudiantes, ya que ellos son los propietarios de cada número de teléfono.
- La tercera línea indica hacia cual tabla se hará la unión, osea con cual se combinará.
- La última linea establece cómo relacionar los datos, en este caso una sola condición posible de relación entre ambas tablas (pudieran haber otras relaciones posibles pero por ahora no complicaremos las cosas).
Hasta aquí todo bien pero volvamos a la pregunta:
¿Pero y si queremos visualizar TODOS los estudiantes -y su(s) número(s) telefónico(s)-, tengan o no número telefónico registrado?
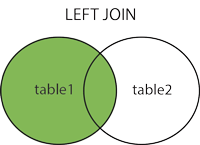
Es aquí que utilizaremos LEFT JOIN en vez de INNER JOIN, simplemente ese cambio, una sola palabra por otra:
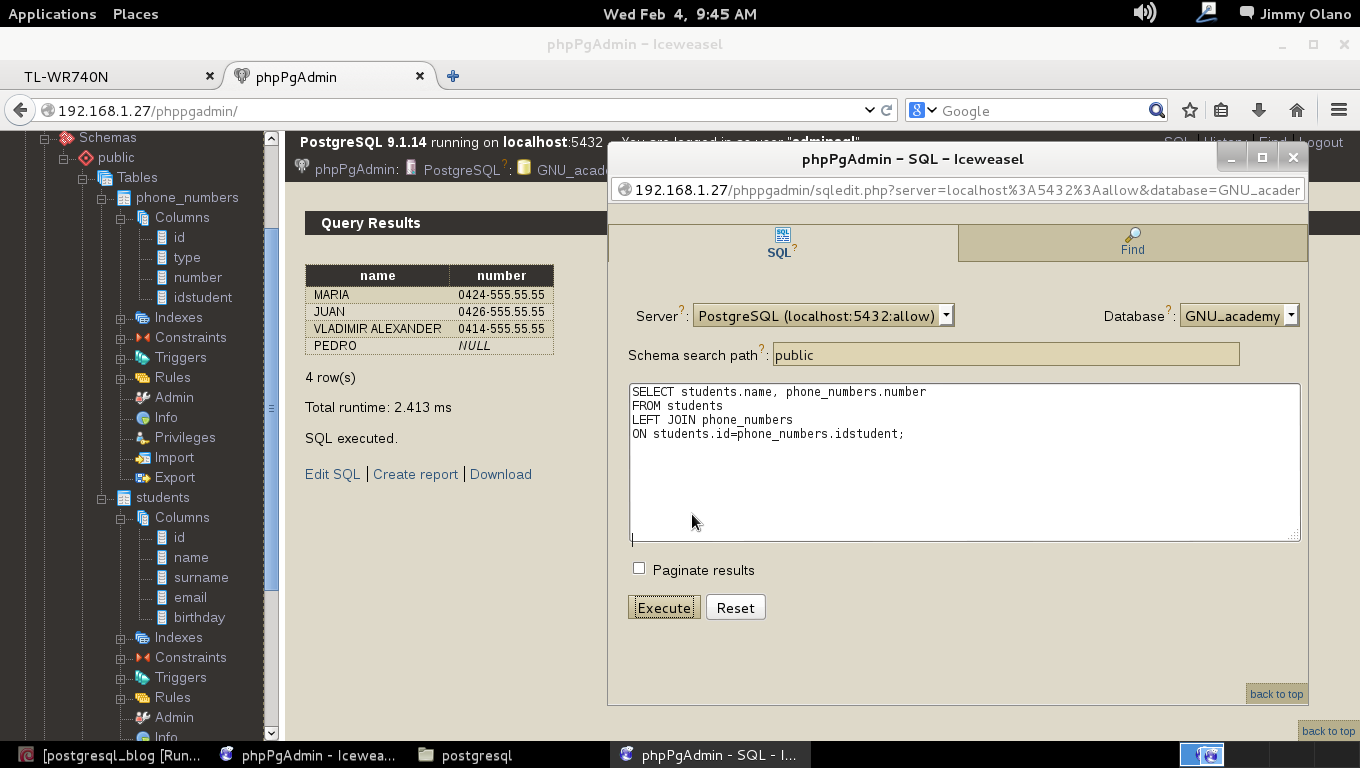
SELECT students.name, phone_numbers.number
FROM students
LEFT JOIN phone_numbers
ON students.id=phone_numbers.idstudent;
Y AHORA SÍ que observamos que el estudiante Pedro aparece pero en donde va el número telefónico muestra NULL el cual es una palabra que encierra un concepto que en base de datos trae aún hoy en día candentes discusiones pero que en este caso práctico muestra su utilidad: «NO TIENE NÚMERO TELEFÓNICO REGISTRADO Y NO SABEMOS SI REALMENTE LO TIENE YA QUE SIMPLEMENTE O SE NEGÓ A SUMINISTRARLO O EL INSCRIPTOR OLVIDÓ REGISTRARLO». Todo eso encierra el concepto de NULL.
Actualizado el martes 12 de enero de 2016: me hacen la sugerencia que pudieramos colocar un campo lógico (verdadero o falso) para saber a ciencia cierta si la persona posee algún teléfono. No veo mala esa idea pero recomiendo que le coloquen NULL como valor predeterminado pero que sea obligatorio ese dato -y por ende no permitirá guardar con NULL-. A nivel de la interfaz del usuario, el formulario que introduce datos para agregar personas deberá utilizarse un RADIO BUTTON sin valor preseleccionado en ninguno de los dos. Ejemplo:
Ya cerrando la entrada podemos acotar la consulta JOIN con un simple WHERE tal como ejercitamos en otra entrada:
SELECT students.name, phone_numbers.number
FROM students
LEFT JOIN phone_numbers
ON students.id=phone_numbers.idstudent
WHERE LOWER(students.email) ~ ‘hotmail.com’;
sólo que esta vez veremos sólamente los estudiantes que posean correo electrónico en «hotmail.com» (hoy día «outlook.com») y que tengan al menos un número telefónico registrado.
En la próxima entrada veremos y estudiaremos cuáles otras opciones existen sobre JOIN, tan importante es que en Wikipedia en castellano tiene su propia entrada completa.
<Eso es todo, por ahora>.