
Suena incoherente: usamos curl en nuestra línea de comandos frecuentemente para diversidad de tareas pero no sabíamos que el lenguaje PHP tiene su propia versión llamada, cómo no, curl. El asunto es cómo se implementa y qué podemos hacer, nosotros en la línea de comandos lo acompañamos en el trabajo con grep pero en PHP la cosa es un poco diferente, ¡vamos a averiguar cómo!
Tabla de contenido:
- 1 Introducción.
- 2 PHP curl.
- 2.1 Nuestro primer ejemplo práctico.
- 2.2 Nuestro primer ejemplo práctico pero mejorado.
- 2.3 Guardando el resultado en una «variable aparte».
- 2.4 Guardando el resultado en un archivo.
- 2.5 Probando otros protocolos: FTP.
- 2.6 Pasando valores por medio del método POST.
- 2.7 Ejecutando PHP curl en modo de depuración.
- 2.8 Otros usos para PHP curl.
- 2.9 curl_setopt(): parámetros mas socorridos.
- 3 Función curl_setopt_array.
- 4 Analizando los resultados de la última conexión.
- 5 Futuro de cURL.
- 6 Resumen.
- 7 Actualizado el sábado 27 de enero de 2018.
- 8 Fuentes consultadas.
Introducción.
Exactamente cómo implementaron cURL en PHP no lo sabemos, tal vez PHP haga llamado directo al curl y recoja sus resultados, sirviendo entonces como intermediario solamente… No tiene sentido pero si analizamos que muchos sitios web compartidos con otros dominios tienen PHP pero a uno no lo dejan ingresar por la línea de comandos entonces ¡vaya que si vale la pena el trabajo intermedio!
Por otra parte puede ser que especulamos demasiado y los buenos desarrolladores de PHP tienen su propia versión… ¡pero recordad que trabajamos con Software Libre que permite la modificación y reutilización del código! Pero echemos una leve ojeada al comando curl.
Comando curl.
Ya sabemos como va es esto del software libre: hay más de 1400 colaboradores en curl y el proyecto está alojado en GitHub desde el año 2010; aceptan contribuciones bajo la forma de «pull requests»: en resumen uno copia y trabaja con esa copia privada modificandola -y mejorandola, por supuesto- y devolviendo el trabajo al original para su aprobación. No se garantiza que se acepte toda la propuesta, e incluso ellos podrán tomar ciertas cosas propuestas y otras no, o en el mejor de los casos todo vaya bien y nos convirtamos en el colaborador 1401… y así haremos nuestra contribución al Patrimonio Tecnológico de la Humanidad.
Construyendo el Patrimonio Tecnológico de la humanidad @Obijuan_cube @MakerFaireBio pic.twitter.com/sZ38MnINKA
— Carlos Lizarbe (@jclizarbe) 18 de noviembre de 2016
Pero ¿quiénes desarrollan curl? Daniel Stenberg -sueco, habitante de Estocolmo- es el principal desarrollador y comenzó el proyecto por allá en 1996 basado en el trabajo de un programador brasileño llamado Rafael Sagula. Esta sencilla herramienta herramienta carioca fue bautizada como httpget con unas cuantas centenares de líneas y Stenberg las amplió para liberarla en 1997 con el nuevo nombre de «HTTP proxy support». Pero con el advenimiento de «nuevos» protocolos al proyecto tales como GOPHER y FTP pronto dejó de tomar sentido llamarlo solamente «HTTP»… así que ese mismo año vio la luz la versión número dos.
Para 1998 más protocolos y capacidades fueron agregados así que volvió a cambiar de nombre para la versión 4.0 -manteniendo la numeración de versiones- así que el 20 de marzo de ese año marca el nacimiento formal de curl. El nuevo nombre hace alusión al programa del lado del cliente, de allí la letra «c» inicial. Las otras tres letras os lo podéis imaginar ya: Uniform Resource Locator -URL- o Localizador de Recursos Normalizados.
El mismo Stenberg reconoce que hay muchos proyectos con el mismo nombre curl pero para la época que ellos lanzaron la versión cuatro no había (o conocían) de otros proyectos con el mismo nombre. Es por ello que nosotros al principio especulamos del origen de curl en el lenguaje PHP, pero es que ¡Incluso existe un curl desarrollado en software privativo! (no le haremos publicidad pues no nos pagan por ello, buscadlo vosotros mismos con DuckDuckGo). Tan famoso es que ya se considera como verbo en idioma inglés y muchos creen que es un protocolo pues lo tratan como tal pero ya sabemos que en realidad es una navaja suiza con muchísimas funciones.
curl para la línea de comandos.
En principio el comando curl fue desarrollado para scripts ya que sus entradas y salidas utilizan las ya famosas stdin y stdout. No ampliaremos más porque en este blog hallaréis información sobre su uso con la línea de comandos. El artículo que motivó la publicación de esta entrada está en el siguiente «tuit» y precisamente es para la línea de comandos -y pretendemos que corra en PHP curl-:
También hemos recopilado con el paso del tiempo otros usos notables del curl en la línea de comandos:
Como averiguar la web destino de una URL acortada con #curl:https://t.co/apzHrUsmBW via @LinuxGnuBlog
— ks7000.net.ve💾🇻🇪😷🏡 (@ks7000) 15 de abril de 2017
curl para su uso como librería.
A partir del año 2000 fueron desarrolladas, o mejor dicho, el código existente fue migrado completamente como librerías y a partir de allí se le hizo una interfaz de usuario para la línea de comandos. Está escrito en lenguaje C y aún hoy en día dichas bases siguen sustentando el proyecto con la ventaja que se puede reutilizar en otros proyectos y compilarlos todos juntos. Seguimos sospechando que precisamente eso hicieron en PHP pero esa es nuestra humilde opinión que como reafirmamos: en software libre este comportamiento es un honor a su filosofía de desarrollo: ejecutar, estudiar, distribuir, mejorar y redistribuir.
Versiones actuales y desarrolladores estrellas.
Nosotros en nuestro GNU/Linux Ubuntu 16 tenemos instalada la versión 7.40.00 pero en realidad la última versión estable es la 7.54.0.
Si bien son muchísimos los colaboradores, es justo mencionar los que más han contribuido en los últimos años de una manera marcada y constante:
- Daniel Stenberg.
- Steve Holme.
- Jay Satiro.
- Dan Fandrich.
- Marc Hörsken.
- Kamil Dudka.
- Alessandro Ghedini.
- Yang Tse.
- Günter Knauf.
- Tatsuhiro Tsujikawa.
- Patrick Monnerat.
- Nick Zitzmann.
Disipación de toda duda.
En este punto de nuestra investigación nuestras sospechas se hacen realidad: uno de los primero lenguajes en adoptar la librería curl es precisamente PHP el cual motoriza un 25% de las páginas web a nivel mundial. El extracto , en inglés, reposa en el libro electrónico -liberado con licencia «Creative Commons»- «Everything about curl«:
The libcurl binding for PHP was one of, if not the, first bindings for libcurl to really catch on and get used widely. It quickly got adopted as a default way for PHP users to transfer data and as it has now been in that position for over a decade and PHP has turned out to be a fairly popular technology on the Internet (recent numbers indicated that something like a quarter of all sites on the Internet uses PHP).
A few really high-demand sites are using PHP and are using libcurl in the backend. Facebook and Yahoo are two such sites.
La traducción hecha por nosotros al idioma castellano:
El software de enlace (librerías) de curl para PHP fue uno, cuidado sino, el primero de los enlaces que realmente captura y lo usa ampliamente. Rápidamente fue adoptado como una manera por defecto para transferir datos y se ha mantenido en esa posición por más de una década mientras tque PHP se ha convertido en una tecnología bastante popular en internet (cifras recientes indican que algo asó como una cuarta parte de todos los sitios web en internet utilizan PHP).
Realmente unos pocos sitios web de alta demanda están usando PHP acompañado de las librerías de enlace de curl corriendo entre bamabalinas. Facebook y Yahoo son dos de tales sitios.
Protocolos soportados por curl.
HTTP, HTTPS, FTP, FTPS, GOPHER, TFTP, SCP, SFTP, SMB, TELNET, DICT, LDAP, LDAPS, FILE, IMAP, SMTP, POP3, RTSP y RTMP (esos son todos, por ahora -y vienen más, no se detiene el proyecto-).
PHP curl.
Ahora si que pasamos a hablar del software que nos ocupa en este vuestro sitio web de compartición del conocimiento. Como ya hemos hablado bastante de historia y teoría pasamos directamente a describir cómo trabajar con PHP curl:
- Inicializar curl con curl_init().
- Pasarle los parámetros – esencial es la URL – con curl_setopt().
- Retribuir y mostrar -o guardar- con curl_exec().
- Cerrar y liberar recursos con curl_close().
Nuestro primer ejemplo práctico.
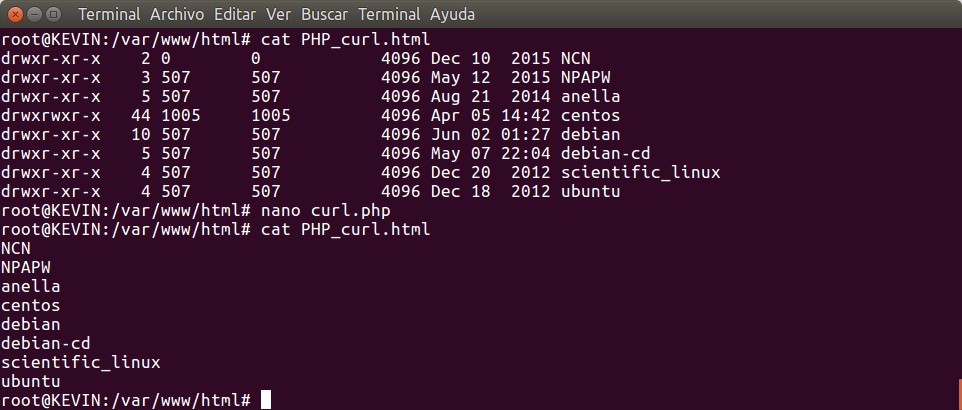
Lo siguiente que haremos es abrir una ventana terminal, tomar nuestro editor de texto favorito y escribir el siguiente código para ser guardado en un archivo que llamaremos php_curl.php:
[cc lang=»php» tab_size=»2″ lines=»80
[/cc]
Por supuesto, llamad vuestro archivo como queráis, guardadlo en vuestra carpeta donde ejecute vuestro servidor PHP y dadle los permisos de lectura y ejecución necesarios. En la primera línea inicializamos, en la segunda línea le pasamos la dirección web deseada -un dominio que devuelve nuestra dirección IP asignada por nuestro ISP-, en la tercera línea lo ejecutamos y en la cuarta línea cerramos y liberamos recursos. Una explicación más detallada a continuación.
Inicialización.
Debemos crear una instancia y guardarla para futuras referencias, este objeto basado en curl nosotros lo llamamos $objCurl y este nombre es el que debemos pasar a los otros comandos. El comando curl_init() solamente acepta un parámetro, la URL que es un dato imprescindible, tal vez debido a ser tan importante fue el único que establecieron en este comando. Aunque en el ejemplo no lo colocamos por razones didácticas, de ahora en adelante «para que no se nos olvide» lo estableceremos siempre en la primera línea del script o guion del programa.
Configuración.
Este es el comando más denso, notad que le damos el nombre de configuración porque su nombre así lo sugiere: curl_setopt(), osea «setopt» -> «set options». Acepta tres parámetros, separados por comas:
- Primero debemos indicarle el objeto que contiene la inicialización de curl, en nuestro caso la variable $objCurl.
- Segundo le pasaremos el tipo de valor que le pasaremos en el tercer parámetro, en nuestro caso la URL y la constante que lo define -nombrada de manera nemotécnica- es CURLOPT_URL.
- El tercer parámetro es el valor en sí mismo de lo que indicamos en el segundo parámetro.
Debemos indicaros que usamos una sola línea para configurar, pero pronto veremos que esta parte es la más abultada por la infinidad de datos y tipos de datos que podemos pasar. Es mejor que vayaís preparando para aprender que esta sección siempre será multilínea y que debemos indentarla y escribirla lo más explícito posible para corregir a futuro de forma fácil nuestro código.
Ejecución.
Simplemente le decimos a PHP que hemos terminado de establecer lo que queremos obtener –o lo que queremos enviar, ya veremos más adelante- y acepta un parámetro que sigue siendo el objeto que hemos creado y configurado. En este punto ya os recordaremos que estamos trabajando con funciones y este comando devuelve verdadero o falso para indicar si tuvo éxito (para comparar la respuesta usaremos siempre «==» para estar seguros del tipo de variable y el resultado obtenido). En el ejemplo no colocamos ninguna variable que reciba el resultado del que hablamos como función ¿dónde está lo que nos interesa? En realidad el valor numérico (verdadero o falso) es lo que podemos guardar en una variable, el resto del resultados se va al stdout y eso será lo que enviaremos al navegador web que solicitó nuestro primer guión PHP sobre curl. Debido a esto recibiremos el mismo código HTML de la página que estamos solicitando (pero con los enlaces web absolutos cambiados).
Si probáis con descargar diferentes páginas, unas funcionarán, otras no, todo depende de si la página es estática, dinámica, si tiene JavaScript, en fin, cantidad de cosas que pueden NO ser compatibles con PHP curl: por eso debemos aprender las muchísimas opciones de configuración que nos sean útil en cada trabajo que se nos presente para ganarnos así el pan nuestro de cada día como Dios manda.
Liberación de recursos.
Os podrá sonar que nos contradecimos con lo siguiente: la función curl_close() se encarga de cerrar, como su nombre indica pero no devuelve resultado acerca del trabajo que le mandamos a realizar. Consideramos que esto es un «bug» porque a la hora de detectar dónde fugan recursos en nuestro servidor deberemos recurrir a otras herramientas apartes de PHP, pudiendo ser evitado esto con una sencilla rutina de nuestra parte e indicar que está sucediendo y qué está mal. Ah, perdón, casi lo olvidamos: el parámetro único que acepta es el objeto que creamos -y queremos destruir- con curl_init().
Nuestro primer ejemplo práctico pero mejorado.
Un sencillísima rutina de control de errores nos puede ahorrar muchísimos dolores de cabeza.
Nota: hay mejores métodos para el manejo de excepciones, pero aprendamos poco a poco. Ah, y nosotros lo llamamos «control de errores» y eso tampoco es el nombre correcto (excepciones) pero así nos abstraemos.
Por ello reescribiremos nuestro ejemplo pero con condicionales if~else:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»]
$objCurl = curl_init(«http://www.soporteweb.com/»);
if ($objCurl == true) {
$resul = curl_exec ($objCurl);
if ($resul == true){
curl_close ($objCurl);
} else {
echo «No se pudo ejecutar PHP curl
«;
}
} else {
echo «No se pudo inicializar PHP curl.
«;
}
?>[/cc]
Notad que pasamos de una buena vez el URL en en el inicio con curl_init(). Además guardamos el valor del resultado en una variable, evaluamos el valor que tiene y ejecutamos o mostramos un mensaje apropiado según la respuesta obtenida. Muchos programadores y programadoras piensan que hacer nuestro software de esta manera, aparte de ayudarnos a nosotros mismo, abre las puertas a los hackers cuando se presentan excepciones -o errores, como les llamamos- porque «develan mucho». Ese razonamiento es válido en el software privativo pero en el software libre no tiene asidero alguno porque cualquier hacker tiene acceso al código fuente, así que hagamos la depuración fácil para nosotros mismos.
Guardando el resultado en una «variable aparte».
Como explicamos PHP curl envía al stdout la respuesta y asu vez eso lo pasamos al navegador, ¿qué tal si analizamos primero lo que recibimos y luego lo reenviamos? Por ejemplo, podríamos «acomodar» los enlaces absolutos de las imágenes que contiene la página web que llamamos (URL). Para ello vamos a emplear culr_setopt() con CURLOPT_RETURNTRANSFER establecido en el valor 1, mirad:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»] $objCurl = curl_init(«http://www.soporteweb.com»);
if ($objCurl == true) {
curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1);
$resul = curl_exec ($objCurl);
if ($resul == true){
curl_close ($objCurl);
print «Nuestra direccion IP es: «;
print $resul;
} else {
echo «No se pudo ejecutar PHP curl
«;
}
} else {
echo «No se pudo inicializar PHP curl.
«;
}
?>[/cc]
Y así «manipulamos» el resultado con el texto que coloreamos en verde; ahora vamos un paso más allá. 😎
Guardando el resultado en un archivo.
Aunque ya tengamos el resultado deseado en una «variable» supongamos que estamos creando un robot (o bot como los mientan ahora en este siglo) y queremos guardar el resultado en un archivo ¿qué tiene que ver PHP curl con esto si ya sabemos el lenguaje PHP y sabemos como hacerlo aparte?
Pues resulta que con CURLOPT_FILE en curl_setopt() permite guardarlo en un archivo, pero antes tenemos que abrir el archivo y pasarle la «referencia» a PHP curl:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»] $objCurl = curl_init(«http://www.soporteweb.com/»);
if ($objCurl == false) {
print «No se pudo inicializar PHP curl.
«;
} else {
$nom_arch = ‘PHP_curl.html’;
$arch = fopen( $nom_arch , «w»);
if ($arch == false ) {
print «No se pudo abrir el archivo ‘».$nom_arch.»‘
«;
curl_close ($objCurl);
} else {
$resp = curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1);
if ( $resp == false ) {
print «No se pudo establecer CURLOPT_RETURNTRANSFER.
«;
curl_close ($objCurl);
} else {
$resp = curl_setopt ($objCurl, CURLOPT_FILE, $arch);
if ( $resp == false ) {
print «No se pudo establecer CURLOPT_FILE.
«;
curl_close ($objCurl);
} else {
$resul = curl_exec ($objCurl);
if ($resul == false) {
echo «No se pudo ejecutar PHP curl.
«;
} else {
print «El archivo fue guardado con el nombre ‘PHP_curl.html’.
«;
// curl_close NO devuelve resultado:
curl_close ($objCurl);
}
}
}
}
}
?>[/cc]
Si tenéis problemas para escribir el archivo en disco REVISAD vuestros derechos de escritura para PHP especialmente para el grupo «www-data».
Así de sencillo, con las correspondientes rutinas de depuración para nosotros. Como tal vez se vea un poco largo hemos coloreado las partes importantes para que sigáis el hilo. ¿Que por qué nos hemos ido por la negación siempre de primero? Pues revisando la función fopen() verificamos que si es exitosa devuelve una referencia al archivo más no un valor de tipo booleno -verdadero-. En cambio si falla la función siempre devuelve un valor boleano falso. Lo de seguir usando la negación por defecto es para llevar el mismo estilo parejo al resto del código.
Mejorando la claridad de la sintaxis con ayuda de exit().
Una función «vieja» en PHP es la función die() que es totalmente equivalente a exit() que es más «elegante». El chiste del asunto es emplear la conjunción or (operador lógico «o») para unir la acción que queremos realizar con la función exit(). Dicha función permite como parámetro una cadena de texto o un entero entre cero y 254 (el 255 está reservado para uso exclusivo de PHP). Nos gusta mejor la opción de pasarle una cadena de texto con el mensaje que queremos presentar al usuario ¡o a nosotros mismos!
Otro punto importante es que la función exit() aparte de mostrar mensaje y cerrar adecuadamente los objetos en memoria es que sale inmediatamente y no ejecuta el resto de las líneas que quedan a partir de su llamada.
Veamos entonces cómo emplearlo en nuestra labor que hoy nos ocupa (para no alargar tanto cada línea fijaos el uso del punto y coma para separar bloques de código multilíneas):
$objCurl = curl_init("http://www.soporteweb.com/")
or exit("No se pudo inicializar PHP curl.
");
$nom_arch = ‘PHP_curl.html’;
$arch = fopen( $nom_arch , «w»)
or exit(«No se pudo abrir el archivo ‘».$nom_arch.»‘
«);
curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1)
or exit(«No se pudo establecer CURLOPT_RETURNTRANSFER.
«);
curl_setopt ($objCurl, CURLOPT_FILE, $arch)
or exit(«No se pudo establecer CURLOPT_FILE.
«);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
print «El archivo fue guardado con el nombre ‘PHP_curl.html’.
«;
// curl_close NO devuelve resultado:
curl_close ($objCurl);
?>[/cc]
¡Qué gran mejora en la legibilidad! Debemos aclarar que exit() de manera implícita llama a los procedimientos de cierre y liberación de recursos de memoria (destructor lo nombran en lenguaje C++) así que como ven es una vía muy pragmática para nuestros propósitos.
Si queréis probar como funciona la rutina con control de excepciones, colocad una dirección web que no exista y mirad que sucede, ¡experimentad! También os recomendamos probar otros protocolos, por ejemplo FTP en un servidor público como por ejemplo «ftp://ftp.cesca.es/» donde veremos un listado de archivos disponibles para ser descargados.
Probando otros protocolos: FTP.
En el párrafo anterior os sugerimos probar el protocolo FTP y no hubo nada que cambiar en el código que teníamos -aparte de la URL, por supuesto-. Pero PHP curl tiene sus opciones y a continuación pasamos a revisar alguna de ellas. La primera que revisaremos limita el listado obtenido de archivos y directorios, osea, no muestra los permisos de cada uno de ellos. La sintaxis en el comando curl_setopt() -y todas las opciones utilizan esta función- es la siguiente:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»]curl_setopt($objCurl, CURLOPT_FTPLISTONLY, 1)[/cc]
or exit("No se pudo establecer CURLOPT_FTPLISTONLY");
Si el servidor FTP no fuera público o exigiera una conexión tipo anónimo usaremos esto:
curl_setopt($objCurl, CURLOPT_USERPWD, "anonimo:su@correo-e.com")
or exit("No se pudo establecer CURLOPT_USERPWD");[/cc]
Con esta novedad de introducir credenciales de conexión nos encontramos con otro tipo de manejo de excepciones: dado el caso las credenciales no funcionen (mala escritura, contraseña vencida, usuario inexistente, etc) dentro del obejto PHP curl se guardará en una instancia aparte el resultado del intento de conexión, para ellos contamos con:
[cc lang="php" tab_size="2" lines="80" widht="10%"] echo curl_error($objCurl);[/cc]
https://twitter.com/souzace/status/868869012414840832
Pasando valores por medio del método POST.
Finalmente llegamos al meollo del asunto: poder pasar a un servidor web una o más variables por medio del método POST a un servidor web. Para propósitos de aprendizaje diremos que es uno de los métodos más populares debido a su cierta privacidad ya que el usuario no puede ver el enlace como en el método GET y tampoco es «cacheable» por los navegadores web.
Primero haremos una rchivo que nos muestre todas las variables que reciba y las liste por pantalla, de manera increíble solo necesita una sola líneas de código (guardar con el nombre de «curl_post.php«):
var_dump($_POST);
?>[/cc]
Una vez tengamos este archivo ya sea en nuestro servidor local o en nuestro servidor remoto podremos comenzar a escribir el siguiente script:
$objCurl = curl_init("http://localhost/curl_post.php")
or exit("No se pudo inicializar PHP curl
");
curl_setopt($objCurl, CURLOPT_POST, 1)
or exit(«No se pudo establecer CURLOPT_POST»);
//Pasamos las variables que nos interesan al servidor
curl_setopt($objCurl, CURLOPT_POSTFIELDS, «var1=uno&var2=dos&var3=tres»)
or exit(«No se pudieron establecer las variables en CURLOPT_POSTFIELDS»);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.»);
curl_close ($curl);
?>[/cc]
Debido a los mensaje que incluimos en cada exit() y con el coloreado del código no hay nada que explicar… excepto unas cuantas acotaciones:
- Las variables que pasamos en el método POST deben estar por pares unidas con el ampersand y separadas por medio de un signo de igualdad.
- Los espacios no se permiten, debemos pasar «%20» o mejor dicho debemos darle un formato especial antes de enviarlo. El comando que nos ayudará será urlencode() y para nosotros castellanohablantes es importante representar bien los acentos, etc.
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»] //Pasamos las variables que nos interesan al servidor
$var_post = urlencode(«var1=Venezuela&var2=América del Sur&var3=Güigüe»);
curl_setopt($objCurl, CURLOPT_POSTFIELDS, $var_post)
or exit(«No se pudieron establecer las variables en CURLOPT_POSTFIELDS»);[/cc]
Fuera de tema: «Tamper data for Mozilla Firefox».
Adam Judson es un desarrollador que tiene -nos tiene- como usuarios a más de 80 mil personas en su trabajo de programación desde el año 2007. Él desarrolló «Tamper Data» para este popular navegador, una herramienta para, según sus propias palabras «pruebas de seguridad en aplicaciones web por medio de la modificación de los parámetros POST».
Dicha herramienta la podemos instalar en nuestro navegador (requiere reinicio del navegador y no es compatible con «Google Web Accelerator») y con ella podremos visitar cualquier sitio web que utilize envio de datos POST y al activarlo en una ventana aparte mostrará sin molestar ni influir en nada el tráfico saliente de nuestro ordenador por medio de nuestro navegador web Firefox. ¿Por qué anuncia pruebas de seguridad? Porque nosotros muy bien sabemos como programadores que el código fuente de nuestras aplicaciones web están a la vista de los usuarios ¿pero que tal lo que no se ve? Pues acá entra «Tamper Data»: por más que coloquemos validación HTML5 y JavaScript del lado del cliente, si no utilizamos HTTPS el tráfico entre el usuario y nuestro servidor puede ser modificado por terceros. Y aunque si usaramos HTTPS tampoco podemos confiarnos de nuestros usuarios, verbigracia la misma herramienta que estamos recomendando puede modificar los datos si en la venta que se nos abre hacemos click en «modificar». Al activar este botón, cuando sale algo de nuestro ordenador nos pregunta si deseamos modificar algún dato, ¡y allí podremos echar por tierra toda la hermosa programación hecha en HTML5 y javaScript!
Este comentario es «fuera de tema»: para combatir esto último lo que debemos hacer es, en lenguaje PHP -o vuestro lenguaje utilizado- volver a validar los datos recibidos desde el usuario, ¡PERO HAY MÁS! Es obligatorio agregar «disparadores» y «restricciones» incrustados en nuestra base de datos (recomendamos PostgreSQL por su capacidad de incluso aceptar guiones en lenguaje Python) para volver a validar datos al agregar los datos a nuestro motor informático. Más detalles escapan de esta entrada, pero este resumen es el mejor que podemos expresar al respecto.
Ejecutando PHP curl en modo de depuración.
«Verbose» en idioma inglés describe un modo de hablar más de lo necesario. Pero en nuestro mundo del software libre nuestra búsqueda del conocimiento es insaciable, «solo sabemos que no sabemos nada» por ello le dedicamos esta sección empinada a ahondar en PHP curl. Aparte de aprender más y mantener nuestro cerebro haciendo ejercicios, debido a la gran cantidad de protocolos y opciones es sumamente fácil para nosotros el cometer errores solicitando opciones inexistentes o incompatibles entre ellas, si son varios los parámetros que les pasemos.
Para activar el modo de depuración -vamos que la traducción al castellano de «verboso» no cuela- en PHP curl echamos mano de la alternativa CURLOPT_VERBOSE en la ya consabida función curl_opt() ¡pero esperen -como dice el «infomercial» de T.V.- hay más! PHP curl, dijimos, lo tenemos claro, emplea stdin y stdout que son los más conocidos pero también utiliza stderr ¡para algo que no es error, sino DEPURACIÓN! Teoricamente no debería ser pero en la práctica, el mundo real esto es de facto que lo hacen -y haremos-: capturar el stderr para llevar los mensajes de depuración hacia un archivo de escritura y de adición. Este archivo si no está creado, lo hace, y lo abre para agregar dichos datos y si existe le adiciona al final, de tal manera que llevamos una especie de bitácora para nuestro estudio y control.
$ObjCurl = curl_init()
or exit("No se pudo inicializar PHP curl.
");
curl_setopt ($ObjCurl, CURLOPT_URL, «http://www.soporteweb.com»)
or exit(«No se pudo establecer la URL.
«);
curl_setopt($ObjCurl, CURLOPT_VERBOSE, 1)
or exit(«No se pudo establecer el modo de depuración.
«);
$verbose_arch = fopen(‘verbose.txt’, ‘a’);
curl_setopt($ObjCurl, CURLOPT_STDERR, $verbose_arch)
or exit(«No se pudo establecer CURLOPT_STDERR
.»);
curl_exec ($ObjCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
curl_close ($ObjCurl);
?>[/cc]
Y veremos algo parecido a esto:
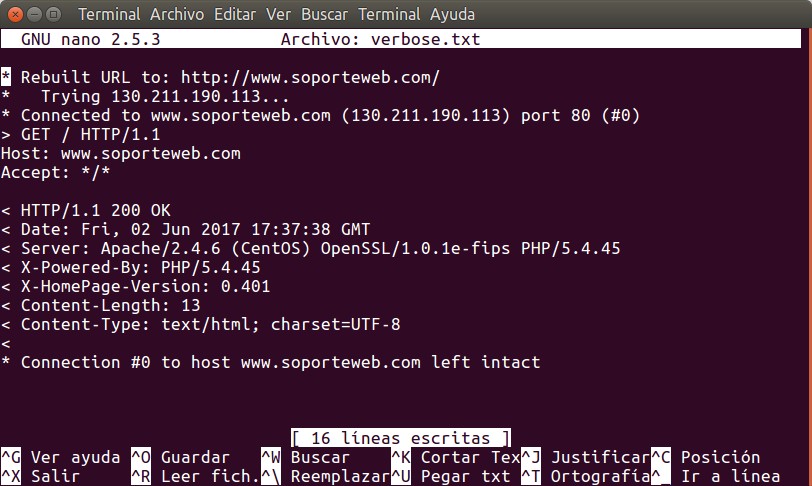
Explicamos que:
- Las líneas que comienza con un asterisco son mensajes informativos de PHP curl.
- Las líneas que comienzan con «>» es información que se le envia al servidor web, ftp, etc.
- Las líneas que comienzan con «<» es la información que recibimos de tal servidor.
- Los servidores web basados en ASP.NET devolverán un error «HTTP/1.1 500 Internal Server Error» y no podremos hacer nada ya que no se rigen por las normas comunes basadas en RFC y recomendaciones de WWW.
Otros usos para PHP curl.
Por nuestros experimentos vimos que PHP curl permite grabar en archivos «flujos de datos» de una manera básica, sin estar amarrado a protocolos (si lo usamos con FTP veremos que nos hacen falta los comandos populares y que solo podremos usar si tenemos un cliente FTP como tal). Eso deja abierta la posiblidad a darle infinidad de usos sin siquiera saber -ni preocuparnos- «con quien estamos hablando». Un ejemplo de ello es con el acceso a servidores con tecnología ASP.NET o la mismisa consulta de nuestra dirección IP que devuelve un resultado no normalizado ni con metadato alguno (solo nosotros, seres humanos, estamos con la plena certeza que es una dirección IPv4).
Por ejemplo, si en vez de usar soporteweb.com para retribuir nuestra dirección IPv4 usamos el servicio que presta icanhazip.com en el modo de depuración veremos algo como esto:
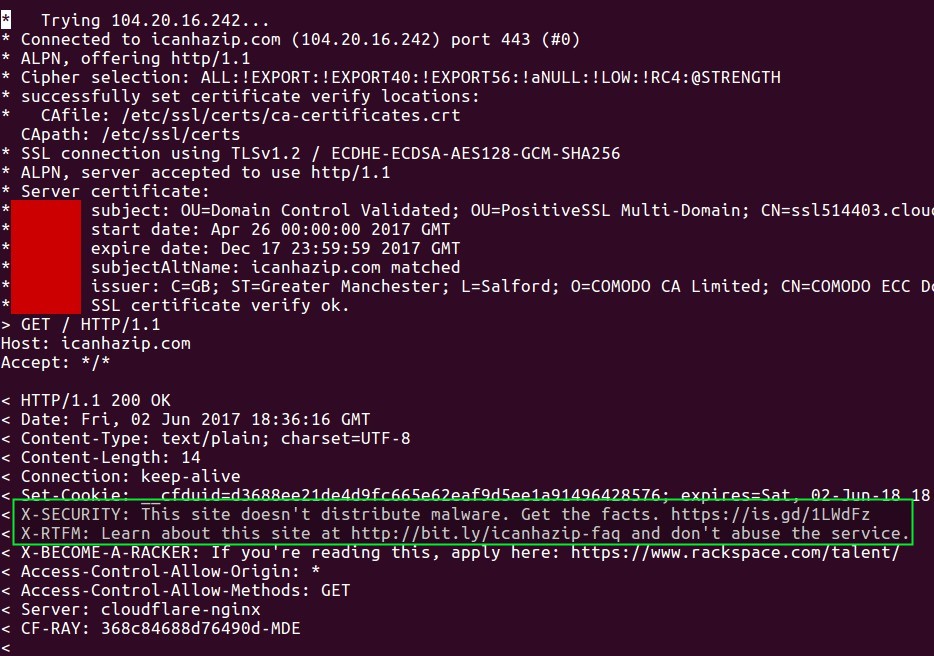
Y al seguir el enlace indicado abrimos el blog de Major Hayden (sí, ese es el nombre, no no es mayor de ningún ejército ni alcalde de ninguna ciudad) un administrador de sistemas GNU/Linux con 6 años de experiencia quien ha tenido excelentes maestros y está dispuesto siempre aprender… como nosotros mismos, quienes escribimos y quienes leemos este humilde sitio web.
Auguramos que curl y PH curl seguirá creciendo y mejorando para nuestro beneplácito y que nosotros, a la larga, algún día aportaremos nuestro granito de arena a la causa del software libre, de una u otra manera, de manera inexorable.
curl_setopt(): parámetros mas socorridos.
La lista es larga en verdad pero mencionaremos, al menos, los que avizoramos de alguna utilidad dada la experiencia que hemos logrado a lo largo de los años:
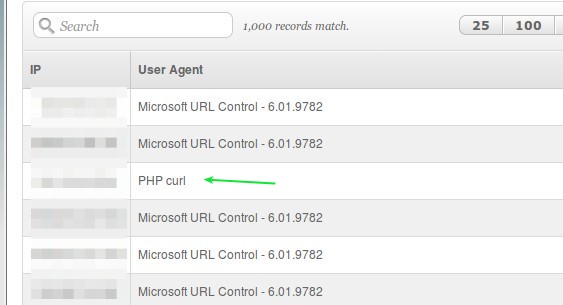
CURLOPT_USERAGENT
Con esta opción podremos indicarle al servidor con el cual le estamos requiriendo información acerca de nuestra identidad. Curiosamente PHP curl por defecto no envía indentificación alguna acerca del nombre del software pero es que también el servidor que atiende la consulta tampoco la requiere como obligatoria. En la práctica les mostramos (las direcciones IP las ocultamos -junto con otros detalles- de las visitas a esta vuestra página web):
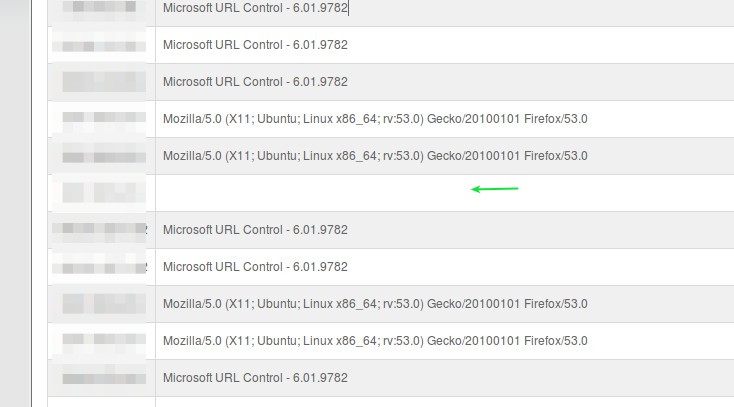
Así que le aplicamos código y así quedaría la visita de nuestro bot en cierne:
CURLOPT_CONNECTTIMEOUT
A veces estimamos en cuánto tiempo debería responder determinado proceso y si no se realiza pues no está bien afinado nuestro servidor no sin antes descartar fallas de internet, etc. Para ello CURLOPT_CONNECTTIMEOUT es el idóneo para que nuestro script no se cuelgue indefinidamente, al cabo de cierto tiempo que le establezcamos y si no logra conectar con el servidor la tarea finalizará. El tercer parámetro que pasaríamos a continuación es el número de segundos, lo cual es una eternidad en tiempo de computadores, por ello también contamos con CURLOPT_CONNECTIONTIMEOUT_MS que viene expresado en milisegundos si estamos realmente apurados.
Es una excelente opción para desarrollar herramientas de diagnóstico a equipos remotos y podremos llevar un ergistro de eventos en nuestra base de datos (sí, que ya hay mucho software para eso pero también hay tareas tan pequeñas que no necesitamos «una mandarria sino un simple martillito»)
CURLOPT_COOKIE y CURLOPT_COOKIEFILE
Una «cookie» en inglés o galletita en castellano, es una pieza de información que plantan los servidores web en nuestros navegadores para identificarnos de manera absoluta. Al igual que el método POST debemos saber el nombre de la galletita y por ende su contenido, así que no la generamos nosotros -obvio- pero si debemos tener una para poder obtener respuesta de algunos servidores, quienes comparan si tienen la galletita en su lista de memoria (las galletitas tienen vencimiento o validez en el tiempo) y así podrán:
- bien sea aceptar nuestra petición ó
- incluso devolvernos unos valores personalizados.
De allí viene el gran temor a la violación de nuestra privacidad, una delgada línea demarca las buenas de las malas intenciones.
De esto último viene la necesidad de CURLOPT_COOKIEFILE, muchas veces son tantas las galletitas usadas por nosotros los programadores que mejor es enviar un archivo completo con ellas incluídas. Aquí debemos colocar el nombre del archivo en la opción anterior debemos enviar los valores en sí.
Otra manera de pasar una gran cantidad de galletitas es pasar el jarrón completo, un fichero, y para que no se nos olvide la sintaxis le pusieron el curioso nombre CURLOPT_COOKIEJAR. Un ejemplo sería:
curl_setopt($objCurl, CURLOPT_COOKIEJAR, 'jarron_de_galletitas.txt');[/cc]
CURLOPT_SSL_VERIFYPEER
Con esta opción podemos deshabilitar que verifique certificados en una conexión https (o mejor dicho TLS). Esto normalmente está habilitado pero uno a veces necesita, por economía, un certificado autofirmado el cual no está validado ante ningún tercer ente. Con esta opción cambiada a false en el tercer parámetro evitaremos este problemita.
CURLOPT_FOLLOWLOCATION
Actualmente las redirecciones de página se ha vuelto el pan nuestro de cada día motivado a la popularidad de las páginas web. Una página de cualquier gobierno del mundo de muy seguro que tendrá miles y hasta millones de visitantes y como comprenderán un solo servidor web jamás ni nunca se daría abasto. Lo que se ha inventado es poner granjas de servidores en distintas partes del mundo con copias constantes de los dominios deseados y redireccionado el tráfico con ayuda de potentes DNS: todo esto se conoce como CDN o «Content Delivery Network».
La idea del asunto es que cuando uno solicita una página web los DNS encargados redireccionan nuestra solicitud a la granja de servidores más cerca a nosotros de manera geográfica donde habrá una copia de la web que queremos. ¿A qué viene todo este cuento con PHP curl? Que es muy probable que la respuesta que obtengamos será una cabecera tipo 300 indicandonos que la direcciíon adecuadad para nosotros y entonces volvemos a hacer la petición -la misma petición- pero a otro servidor más cercano (o mas desocupado, o que tenga nuestra idioma, etc. -el que nos convenga-).
PHP curl ya está preparado en ese escenario y estableceremos CURLOPT_FOLLOWLOCATION a verdadero y por defecto PHP curl redireccionará hasta un máximo de 5 oportunidades nuestra solicitud (más adelante veremos otra función que nos dirá cuántas redirecciones siguió con la variable CURLINFO_REDIRECT_COUNT establecida).
Un problema se presenta al hacer una consulta POST: después del primer redireccionamiento PHP curl NO HACE una consulta POST sino una consulta GET (por razones históricas y de costumbres en los navegadores) y esto es un problema porque son métodos distintos y no obtendremos respuesta (aparte de que nos volveremos «locos» buscando dónde está el error). Para prevenir este inconveniente en vez de fijar CURLOPT_POST a «true» tomaremos otra opción, CURLOPT_CUSTOMREQUEST fijado a «POST»:
curl_setopt($ObjCurl, CURLOPT_CUSTOMREQUEST, "POST");[/cc]
Otra advertencia más: cuando uno sube archivos por medio de CURLOPT_POSTFIELDS en la segunda redirección no será enviado dicho fichero. También para prevenir esto urge emplear CURLOPT_POSTREDIR fijado el valor a 3 para que maneje los redireccionamientos 301 y 302 reenviando el archivo en cada oportunidad (es más tráfico de datos pero ¿cómo hacemos con los CDN’s que llegaron para quedarse?).
Panorama general del resto de las opciones de curl_setopt()
Ya en este punto os habreis dado cuenta de la importancia de esta función, recordad que solo hemos visto apenas cuatro que van en este orden: curl_init(), curl_setopt(), curl_exec() y curl_close(); pues bien hay 23 funciones más de las cuales más adelante estudiaremos una de ellas (por ahora).
He aquí un listado clasificado por el tipo de contenido que hay que pasar en el tercer parámetro de curl_setopt(), de un vistazo (en marrón las que hemos visto y analizado):
Aquellas cuyo valor debe ser booleano (verdadero<>0 ó falso=0):
- CURLOPT_AUTOREFERER
- CURLOPT_BINARYTRANSFER
- CURLOPT_COOKIESESSION
- CURLOPT_CERTINFO
- CURLOPT_CONNECT_ONLY
- CURLOPT_CRLF
- CURLOPT_DNS_USE_GLOBAL_CACHE
- CURLOPT_FAILONERROR
- CURLOPT_SSL_FALSESTART
- CURLOPT_FILETIME
- CURLOPT_FOLLOWLOCATION
- CURLOPT_FORBID_REUSE
- CURLOPT_FRESH_CONNECT
- CURLOPT_FTP_USE_EPRT
- CURLOPT_FTP_USE_EPSV
- CURLOPT_FTP_CREATE_MISSING_DIRS
- CURLOPT_FTPAPPEND
- CURLOPT_TCP_NODELAY
- CURLOPT_FTPASCII
- CURLOPT_FTPLISTONLY
- CURLOPT_HEADER
- CURLINFO_HEADER_OUT
- CURLOPT_HTTPGET
- CURLOPT_HTTPPROXYTUNNEL
- CURLOPT_MUTE
- CURLOPT_NETRC
- CURLOPT_NOBODY
- CURLOPT_NOPROGRESS
- CURLOPT_NOSIGNAL
- CURLOPT_PATH_AS_IS
- CURLOPT_PIPEWAIT
- CURLOPT_POST
- CURLOPT_PUT
- CURLOPT_RETURNTRANSFER
- CURLOPT_SAFE_UPLOAD
- CURLOPT_SASL_IR
- CURLOPT_SSL_ENABLE_ALPN
- CURLOPT_SSL_ENABLE_NPN
- CURLOPT_SSL_VERIFYPEER
- CURLOPT_SSL_VERIFYSTATUS
- CURLOPT_TCP_FASTOPEN
- CURLOPT_TFTP_NO_OPTIONS
- CURLOPT_TRANSFERTEXT
- CURLOPT_UNRESTRICTED_AUTH
- CURLOPT_UPLOAD
- CURLOPT_VERBOSE
Aquellas cuyo valor debe ser numérico entero:
- CURLOPT_BUFFERSIZE
- CURLOPT_CLOSEPOLICY
- CURLOPT_CONNECTTIMEOUT
- CURLOPT_CONNECTTIMEOUT_MS
- CURLOPT_DNS_CACHE_TIMEOUT
- CURLOPT_EXPECT_100_TIMEOUT_MS
- CURLOPT_FTPSSLAUTH
- CURLOPT_HEADEROPT
- CURLOPT_HTTP_VERSION
- CURLOPT_HTTPAUTH
- CURLOPT_INFILESIZE
- CURLOPT_LOW_SPEED_LIMIT
- CURLOPT_LOW_SPEED_TIME
- CURLOPT_MAXCONNECTS
- CURLOPT_MAXREDIRS
- CURLOPT_PORT
- CURLOPT_POSTREDIR
- CURLOPT_PROTOCOLS
- CURLPROTO_HTTP, CURLPROTO_HTTPS, CURLPROTO_FTP, CURLPROTO_FTPS, CURLPROTO_SCP, CURLPROTO_SFTP, CURLPROTO_TELNET, CURLPROTO_LDAP, CURLPROTO_LDAPS, CURLPROTO_DICT, CURLPROTO_FILE, CURLPROTO_TFTP, CURLPROTO_ALL
- CURLOPT_PROXYAUTH
- CURLOPT_PROXYPORT
- CURLOPT_PROXYTYPE
- CURLOPT_REDIR_PROTOCOLS
- CURLOPT_RESUME_FROM
- CURLOPT_SSL_OPTIONS
- CURLOPT_SSL_VERIFYHOST
- CURLOPT_SSLVERSION
- CURLOPT_STREAM_WEIGHT
- CURLOPT_TIMECONDITION
- CURLOPT_TIMEOUT
- CURLOPT_TIMEOUT_MS
- CURLOPT_TIMEVALUE
- CURLOPT_MAX_RECV_SPEED_LARGE
- CURLOPT_MAX_SEND_SPEED_LARGE
- CURLOPT_SSH_AUTH_TYPES
- CURLOPT_IPRESOLVE
- CURL_IPRESOLVE_WHATEVER (por defecto), CURL_IPRESOLVE_V4, CURL_IPRESOLVE_V6
- CURLOPT_FTP_FILEMETHOD
- CURLFTPMETHOD_MULTICWD, CURLFTPMETHOD_NOCWD, CURLFTPMETHOD_SINGLECWD.
Aquellas cuyo valor debe ser una cadena de texto:
- CURLOPT_CAINFO
- CURLOPT_CAPATH
- CURLOPT_COOKIE
- CURLOPT_COOKIEFILE
- CURLOPT_COOKIEJAR
- CURLOPT_CUSTOMREQUEST
- CURLOPT_DEFAULT_PROTOCOL
- CURLOPT_DNS_INTERFACE
- CURLOPT_DNS_LOCAL_IP4
- CURLOPT_DNS_LOCAL_IP6
- CURLOPT_EGDSOCKET
- CURLOPT_ENCODING
- CURLOPT_FTPPORT
- CURLOPT_INTERFACE
- CURLOPT_KEYPASSWD
- CURLOPT_KRB4LEVEL
- CURLOPT_LOGIN_OPTIONS
- CURLOPT_PINNEDPUBLICKEY
- CURLOPT_POSTFIELDS
- CURLOPT_PRIVATE
- CURLOPT_PROXY
- CURLOPT_PROXY_SERVICE_NAME
- CURLOPT_PROXYUSERPWD
- CURLOPT_RANDOM_FILE
- CURLOPT_RANGE
- CURLOPT_REFERER
- CURLOPT_SERVICE_NAME
- CURLOPT_SSH_HOST_PUBLIC_KEY_MD5
- CURLOPT_SSH_PUBLIC_KEYFILE
- CURLOPT_SSH_PRIVATE_KEYFILE
- CURLOPT_SSL_CIPHER_LIST
- CURLOPT_SSLCERT
- CURLOPT_SSLCERTPASSWD
- CURLOPT_SSLCERTTYPE
- CURLOPT_SSLENGINE
- CURLOPT_SSLENGINE_DEFAULT
- CURLOPT_SSLKEY
- CURLOPT_SSLKEYPASSWD
- CURLOPT_SSLKEYTYPE
- CURLOPT_UNIX_SOCKET_PATH
- CURLOPT_URL
- CURLOPT_USERAGENT
- CURLOPT_USERNAME
- CURLOPT_USERPWD
- CURLOPT_XOAUTH2_BEARER
Aquellas cuyo valor debe ser una matriz:
- CURLOPT_CONNECT_TO
- CURLOPT_HTTP200ALIASES
- CURLOPT_HTTPHEADER
- CURLOPT_POSTQUOTE
- CURLOPT_PROXYHEADER
- CURLOPT_QUOTE
Aquellas cuyo valor debe ser un recurso de flujo de datos:
- CURLOPT_FILE
- CURLOPT_INFILE
- CURLOPT_STDERR
- CURLOPT_WRITEHEADER
Aquellas cuyo valor debe ser una función o una función de cierre:
- CURLOPT_HEADERFUNCTION
- CURLOPT_PASSWDFUNCTION
- CURLOPT_PROGRESSFUNCTION
- CURLOPT_READFUNCTION
- CURLOPT_WRITEFUNCTION
Aquellas cuyo valor debe ser una muy específica:
- CURLOPT_SHARE
Función curl_setopt_array.
Nos dimos cuenta como la función exit() mejoró muy bien la legilibilidad de nuestro código y además proporciona información a nuestros usuarios en caso de tratamiento de excepciones. Pero hay una manera aún mejor de configurar las opciones justo antes de ejecutar curl_exec() con el detalle que es como la famosa película de vaqueros: tiene lo bueno, lo malo y lo feo pero sin lo feo. Lo bueno -y muy bueno- es que como dijimos mejora la apariencia de nuestro código y abre nuevas posibilidades con el uso de una matriz: podemos realizar una función que consulte una base de datos y llene dicha matriz. Lo malo es que al pasar todo de un solo golpe a la unficón ésta acepta todo o no acepta nada y tendremos nuestra bella salida diciendo «no se pudo establecer culr_setopt_array» pero no nos indicará dónde, cuál es el elemento que falla.
$objCurl = curl_init()
or exit("No se pudo inicializar PHP curl.
");
$verbose = fopen(‘verbose.txt’, ‘a’)
or exit(«No se pudo abrir el archivo verbose.txt
«);
$opciones = array(
CURLOPT_URL => ‘https://icanhazip.com’,
CURLOPT_VERBOSE => 1,
CURLOPT_STDERR => $verbose
);
curl_setopt_array($objCurl, $opciones)
or exit(«No se pudo establecer curl_setopt_array()»);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
curl_close ($objCurl);
?>[/cc]
Percataos que colocamos el URL en la matriz para abultar y activamos el modo de depuración de resto todo lo demás es el mismo ejemplo que colocamos anteriormente. Lo curioso del asunto es que curl_setopt() y curl_setopt_array() pueden trabajar juntos perfectamente, lo anterior lo podemos reescribir como lo próximo y funciona plenamente:
$objCurl = curl_init()
or exit("No se pudo inicializar PHP curl.
");
curl_setopt($objCurl, CURLOPT_URL ,’https://icanhazip.com’)
or exit(«No se pudo establecer el CULROPT_URL»);
$verbose = fopen(‘verbose.txt’, ‘a’)
or exit(«No se pudo abrir el archivo verbose.txt
«);
$opciones = array(
CURLOPT_VERBOSE => 1,
CURLOPT_STDERR => $verbose
);
curl_setopt_array($objCurl, $opciones)
or exit(«No se pudo establecer curl_setopt_array()»);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
curl_close ($objCurl);
?>[/cc]
Analizando los resultados de la última conexión.
Comentamos que PHP curl puede utilizarse para fabricar una sencilla herramienta de monitoreo de servidores. Pensando en esto indagamos en ciertas opciones que trae la librería y de la cual podemos obtener gran cantidad de información, siempre pensando en guardarlo en una base de datos para su posterior análisis de manera masiva. Pero debemos comenzar por lo básico y no irnos precipitadamente.
Aparte de las opciones de depuración, que ya logramos vertirlas en un archivo que llamamos simplemente «verbose.txt» (y cuyo nombre podemos cambiar a la fecha y hora actual para que siempre sea un archivo distinto y almacenar -o borrar, o procesar, etc.- cuando queramos) podemos echar mano de otra función para obtener los datos de la conexión. Tal función es denominada curl_getinfo() a la que introducimos nuestro manejador creado por curl_init().
Esta función devuelve falso si no tiene información o una matriz con elementos predefinidos -no todos-. Para poder escribir esta matriz en un archivo agarramos a la función serialize() para convertirla en una cadena de texto antes de guardarla.
De una vez vamos a la práctica con el primer ejemplo que presentamos, el más «refinado» con las llamadas exit() ¿lo recordais? Pero vamos un paso adelante y lo modificamos, primero para que tome la URL por el método GET: escribimos en la barra de direcciones la ubicación de nuestro guion y al final agregamos un signo de cierre de interrogante con la palabra «url», luego un signo de igualdad y a continuación el dominio o página que queremos descargar y guardar -para luego analizar según el propósito que tengamos, que para cada persona es muy variopinto. Supongamos que nuestro guion está en nuestro servidor local y se llama «curl.php», el llamado sería el siguiente (obvien el prefijo «http://» porque lo agregamos en el script):
http://localhost/curl.php?url=www.ks7000.net.ve[/cc]
También agregaremos dos mensajes adicionales: si no se pasa una URL entonces alerta que debe pasar una y otro mensaje para indicar que ha sido guardada en un archivo (recordad que usamos la opcion CURLOPT_RETURNTRANSFER al valor de 1). Coloreamos el código para su mayor comprensión:
if ($_GET["url"]) { $objCurl = curl_init("http://".$_GET["url"]) or exit("No se pudo inicializar PHP curl. ");
$nom_arch = ‘servidor.html’;
$arch = fopen( $nom_arch , «a»)
or exit(«No se pudo abrir el archivo ‘».$nom_arch.»‘
«);
curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1)
or exit(«No se pudo establecer CURLOPT_RETURNTRANSFER.
«);
curl_setopt ($objCurl, CURLOPT_FILE, $arch)
or exit(«No se pudo establecer CURLOPT_FILE.
«);
curl_setopt ($objCurl, CURLOPT_CONNECTTIMEOUT, 7)
or exit(«No se pudo establecer CURLOPT_CONNECTTIMEOUT.
«);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
$nom_arch = «servidor_respuesta.txt»;
$archivo = fopen($nom_arch, «a»)
or exit(«No se pudo abrir el archivo'».$nom_arch.»‘
«);
$resp = curl_getinfo($objCurl)
or exit(«No se pudo obtener información de la ultima conexion.
«);
fwrite($archivo, serialize($resp))
or exit(«No se pudo escribir en el archivo ‘».$nom_arch.»‘
«);
fclose($archivo)
or exit(«No se pudo cerrar el archivo ‘».$nom_arch.»‘
«);
// curl_close NO devuelve resultado:
curl_close ($objCurl);
echo «URL descargada y guardada.
«;
} else {
echo «Debe pasar una URL para ser descargada y analizada.
«;
}
?>
[/cc]
Es crucial llamar esta función ANTES de llamar la función curl_close() que es cuando aún existe el objeto en memoria.
Matrix con campos predefinidos.
Esos datos que guardamos en el anterior software que inventamos ya están seleccionados por los desarrolladores de PHP curl y son los siguientes (repetimos, NO son todos los disponibles):
- «url»
- «content_type»
- «http_code»
- «header_size»
- «request_size»
- «filetime»
- «ssl_verify_result»
- «redirect_count»
- «total_time»
- «namelookup_time»
- «connect_time»
- «pretransfer_time»
- «size_upload»
- «size_download»
- «speed_download»
- «speed_upload»
- «download_content_length»
- «upload_content_length»
- «starttransfer_time»
- «redirect_time»
- «certinfo»
- «primary_ip»
- «primary_port»
- «local_ip»
- «local_port»
- «redirect_url»
- «request_header» (solamente está definido si CURLINFO_HEADER_OUT está establecido por una llamada previa a curl_setopt())
Totalidad de los campos de get_info()
Podemos solicitar cualquiera de estos campos pasando como parámetro los siguientes valores a la función curl_getinfo() -con una breve descripción y ordenados alfabéticamente-:
- CURLINFO_APPCONNECT_TIME – Tiempo, en segundos, desde el inicio hasta la conexión/apretón de manos SSL/SSH del host remoto.
- CURLINFO_CERTINFO – Serie de certificados TLS.
- CURLINFO_CONDITION_UNMET – Información del condicional de timepo unmet.
- CURLINFO_CONNECT_TIME – Tiempo, en segundos, que tomó el establecimiento de la conexión.
- CURLINFO_CONTENT_LENGTH_DOWNLOAD – Logitud del contenido de la descarga, leída desde el campo “Content-Length:”.
- CURLINFO_CONTENT_LENGTH_UPLOAD – Tamaño especificado de subida .
- CURLINFO_CONTENT_TYPE – “Content-Type:” del documento solicitado. NULL indica que el servidor no envío un encabezado “Content-Type:” válido.
- CURLINFO_COOKIELIST – Todas las cookies conocidas.
- CURLINFO_EFFECTIVE_URL – Último URL efectivo.
- CURLINFO_FILETIME – Hora del documento remoto obtenido; si devuelve -1, la hora del documento es desconocida.
- CURLINFO_FTP_ENTRY_PATH – Ruta de entrada en el servidor FTP.
- CURLINFO_HEADER_OUT – El string de la petición enviada. Para que funcione, se ha de añadir la opción CURLINFO_HEADER_OUT al manejador, llamando a curl_setopt()
- CURLINFO_HEADER_SIZE – Tamaño total de los encabezados recibidos.
- CURLINFO_HTTP_CODE – Último código HTTP recibido.
- CURLINFO_HTTP_CONNECTCODE – El código de respuesta de CONNECT.
- CURLINFO_HTTPAUTH_AVAIL – Máscara de bits que indica el/los método/s de autenticación disponible/s de acuerdo a la respuesta anterior.
- CURLINFO_LOCAL_IP – Dirección IP local (fuente) de la conexión más reciente.
- CURLINFO_LOCAL_PORT – Puerto local (fuente) de la conexión más reciente.
- CURLINFO_NAMELOOKUP_TIME – Tiempo, en segundos, en resolver el nombre.
- CURLINFO_NUM_CONNECTS – Número de conexiones que curl ha tenido que crear para lograr la transferencia anterior.
- CURLINFO_OS_ERRNO – Número de error (errno) de un fallo de conexion. Es número es específico de cada SO y sistema.
- CURLINFO_PRETRANSFER_TIME – Tiempo, en segundos, desde el inicio hasta justo antes de que comience la transferencia del fichero.
- CURLINFO_PRIMARY_IP – Dirección IP de la conexión más reciente.
- CURLINFO_PRIMARY_PORT – Puerto de destino de la conexión más reciente.
- CURLINFO_PRIVATE – Datos privados asociados a este manejador de cURL, previamente establecidos con la opción CURLOPT_PRIVATE de curl_setopt()
- CURLINFO_PROXYAUTH_AVAIL – Máscara de bits que indica el/los método/s de autenticaición proxy disponible/s de acuerdo a la respuesta anterior.
- CURLINFO_REDIRECT_COUNT – Número de redireccionamientos, con la opción CURLOPT_FOLLOWLOCATION habilitada.
- CURLINFO_REDIRECT_TIME – Tiempo, en segundos, de todos los pasos de redireción antes de que la última transación haya empezado, con la opción CURLOPT_FOLLOWLOCATION habilitada.
- CURLINFO_REDIRECT_URL – Con la opción CURLOPT_FOLLOWLOCATION inhabilitada: URL de redirección encontrado en la última transacción, que debería ser solicitado manualmente luego. Con la opción CURLOPT_FOLLOWLOCATION habilitada: está vacío. El URL de redirección en este caso está disponible en CURLINFO_EFFECTIVE_URL
- CURLINFO_REQUEST_SIZE – Tamaño total de las peticiones realizadas, actualmente solo para peticiones HTTP.
- CURLINFO_RESPONSE_CODE – El último código de respuesta.
- CURLINFO_RTSP_CLIENT_CSEQ – Siguiente CSeq cliente de RTSP.
- CURLINFO_RTSP_CSEQ_RECV – CSeq recivido recientemente.
- CURLINFO_RTSP_SERVER_CSEQ – Siguiente CSeq servidor de RTSP.
- CURLINFO_RTSP_SESSION_ID – ID de sesión de RTSP.
- CURLINFO_SIZE_DOWNLOAD – Número total de bytes descargados.
- CURLINFO_SIZE_UPLOAD – Número total de bytes subidos.
- CURLINFO_SPEED_DOWNLOAD – Velocidad media de descarga.
- CURLINFO_SPEED_UPLOAD – Velocidad media de subida.
- CURLINFO_SSL_ENGINES – Criptomotores OpenSSL admitidos.
- CURLINFO_SSL_VERIFYRESULT – Resultado de la verificación del certificado SSL solicitado por la opción CURLOPT_SSL_VERIFYPEER.
- CURLINFO_STARTTRANSFER_TIME – Tiempo, en sengudos, hasta que el primer byte está a punto de transferirse.
- CURLINFO_TOTAL_TIME – Duración total, en segundos, de última transferencia.
Futuro de cURL.
Como bien es sabido por todos nosotros, Internet como tal está basado en las siete capas de red según el modelo de interconexión de sistemas abiertos (ISO/IEC 7498-1), más conocido como “modelo OSI”, (en inglés, Open System Interconnection) y cURL hace uso de la séptima capa para las transferencias por internet orientadas a ficheros. Por ello su autor Daniel Stenberg deja bien claro que eso es lo que seguirá haciendo cURL ahora y durante mucho tiempo. A continuación una traducción automatizada de su entrada en el blog al respecto:
No soy de los que pasan el tiempo mirando hacia el horizonte soñando con la grandeza futura y haciendo planes sobre cómo ir allí. Trabajo en cosas ahora mismo para trabajar mañana. No tengo idea de lo que haremos y trabajaremos en un año a partir de ahora. Conozco un montón de cosas en las que quiero trabajar a continuación, pero no estoy seguro de si alguna vez llegaré a ellas o si realmente enviarán o si tal vez serán reemplazadas por otras cosas en esa lista antes de que llegue a ellas.
El mundo, Internet y las transferencias cambian constantemente y nos estamos adaptando. No hay sueños a largo plazo más que apegarse al plan simple y único: hacemos transferencias de Internet orientadas a archivos utilizando protocolos de capa de aplicación.
Las estimaciones aproximadas dicen que ya podemos tener mil millones de usuarios. Lo más probable es que si las cosas no cambian demasiado drásticamente sin que podamos mantener el ritmo, tendremos incluso más en el futuro.
Resumen.
Recuerden lo que siempre dijo en vida nuestro Gran Maestro: «un punto, un punto y una línea recta«; aprovechen estos conocimientos para desarrollar programas y utilidades para fortalecer el Patrimonio Tecnológico de nuestra Humanidad no para escribir virus y gusanos que marguen las vidas de los demás.
<Esto es todo, pora ahora>.
Actualizado el sábado 27 de enero de 2018.
Recientemente, pocos días atrás, el creador de cURL, Daniel Stenberg, publicó la versión 7.58 la cual contiene una curiosa correción al proceso de agregar un «espacio en blanco» (sí, un simple y vulgar espacio en blanco) en el «pase» de las cabeceras URL (ver en GitHub el causante de este desaguisado) lo cual nos parece muy significativo, pues somos de los que insistimos y somos fastidiosos en corregir hasta el último caracter al programar (si véis algún error por estos lares hacednos un comentario abajo). Pero no somos los únicos, mirad el siguiente «tuit»:
Fuentes consultadas.
En idioma castellano.
- «Enviar parametros post utilizando CURLOPT_POSTFIELDS» por Juan David Gómez Caicedo.
- «Como averiguar la web destino de una URL acortada con cURL» por José Miguel.
En idioma inglés.
-
- «command line tool and library for transferring data with URLs» | Curl’s Official Web Site.
- «Project cURl at GitHub».
- «Everything about curl» by Daniel Stenberg.
- «Your first Curl scripts«.
- «Using cURL for Remote Requests» By Alexander Cogneau.
- «cURL functions» at PHP.net
- «PHP + Cookies + libCurl» by Diogo Parrhina.
- «Tamper Data» by Adam Judson.
- «PHP debugging curl» at StackOverFlow.
- «About me: Major Hayden«.
- «How to post XML using CURL?» by Om LAMP Developer.
- «Using PHP and CURL to log in to a website» by Andy Hunt.
- «How to submit a form using PHP» by Prasanth.
- «Following redirects with Curl in PHP» by Evert Pot.
- «PHP and cURL: How WordPress makes HTTP requests» by Pete Tasker.
- «PHP cURL custom headers» at StackOverFloe.
- «The curl and wget war» by Daniel Stenberg.
Un comentario en «PHP y cURL»
Los comentarios están cerrados.