
Una manera de conectar a IPv6 desde IPv4 es realizar un «túnel» a un servidor habilitado con el Protocolo Teredo (además de otros componentes), veamos.
Seguir leyendo
Una manera de conectar a IPv6 desde IPv4 es realizar un «túnel» a un servidor habilitado con el Protocolo Teredo (además de otros componentes), veamos.
Seguir leyendo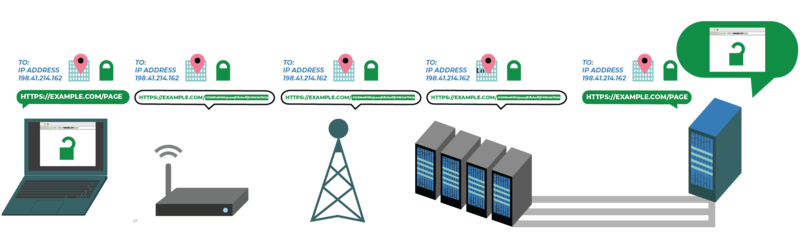
SNI permite que un servidor web que aloja varios dominios el entregar el certificado digital correcto a fin de lograr una conexión segura (HTTPS). Bajo HTTPS todo viaja de forma cifrada excepto el SNI, con tal propósito fue creado el protocolo ESNI.
Actualizado el viernes 22 de diciembre de 2023.
Seguir leyendo
 (4 votes, average: 5,00 out of 5)
(4 votes, average: 5,00 out of 5)![]() Cargando…
Cargando…
Escrito el miércoles 12 de junio de 2019
Actualizado el martes 22 de octubre de 2018
Tenemos tiempo que no escribimos por acá, hemos estado ocupados con lo de la Reconversión Monetaria y haciendo otros trabajos donde, además, hemos aprendido mucho (recordemos siempre nuestro «mantra»: «Solo se que no se nada»).

Esta entrada será muy sencilla, a nivel de principiante (ea, sin intención de connotación peyorativa, para nada, ojo) pero si tienen conocimiento básico sobre el Sistema de Nombres de Dominio recomendamos que hagan clic hacia este artículo para ampliar conocimientos.
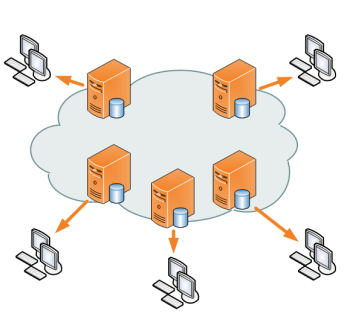
«Content Delivery Network» (CDN) o Red de Entrega de Contenidos es la forma moderna de garantizar que nuestra página web pueda ser visitada por millones de usuarios y consiste, de manera muy simplificada, de repartir nuestro contenido estático a través de servidores ubicados físicamente en distintas partes del planeta, de tal manera que según sea la dirección IP del visitante se contacte con el servidor más cercano. Veamos ahora los detalles ¡vamos!
Para poder entender hacia dónde vamos debemos ver de dónde venimos.
Tim Berner-Lee, inventor del hiperenlace y del internet tal como lo conocemos, arrancó con un ordenador avanzado para la época fabricado por la compañía «NEXT Computers» la cual fue fundada por el legendario Steve Jobs luego de que lo despidieron de «Apple Computer», la empresa por él creada. En aquellos años 90 nosotros comprábamos la revista PCMagazine en castellano donde daban cuenta en un artículo que esas computadoras NEXT tenían la increíble cantidad de 1024 megabytes en RAM y costaba cada una más de 10 mil US$ ¡sorprendente!

A dicho computador le pegaron un papelito indicando que era un servidor y que no debía ser apagado, estaba alojando la primera página web del mundo y pocos usuarios se conectaban a ella, específicamente los investigadores del CERN («European Organization for Nuclear Research» Organización Europea para la Investigación Nuclear).
Pues hoy en día tenemos los mismos recursos -incluso rebasan- que contaban y disponían los investigadores europeos: ordenadores con más de 8 mil megabytes de RAM y 4 núcleos de 64 bits con conexiones fijas a internet con más de 1 mbps de velocidad y sin ningún límite de megabytes son comunes, ¿Qué nos impide montar en nuestro hogar u oficina nuestra página web? La limitación es que nuestro proveeedor de internet muy probablemente nos proporcionará una dirección IP dinámica: al apagar el modem y volverlo a encender tendremos una dirección IP diferente y a nuestros usuarios tendremos que volver a notificarles del cambio. Para evitar dicho inconveniente desde los albores del nacimiento del internet se utilizan los DNS «Domain Name Service» Servicio de Nombres de Dominios: son ordenadores que uno les pregunta por un dominio (dirección web) y nos devuelve la dirección IP para conectarnos al ordenador que contiene la página web deseada.
Lo anterior lo podemos simplificar con los teléfonos móviles celulares: cuando una amiga os da su número simplemente lo ingresamos al teléfono y le damos marcar y listo, la encontramos y conectamos. Pero luego recordar ese número es el problema, para ello nuestro celular tiene una agenda donde podemos colocar el nombre de la chica asociada a su número telefónico. En este ejemplo el DNS sería la agenda de contactos y el número de teléfono sería la dirección IP. Huelga decir que los DNS son más avanzados que la agenda de contactos: si un dominio cambia su dirección IP ésta es automáticamente actualizada, cosa que no hace el programita de agenda de contactos del celular (a menos que llamara todos los días a la chica confirmando el número telefónico ¡Qué locura!).
Con este escenario, un ordenador en nuestra casa u oficina, con un acceso a internet las 24 horas del día sin limites de megabytes y una dirección IP fija y un DNS configurado estamos prestos a difundir al mundo nuestro trabajo sobre el software libre. Pero para hacerle honor a la verdad, lo que distingue un servidor web de un ordenador normal es la redundancia de sus componentes, así que tienen al menos dos fuentes de poder (si una se «quema»queda la otra funcionando y se puede cambiar sin necesidad de apagar el servidor), tienen al menos dos discos duros en RAID (escriben y leen los mismos datos en ambos discos) y también se pueden reemplazar sin apagarlo (al conectar un disco nuevo automáticamente la tarjeta madre copiará los datos del disco viejo al nuevo y «emparejará» la información), memoria RAM de seguridad que -adivinen- internamente son dobles y almacenan y comparan ambas copias constantemente y también tienen dos o más tarjetas de red, generalmente ethernet con cables de cobre o fibra óptica, de igual manera si una falla queda la otra funcionando -y no se pueden reemplazar porque son integradas a la tarjeta madre pero se puede adicionar una(s) en una(s) ranura(s) PCI libre-.
En cuanto a qué podremos hacer con un ordenador con dos o más tarjetas de red (si tenéis un ordenador portátil con tarjeta de red inalámbrica y ethernet podéis hacer pruebas) varios usos le podemos dar:
Esto que acabamos de explicar es para ir «abriendo la mente», para lo que luego queremos explicar acerca de los CDN’s.
Para continuar optaremos por configurar nuestro modem/concentrador/enrutador (hoy en día se puede dar los tres aparatos en uno, por eso decimos que tenemos más poder de hardware que los investigadores del CERN en los años 90). En todo caso explicamos que:
Así las cosas nuestro enrutador recibe las peticiones y las reenvía a nuestro servidor web: hasta allí todo va bien, pero ¿qué sucede si recibimos más visitas?
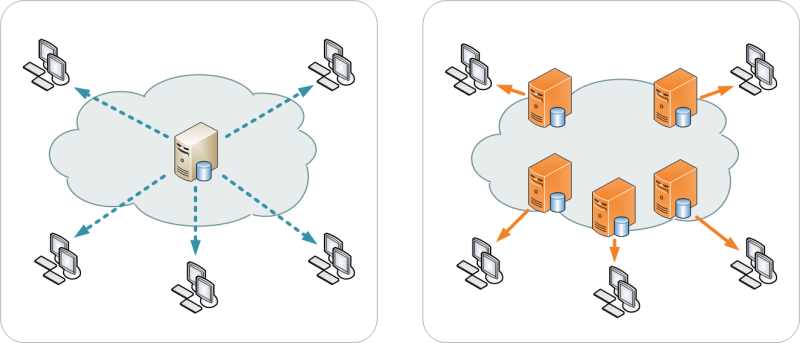
Con 4 ordenadores podemos realizar el siguiente esquema para atender más visitantes:
Este esquema tiene como ventaja, por supuesto, el poder atender más visitantes, manteniendo nuestro trabajo original en el ordenador 4 y teniendo respaldos en los ordenadores 2 y 3, el punto débil de la cadena sería el ordenador 1, que balancea la carga ya que si falla se cae por completo nuestro dominio, ojo con eso. Como desventaja podríamos mencionar, entre otras, el registro de los visitantes (quién ha sido atendido por ordenador 2 y quién por ordenador 3), problemas con las carpetas temporales en el caso que nuestros usuarios necesiten «subir» archivos a nuestra página web y con respecto al lenguaje PHP el almacenamiento de las variables de sesión que no serán iguales para todas las páginas (aquí debemos aclarar que nuestra página web es un sitio web conformado por varias páginas que pueden ser servidas tanto por ordenador 2 y ordenador 3: un visitante puede ver una hoja en ordenador 1 y al cabo del tiempo al volver a visitar el balanceo de carga lo envia a ordenador 3 por lo tanto las variables de sesión PHP serán con distintos valores, lo que pudiera ocasionar problemas de programación -«amnesia» de las aplicaciones-).
Pues que llega un momento que nuestro humilde modem ADSL no da para más velocidad, así que le pedimos a nuestro Proveedor de Servicio de Internet («Internet Service Provider» ISP) nos suba la velocidad pero va a ser que no, lo máximo ya lo tenemos, 10 mbps y ADSL2 que llega a 25 mbps no está disponible… Pues agregamos otra línea telefónica y otro modem y en teoría nuestro ISP debería colocarlos en modo vinculado «bonding»: con la misma dirección IP transmite por ambos modem entre nuestra casa u oficina hasta la central telefónica más cercana. ¿Recuerdan la redundancia de tarjetas de red en los servidores? Pues bueno, aquí es lo mismo, es una habilitación en una de las capas del modelo OSI, específicamente la capa física (de hecho cada modem en sí mismo cumple con esa capa y cada capa es independiente de las otras capas tanto por encima como por debajo).
Pues he aquí que nuestro negocio o portal educativo ha crecido y expandido en todo nuestro país, o incluso hacia el exterior , así que decidimos contratar alojamiento web en nuestro país y/o el exterior. En esos ordenadores contratados colocaremos una sincronización de archivos para que al modificar nuestros ficheros se copien, al cabo de cierto tiempo, a los servidores espejo.
Como ya tenemos configurado nuestro balanceo de carga lo único que tenemos que configurar es que se redirija hacia unas direcciones IP que no están en nuestra red de área local, sino en internet. El pequeño detalle de esta configuración estriba en que nuestro alojamiento debe ser dedicado, tal como tenemos montado en nuestra casa u oficina, si es alojamiento compartido deberemos comprar otro dominio web porque de esa manera es que sabe un servidor web compartido qué datos mostrar al visitante.
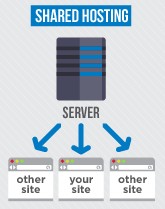
Si contratamos un servidor dedicado bien puede ser una máquina real o, lo que es más común hoy en día, una máquina virtual que igual compartiremos con otros sitios web un ordenador físico pero con varias máquinas virtuales que tendrán sus propias tarjetas de red virtuales con sus propios y únicos MAC por los cuales se podrán identificar y asignar sus propias direcciones IP fijas (esto es particularmente atractivo para cuando migremos, por fin, a las direcciones IPv6)
Pues como ya se habrán percatado, nuestra debilidad sigue siendo el «balanceador de carga»: nuestro dominio y por medio de los DNS sigue devolviendo una única dirección IP, la de nuestro ordenador en nuestra casa u oficina, ¡pues he aquí la brillante solución de los CDN!
De nuevo simplificaremos al máximo para ilustrar de manera didáctica sobre el como funciona. A nivel mundial las direcciones IP están repartidas por grandes proveedores de acceso a internet o incluso por países enteros. Acá en Venezuela CANTV tiene su rango de direcciones IP asignadas, así que para los servidores web es «facil» determinar si nuestro visitante esta conectado por medio de ese proveedor de internet, simplemente comparando la dirección IP contra los rango registrados. Pueden incluso llegar a determinar desde cual ciudad se conectan. Basado en esto:
Al comprar nosotros un alojamiento en CDN lo primero que tenemos que hacer es configurar ante quien nos vendió el nombre o dominio web y establecer los DNS de la empresa que ofrece el servicio CDN. Nuestro trabajo es seguir manteniendo nuestro «balanceador de carga» como siempre lo hemos hecho pero con privilegios especiales para que los ordenadores del CDN tengan acceso y copien nuestra página web y la distribuyan por cada una de las granjas de servidores que nombramos anteriormente.
Lo brillante de la idea de los CDN es analizar la dirección IP de un visitante de nuestra página web RECORDAD que primero tiene que pasar por los DNS del CDN para saber la dirección IP de nuestro balanceador de carga… PUES VA A SER QUE NO porque si nuestro visitante está más cerca de una granja de servidores del CDN pues le pasa esa dirección IP al visitante de una manera totalmente transparente, al fin y al cabo es una copia exacta de nuestra web lo que le va a ser retribuida al internauta.
Un asunto importante para un CDN es el poder identificar según la dirección IP recibida del webnauta de dónde viene para redirigirlo a la granja de servidores más cercana -y que contiene copia de nuestra página(s) web-. Es por ello que muchas empresas ofrecen para descargar sus bases de datos, con su respectivo «manual de uso», por ejemplo, desde MaxMind podeis visitar su página designada al respecto en este enlace. Esencialmente se resume en este comando, siempre respetando y considerando de no abusar del servicio:
wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCityv6-beta/GeoLiteCityv6.dat.gz
Dicha base de datos es utilizada por aplicaciones de seguridad para proteger servidores web de ataques maliciosos. Dado el caso que suframos un ataque masivo de denegación de servicio (millones de dispositivos al mismo tiempo visitan nuestra página web con la intención de saturarla y colapsarla) pues simplemente será repartida a lo largo y ancho del planeta. Puede darse el caso que el ataque provenga, por ejemplo, de millones de dispositivos infectados que están localizados fisicamente en Europa: pues bien las granjas de servidores ubicadas en Europa (digamos que hayan tres, una en Francia, otra en Inglaterra y otra en Italia) solo esas tres granjas de servidores serán colapsados, si es que pueden, mientras que las demás granjas en el resto del mundo mantendrán nuestra página web incólume.
Si queremos simplificar a tope podríamos decir, en una gran perspectiva, que los CDN actúan como unos «balanceadores de carga» pero a una gran medida, no sin antes realizar un arduo rabajo de sincronización de DNS y contenidos web. Esperamos les haya sido útil la información.

Muchas veces necesitamos copiar archivos de una computadora a otra de manera rápida y para ello podemos utilizar el Protocolo de Transferencia de Archivo (FTP por sus iniciales en inglés File Transfer Protocol). Pero para ellos debemos utilizar (sin importar el tipo sistema operativo en ambas máquinas) un programa servidor y un programa cliente. Para el programa servidor en esta oportunidad presentamos ProFTPD un programa de código abierto -software libre- sobre el sistema operativo GNU/Linux. Para este tutorial utilizaremos Ubuntu como máquina servidora de archivos: bajoe ste ambiente instalaremos el ProFTPD.
En 1971, mucho antes de inventarse el protocolo TCP/IP, ya había la necesidad de copiar archivos de un ordenador a otro, el problema es que ambas máquinas tenían sus propios «sistemas operativos» (eran los albores de la infomática: en realidad era un software que servía única y exclusivamente a cada modelo de máquina en particular, hoy día le decimos «firmware»). Para resolver este problema el programador indio Abhay Bhushan propuso la norma en el documento RFC 114 donde esbozó cómo hablarían las máquinas por medio de una conexión indirecta. Este método de conexión indirecta significaba que no se necesitaba un nombre de usuario o identificación (o incluso contraseña alguna) para acceder a los archivos de una computadora destinada a alojar datos (archivos).
Para aquella época la seguridad era muy simple: ¿quién tiene dinero para comprar una computadora y de paso tenerla en linea? «La nube» -como se empeñan en llamarla hoy- era muy pequeña, todos se conocían. Por ello no se pretendía ir más allá de resolver el problema de pasar datos por medio del Programa de Control de Red de trabajo (NCP por sus siglas en inglés de «Network Control Program«) la primigenia y precursora capa de red para entonces. Aquí el sr. Bhushan propuso utilizar los caracteres ASCII siguientes para controlar los paquetes al transmitirlos: SOH, STX, ETX, DC1, DC2, DC3, US, RS, GS y FS. También se definió los comandos a utilizar definidos por un solo caracter ASCII: recordad que el hardware era lentísimo y cada bit ahorrado era tiempo ganado. Esto fue un denominador común en el nacimiento de TODOS los protocolos de esa época: debido a la limitación de hardware existente MENOS ES MÁS -y cuya principal consecuencia fue el «bug» del milenio en el año 2000, pero esa es otra historia-.
"History of #FTP"https://t.co/agOVgzBb6v
— KS7000 (@ks7000) 1 de agosto de 2016
Así, por ejemplo, el comando «Retrieve» (descargar un archivo) se iniciaba con la letra «R» a lo que el servidor respondía con un «ready-to-send (rs)» enviando el caracter «>» y finalizaba de enviar el archivo con el comando «complete_file» enviando el caracter «*» (todo lo anterior «encapsulado» por los códigos STX y ETX, entre otros). Si quereís ahondar más en el uso de caracteres ASCII como «protocolo» de intercambio de información podeís hacer click en este enlace.
Ya para 1980 esta norma fue reemplazada por la RFC 765 donde soportaba los entonces nuevos protocolos TCP y TELNET (el señor Jon Postel, proponente, así aclara en la introducción donde asume el conocimiento previo de dichas normas). Además incluye una terminología donde incluye conceptos nuevos acorde con la tecnología y hardware exitentes y los comandos dejan de ser de un solo caracter a varios, iniciando así un lenguaje de alto nivel (lo comprendemos los humanos, por ejemplo, desconectarse o «logout» se enviaba un comando «QUIT«).
En 1985 de nuevo el señor Jon Postel -junto con J. Reynolds- lanza la RFC 959 donde reconoce los nuevos artefactos de computación y los define, aparte de agregar comandos opcionales como el famoso MKD -«make directory», crear un directorio- sumando funcionalidad práctica los programas clientes. Esta sigue siendo la norma vigente hoy en día y la razón de su longevidad es que es muy parecida a todas las cosas que podemos hacer hoy día por medio de una linea de comandos en nuestras propias computadoras: copiar, renombrar, mover archivos, etc.
Nota curiosa: Jon Postel es el creador de 8 servidores de dominio raíz DNS agrupados bajo la figura de Internet Assigned Numbers Authority (IANA), lo cual hizo para separarse de la ARPANET (4 servidores raíz en control del ejército de los EE.UU.) sin perder conexión nunca -ni en ningún momento- ambas redes entre sí. A pesar de sus detractores, fue una acción heróica y por represión el gobierno hizo que se detractara en sus acciones y una semana después se adueñó de la IANA -incluso la Wikipedia apunta que la fundó el gobierno lo cual no es así, el autor intelectual es Postel- y el incidente quedó registrado en el RFC 2468. Postel murió 9 meses después del asunto debido a un ataque al corazón -¿quién no se preocuparía si tu propio gobierno te reprime en tus pensamientos?- y con el pasar de los años el triunfo fue para Jon Postel: hoy la IANA es apenas un departamento de la ICANN donde los «civiles» somos en realidad quienes controlamos los nombres de dominios en internet -insisto: siguen habiendo detractores de que no tenemos ese control pero esa discusión no la detallaremos en esta entrada-.
En 1994 en la RFC 1579 se agrega se Firewall-Friendly FTP (passive mode), en 1997 se hace un enmienda para agregarle seguridad en la RFC 2228 y en 1998 en la RFC 2428 hace soporte para IPv6 y define un nuevo modo pasivo de conexión. Este modo pasivo se agrega para dar soporte a servidores FTP que están en una red de área local regida por un NAT (un enrutador utilizado para compatir una conexión a internet entre varios ordenadores o artefactos) o un «Firewall» (filtro de conexiones entrantes utilizado para evitar entradas no autorizadas en una computadora).
Pero para que conozcaís cual es la diferencia entre modo activo y modo pasivo, vamos a explicarlo corriendo el riesgo de ser demasiados simplistas -catedráticos, PhD, licenciados, etc. perdonadme por adelantado debido a lo que os voy a decir-. El esquema de conexión (conocido hoy como conexión en modo activo) es el siguiente:
En la sección anterior pudieron observar que el servidor responde con un comando numerado, 227 en el caso del comando PASV. En realidad todos los comandos que comienzan con el número 2 son comandos de respuesta exitosa y que se espera por un nuevo comando que no tiene que ver con el comando previamente enviado. El resto de las numeraciones de respuesta son las siguientes:
1XX Comando exitoso y se espera un hilo de comandos (mantener orden estricto). 2XX Comando exitoso y se esperan nuevos comandos. 3XX El comando ha sido aceptado pero necesita más datos para completarlo. 4XX El comando no se aceptó de manera temporal, se puede intentar de nuevo más tarde. 5XX El comando se negó de plano, no reintentar. 6XX Son utilizados en protocolos seguros de transferencia. X0X Errores de sintaxis o comandos superfluos. X1X Mensajes informativos. X2X Referentes a conexión. X3X Referentes a ingreso a cuentas y autenticación. X4X No especificados en la norma. X5X Referentes a sistemas de archivos.
Como podéis observar hay diversas combinaciones posibles, no obstante ya hay unos mensajes predefinidos que podéis observar en este enlace. No obstante no quiere decir que no hay más mensajes, por ejemplo Microsoft -empresa que gusta de hacer las cosas a su manera apalancados por muchísimo dinero de por medio- creó su propio mensaje no normado e identificado con el número 234 («2» comando exitoso pero «3» se necesitan más datos para acceder a la cuenta y «4» un mensaje solo para nosotros los seres humanos). Así que si creaís vuestro propio sofware libre de servidor FTP no dudéis de informar a vuestro clientes con el código 234 cuando tengan problemas para autenticarse con vosotros y se lo explicáis bien amablemente. 😉
ProFTPD nace de la necesidad de tener un software con mayor seguridad y con miras a complementar al servidor web Apache. Sus autores invirtieron mucho tiempo y esfuerzo en WU-FTPD (wuarchive-ftpd), un servidor FTP para Unix, al cual le corrigieron muchos errores de seguridad. Pronto se dieron cuenta que lo mejor era comenzar un proyecto totalmente nuevo al cual denominaron ProFTPD. Su creador fue Jesse Sipprell (hoy retirado de su desarrollodo) y es mantenido a la fecha por TJ Saunders -y su equipo-.
Teniendo nuestros repositorios bien configurados, abrimos una ventana terminal y ganamos acceso con usuario raíz root e introducimos los siguientes comandos:
apt-get update apt-get install proftpd
Veremos algo similar a esto por pantalla:
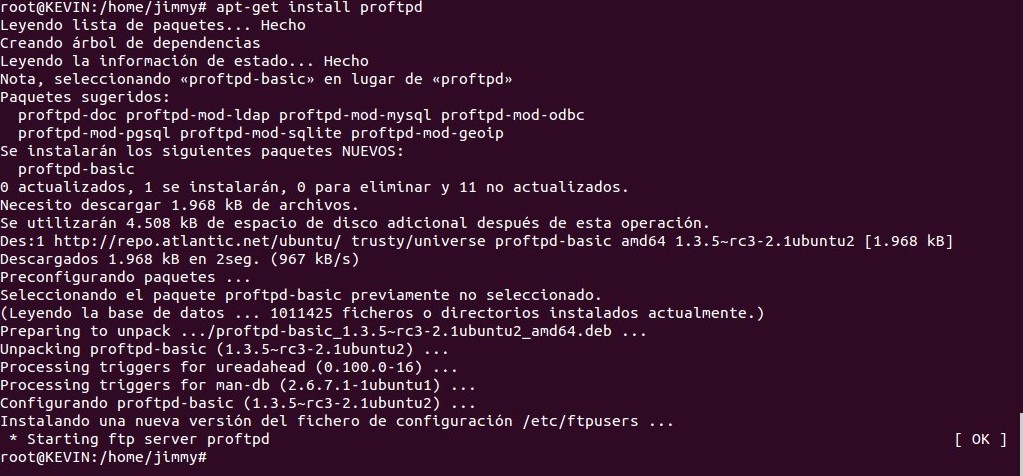
Durante su instalación nos hará una sola pregunta, si lo queremos ejecutar sobre inetd (un demonio «daemon» que escucha y recibe las solicitudes y ejecuta el programa adecuado) o si lo queremos ejecutar de manera completa «standalone«. La decisión en este caso depende de si queremos descargar archivos de vez en cuando o si queremos un servir múltiples conexiones. Con la capacidad de hardware de hoy en día el cual es más que suficiente para la mayoría de los usuarios, de manera predeterminada está seleccionada la opción «standalone«.
Y listo ¿A que fue fácil, verdad o no? Ahora para probarlo nos podemos conectar desde cualquier otro ordenador o dispositivo en nuestra red de área local con la dirección IP del servidor y con nuestro nombre de usuario -y contraseña- en nuestra distribución Ubuntu. Por defecto, todos los usuarios registrados en el sistema operativos del servidor tienen acceso vía ftp. Desde cualquier distribución GNU/Linux podemos conectarnos rápidamente por medio de la linea de comandos gracias a la utilidad ftp desarrollada para Unix en 4.2 BSD, acá ponemos una captura de pantalla hecha en Debian:
Una vez probado os daréis cuenta que ProFTPD honra sobradamente los deseos del señor Abhay Bhushan. Aunque no podemos conectarnos de manera indirecta podemos habilitar la conexión anónima a nuestro servidor de la siguiente manera: se acostumbra utilizar como nombre de usuario la palabra anónimo en inglés «anonymous» y como contraseña nuestro correo electrónico con las restricciones de solo lectura en todos los directorios disponibles y como solo escritura en la carpeta «incoming». Para ello debemos modificar al archivo «/etc/proftpd/proftpd.conf». Primero debemos respaldar dicho archivo por asia caso cometemos cualqueir error podremos restaurar rapidamente los valores:
cp /etc/proftpd/proftpd.conf /etc/proftpd/proftpd.conf.bak nano /etc/proftpd/proftpd.conf
E introducimos el contenido siguiente, tal como aconsejan en la propia página web de ProFTPD:
<Anonymous /home/ftp> # After anonymous login, daemon runs as user/group ftp. User ftp Group ftp # The client login 'anonymous' is aliased to the "real" user 'ftp'. UserAlias anonymous ftp # Deny write operations to all directories, except for 'incoming' where # 'STOR' is allowed (but 'READ' operations are prohibited) <Directory *> <Limit WRITE> DenyAll </Limit> </Directory> <Directory incoming> <Limit READ > DenyAll </Limit> <Limit STOR> AllowAll </Limit> </Directory> </Anonymous>
Luego ejecutamos el reinicio del servicio ftp:
sudo service proftpd restart
Unav vez reiniciado el servicio procedemos a comprobar de nuevo la conexión.
También es aconsejable cambiar, según nuestras necesidades, los siguientes parámetros de igual manera como acabamos de hacer con las conexiones anónimas:



Pues que con los bajos precios del petróleo aquí en Venezuela tenemos una fuerte crisis económica y apenas hemos podido pagar el alojamiento de esta vuestra página web -humilde sitio- y hemos estado alejados de la escritura. En la década de los 90 nos sucedió igual -duramos una semana comiendo sólo arroz- pero es de grata recordación una película que vimos en esa época sobre «El Diario de Ana Frank» -transmitida por una televisora llamada «Niños Cantores«- y que nos recuerda que podríamos estar mucho peor –mal de muchos, consuelo de tontos-. Pero lo cierto del caso es que el libro se escribió y existe, y es una prueba de la perseverancia y esperanza de la humanidad.
Por ello decidimos seguir preparándonos para el futuro, ya vendrán días de sol luego de estos días de lluvia -y hasta de tormenta- SEGUIMOS, NO NOS DETENEMOS. Retomamos, entonces, el tema de la informática desde sus bases, y algo que desde que estamos conectados a internet y aún usamos día a día es el «Internet Protoco version 4» o, por su acrónimo en inglés, IPv4. Simplemente el IPv6 viene a ser el sucesor (¡ea, que nos han volado la versión 5!) y para decirlo en forma llana, pues viene a proporcionarnos, prácticamente, direcciones IP infinitas, es decir, números de identificación exclusivas para cada adaptador de red (que eso ya lo sabéis, por ejemplo es bastante común que cada ordenador portátil tenga hoy en día al menos 2 maneras de conectar al internet: por ethernet o por WI-FI) pues cada uno de ellos tiene una dirección IP independendiente (luego veremos que esto no necesariamente así en IPv6).
Vint Cerf, «Evangelista» en Jefe en la empresa Google, y uno de los fundadores del internet, expone la próxima versión del internet, IPv6, y por qué la necesitamos.
Cuando el internet fue puesto en práctica en 1983, nadie nunca soñó que habrían millardos de dispositivos y usuarios intentando estar en línea. Pero así como una red de telefonía se queda sin números telefónicos para sus abonado, el internetactual se quedó sin direcciones IP en 2013, y si no implementamos el Protocolo de Internet v6 (IPv6), no tendremos el espacio que necesitemos para que el internet crezca y esto podría liarlo, hacerlo inseguro e insustentable.
En el vídeo el señor Cerf nos explica con mayores detalles, usad los subtítulos generados en castellano (spanish) si es necesario:
Allí tenéis, pues, los enlaces PUROS Y DUROS hacia los conceptos, eso os llevará bastante tiempo analizar y asimilar o en el caso de los más avezados, recordar.
Debemos aprovechar el uso de la tecnología al máximo, es por ello que encontré esta exposición en Youtube, cortesía de «el maligno Alonso» (no nos asustéis, no tiene nada que ver con religión) y describe de la siguiente manera:
Conferencia de Rafael Sánchez (@r_a_ff_a_e_ll_o) de Eleven Paths sobre cómo montar un escenario de hacking IPv6 en Internet con un VPS y túneles IPv4/IPv6. Más información sobre esta sesión en esta URL.
Sin más aquí os dejo el vídeo, que va de lo más básico (una muy buena introducción a los conceptos y «bien machacado») hasta lo más avanzado ( IPv6 dentro túnel VPS con IPv4, máquinas virtuales, Kali Linux, nmap, etc.) que es, como dicen ellos allá «para flipar» (aquí decimos «tripear» del inglés «to trip», viajar o «elevarse»):
Podemos destacar los siguientes datos de la conferencia:
Podemos comenzar con esa abrumadora cifra: podemos asignar 100 direcciones IPv6 a cada átomo en la Tierra, al haber tanta oferta el «negocio» de las direcciones IP fijas o estáticas caerán a costo cero, ¡imaginamos!
Did you know there are 100 IP addresses for every atom on Earth with IPv6? https://t.co/Q7q7fsBxxK #FunfactFriday pic.twitter.com/KJnUKNA8Ks
— Planetech USA (@PlanetechUSA) 15 de abril de 2016
Aquí ampliaremos sobre el tema (en construcción).
<Eso es todo, por ahora>.

«Let’s Encrypt» es un proyecto de la «Electronic Frontier Foundation» en colaboración con la «Linux Foundation» para promover uso del protocolo HTTPS.
For english speakers: this is a merely translation into castilian language of an article year ago published by «Electronic Frontier Foundation» (also known as EFF acronym) where it announces the starting project «Let’s Encrypt».
{kind=link}