CAPTCHA
Introducción:
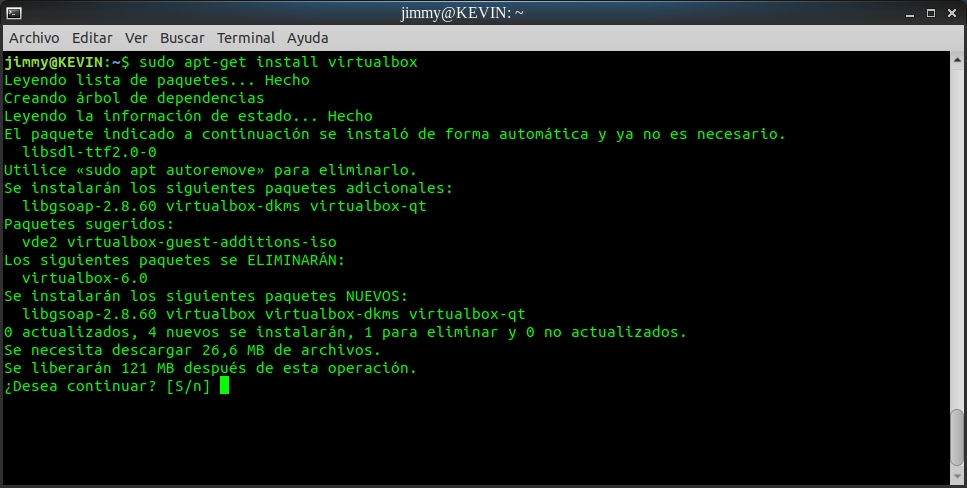
Siempre me ha llamado la atención los CAPTCHA («Completely Automated Public Turing test to tell Computers and Humans Apart«) que hay en muchas páginas web y que permiten diferenciar consultas hechas por humanos de las hechas por «arañas» que pululan por internet (son también conocidas como «robots»). La diferencia esencial en este caso con respecto a la prueba de Turing es que se trata de convencer a una máquina que es un humano, osea el inverso de la prueba.
En el idioma inglés existe la filosofía K.I.S.S. y la practico frecuentemente ya que los sistemas complejos tienden al caos de manera natural. Es por ello que buscando por internet (precisamente ayudado por las «arañas» que pretendo combatir, ¡qué ironía!) he encontrado el siguiente artículo que me deslumbró por su simplicidad más al cabo de una hora de estudio observo los elementos implícitos sin los cuales NO funciona. Recomiendo vayan y lean dicho artículo y regresen cuando lo hayan asimilado, yo por aquí les espero. 😎
El artículo data del año 2007 pero considero que no ha perdido vigencia alguna, si administran una página web bancaria o son partidarios del último grito de la moda, recomiendo desistan de seguir leyendo esto. 😉
Pues bien manos a la obra.
Requisitos previos.
Utilizo una máquina virtual con Debian Wheezy con la cual estudio el programa para base de datos PostgreSQL a la cual le he instalado también un servidor Apache con PHP: este tipo de configuración es llamado LAMP por sus siglas en inglés, sólo que en aquí en realidad es un LAPP: Linux, Apache, PostgreSQL y PHP. Hay muchísimos tutoriales para instalar este tipo de servidores por ello partimos de la base que ustedes cuentan con uno en funcionamiento y para pruebas (no utilicen un servidor «en producción» hasta tanto no estén completamente seguros de este código). Importante recalcar que no utilizaremos funciones de bases de datos en esta entrada, pero muy frecuentemente las CAPTCHA se utilizan en este tipo de ambiente, por ejemplo, registrar usuarios en una lista de correo electrónico (tremenda tentación para los «robots spam»), así que allí encaja perfectamente.
Configuración adicional.
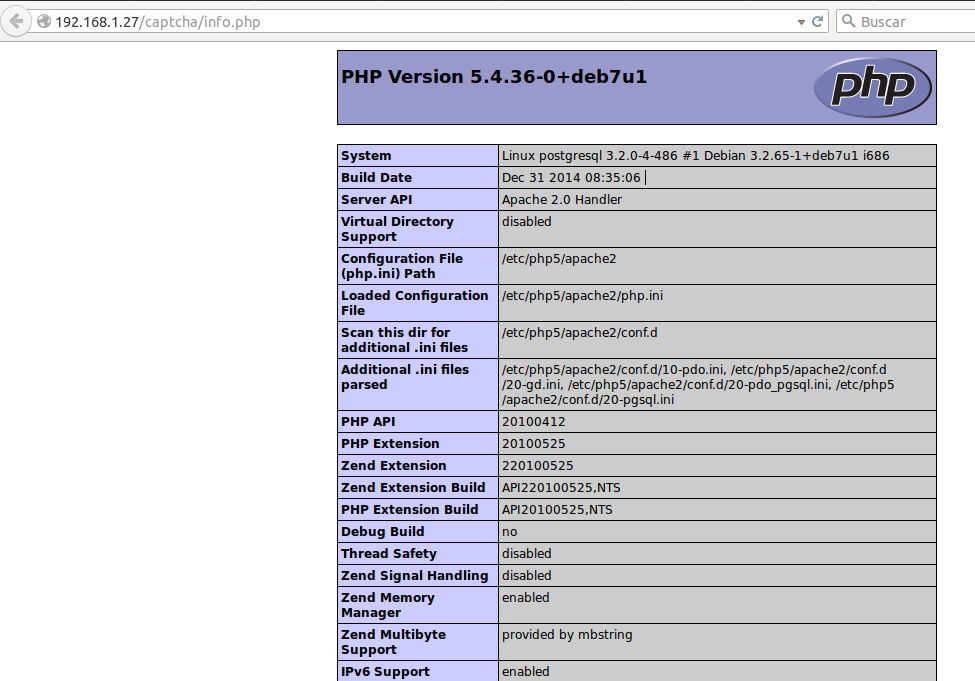
Al servidor LAPP anteriormente descrito debemos instalarle unas librerías para el trabajo gráfico bajo el lenguaje PHP. Aquí está muy bien descrito a lo que me refiero, haciendo la salvedad que dichas librerías NO SIEMPRE están instaladas por defecto.
En todo caso debemos crear una carpeta bajo la raíz web del servidor Apache con el nombre «captcha» y donde alojaremos el siguiente archivo «info.php»:
<?php
// Archivo "info.php":
// Muestra toda la información, por defecto INFO_ALL
phpinfo();
?>
y luego iremos a nuestro navegador web preferido a la dirección
IP que le hayamos asignado en nuestra red de área local. En mi caso dicha dirección es 192.168.1.27 en la carpeta «captcha»:
En dicha página debemos buscar si están instalados los siguientes valores:
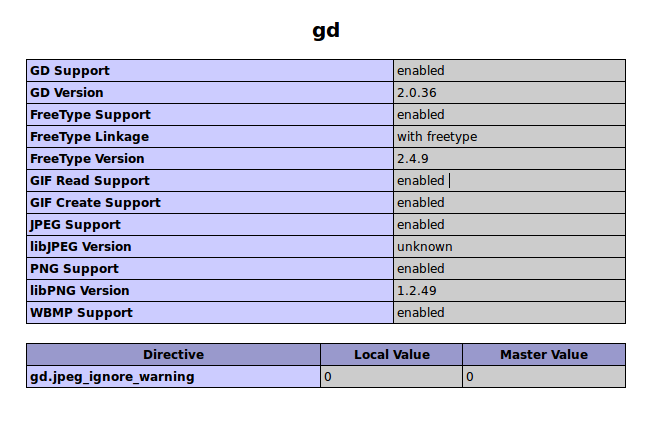
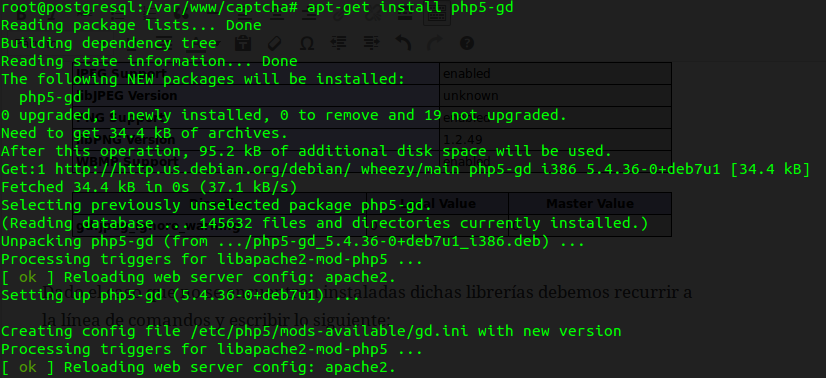
Dado el caso que no se encuentren instaladas dichas librerías debemos recurrir a la línea de comandos y escribir lo siguiente:
sudo apt-get install php5-gd
y verán algo más o menos parecido a esto (en mi caso no necesité el comando «sudo» porque ya había ganado acceso como root con el comando «su»):
Dichas librerías son necesarias para el trabajo con imágenes jpg, png y gif, entre otros formatos y funciones.
Imagen de fondo para el CAPTCHA:
Necesitaremos un imagen tipo gif con unas dimensiones de 100×30 píxeles con colores adecuados teniendo en cuenta que las letras serán negras buscaremos colores como azul o verde o el que gusten pero no de color negro. Yo elegí la siguiente imagen (aunque al final agregaremos varios elementos para dificutarles la tarea de lectura a los «robots» con técnicas OCR ):  Como ven es una imagen con degradado que busca confundir al OCR pero con legibilidad al ser humano; no obstante usar este mismo fondo siempre y con la ayuda de la «fuerza bruta» se puede descifrar al poco tiempo -pero de eso nos encargaremos luego, de «complicarlo» para tratar de eludir la lectura-. La imagen la guardaremos en la carpeta de trabajo en el servidor web bajo el nombre «bgcaptcha.gif» (nemotécnico ‘BackGroundCaptcha.gif’=’bgcaptcha.gif’).
Como ven es una imagen con degradado que busca confundir al OCR pero con legibilidad al ser humano; no obstante usar este mismo fondo siempre y con la ayuda de la «fuerza bruta» se puede descifrar al poco tiempo -pero de eso nos encargaremos luego, de «complicarlo» para tratar de eludir la lectura-. La imagen la guardaremos en la carpeta de trabajo en el servidor web bajo el nombre «bgcaptcha.gif» (nemotécnico ‘BackGroundCaptcha.gif’=’bgcaptcha.gif’).
Para bajar archivos por líneas de comando
recomiendo usar «wget», por ejemplo:
«wget http://www.e.com/imagen_a_bajar.gif nombre_imagen.gif»
Creación del archivo «captcha.php».
Dicho archivo se encargará de tomar la imagen anterior y, aleatoriamente, «escribirle» letras encimas, almacenarlas en una variable (que leeremos con luego con el método POST) y mostrarla al navegador; para ello utilizaremos el siguiente código que explicaremos línea por línea:
<?php
//Archivo 'captcha.php'
session_start();
$_SESSION['tmptxt'] = randomText(7);
$captcha = imagecreatefromgif("bgcaptcha.gif");
$colText = imagecolorallocate($captcha, 0, 0, 0);
imagestring($captcha, 5, 16, 7, $_SESSION['tmptxt'], $colText);
header("Content-type: image/gif");
imagegif($captcha);
imagedestroy($captcha);
?>
- Para que el servidor sepa dónde comienza y dónde termina el lenguaje PHP debemos encerrarlo todo con los siguientes comandos: «<?php (…) ?>» y donde van los paréntesis y puntos suspensivos ubicaremos nuestro código a ejecutar. Todo lo que esté fuera de estos demarcadores será considerado lenguaje HTML e interpretado como tal.
- Cada final de sentencia le será indicado al servidor con un punto y coma «;».
- Los comentarios, que son importantísimos para nosotros los seres humanos, para las máquinas carecen de importancia y se identifican con «//» y la derecha el texto explicativo.
- La función «session_start()» permite crear o recuperar un identificador único que servirá para que el servidor pueda atender varios clientes al mismo tiempo sin confundir las respuestas de cada usuario. No debemos preocuparnos mucho ya que todo es automatizado, si acaso dedicaremos una sentencia «if-then-else» por si acaso devuelve el valor «falso», es decir, no se pudo iniciar sesión (todo el mundo da por sentado que devuelve «verdadero»). Importante, muy importante, el comprender sobre el cómo PHP compara dos variables y/o valores para devolver «verdadero» o «falso», merece su estudio de 10 minutos.
- La función «$_SESSION[]» permite asignar un valor a una variable en la sesión iniciada en el punto anterior y es un variable de arreglo global. El texto, que será aleatorio, lo proporcionará la función «randomText()» que escribiremos luego.
- La función «imagecreatefromgif()» nos permitirá «cargar en memoria» la imagen que destinamos como fondo del CAPTCHA y devolverá un «identificador de imagen» representado en una variable que usaremos para agregar el texto que identificará e introducirá el usuario, ser humano. De nuevo digo que deberíamos destinar un «if-then-else» dado el caso la función devuelva «falso».
- El comando anterior nos permitió establecer el «lienzo» donde vamos a escribir las letras aleatorias; pues el comando «imagecolorallocate()» nos permite fijar el color con que las «pintaremos»: «0, 0, 0» corresponde al color negro en la codificación de valores «RGB», «Red Green Blue» y cuyos valores van del 0 al 255 cada uno y nos permite usar +16 millones de colores. Luego echaremos mano de esta función para confundir aún más a los «robots», por ahora nos conformaremos con el color negro. Es de hacer notar que para esta función CERO es «falso» y cualquier otro valor es «verdadero», si usted considera esto una tontería le invito a leer la disertación sobre el tema, está avisado o avisada.
- La funcíon «imagestring()» dibuja una cadena de texto en nuestro «lienzo», la imagen gif seleccionada. Los parámetros de esta función son: (image, font, x, y, text, color) y los detallo a continuación:
- image: la que cargamos en memoria con la función imagecreatefromgif() y que llamamos $captcha.
- font: numeradas del 1 al 5 y es la fuente nativa predeterminada en la librería GD e incluso nos permite cargar nuestras propias fuentes pero debemos cargarlas y compilarlas de acuerdo a la arquitectura de nuestro servidor. Si se entusiasman a realizar esto último deberán cargar dicha fuente «compilada» con la función imageloadfont() de acuerdo a unos valores binarios. Más interesante hallo utilizar la función imagettftext() NO SIN ANTES VERIFICAR el phpinfo() devuelva que el ambiente del servidor lo soporte (si quieren saber más sobre fuentes True Type en GD visiten este enlace):
- Coordenadas X e Y: tomadas a partir de la esquina superior izquierda, pónganse de cabeza para que las entiendan (ahhh me recuerdo de la materia Geometría Analítica, ¡qué belleza para Autocad! ¡Y dibujábamos por comandos escritos en papel fuera del laboratorio de computación!).
- text: en este caso lo que ya tenemos almacenado en la variable global de sesión «$_SESSION[‘tmptxt’]».
- color: el que establecimos a negro con la función «imagecolorallocate()».
- La función «header()» permite que nuestro servidor se ciña a las normas del lenguaje HTML que consiste en «notificarle» al navegador web (en formato NO html) que le será enviado un flujo de datos, por defecto «application/octet-stream», pero que nosotros utilizaremos para indicarle que es una imagen gif «Content-type: image/gif». Si desean conocer más acerca del nacimiento de la web y sus normas de funcionamiento de la mano del mismísimo Tim Berners-Lee hagan click en este enlace.
- Por último la función «imagegif()» instruye a nuestro servidor que le envie la imagen al navegador del usuario, el CAPTCHA que queremos interprete el ser humano.
- Una función que considero importante y que yo agrego al código mostrado originalmente -y del que desconozco la autoría- es «imagedestroy()» a fin de liberar la memoria utilizada por la variable «$captcha». Aunque toda la memoria se libera cuando el usuario cierra su navegador o cuando nosotros mismos invocamos «session_destroy()» nunca está demás liberar «trabajo» apenas sea posible.
Creación de la función «randomText()».
Ahora explicaré la función que devuelve una cadena de texto de manera aleatoria pero con dos mejoras al código fuente original, el cual es el siguiente:
function randomText($length) {
$pattern = "23456789abcdefghijkmnpqrstuvwxyz";
for($i=0;$i<$length;$i++) {
$key .= $pattern{mt_rand(0,32)};
}
return $key;
}
- Las funciones en PHP se declaran con la palabra clave reservada «function» y los argumentos se pasan entre paréntesis separados por comas.
- Todo el cuerpo de la función esta demarcado por inicio y fin de corchetes «{ … }».
- La función toma como parámetro la variable «$lenght» la cual toma el valor de «7» al hacer el llamado de la siguiente manera: «randomText(7)». Por ende nuestro CAPTCHA tendrá 7 caracteres, recuerden que estamos limitados al espacio del «bgcaptcha.gif».
- En la primera variable «$pattern» establecemos los caracteres que queremos mostrar al usuario, no repetidos, y aquí va la primera mejora que les dije antes: NO incluyo el número uno («1»), ni la letra ele («l») ni tampoco el número cero («0») ni la letra o («O») porque se trata de ponersela difícil al «robot», no al ser humano, quien puede confundir dichos signos.
- Utilizamos un ciclo «for» similar al usado en lenguaje C, es decir, un valor de inicio, una condición que se evalúa en cada ciclo y un incremento en cada ciclo. Así establecemos que al escribir «for ( $i=0; $i<$length; $i++ ) {…}» estamos ordenando ejecutar un ciclo basado en la variable «$i» que comienza desde cero y que mientras sea menor que la longitud de caracteres de nuestro CAPTCHA se incremente en una unidad para cada ciclo, «$i++».
- Dentro de los corchetes del ciclo «for» anterior colocamos la variable «$key» que se autoconcatena en cada rizo «.=» con una letra aleatoria del patrón elegido y que llevamos asignado en la variable $pattern.
- En el lenguaje PHP (e igualmente en Python) cada cadena de caracteres es considerada de manera implícita una matriz de una sola fila, esto nos permite «imprimir» en el navegador del usuario una letra del patrón, por ejemplo «echo $pattern{10}» devolverá «b».
- ¿Cómo escogemos una letra cualquiera del patrón? Aquí es donde viene la segunda mejora que les comenté: en vez de usar la función «rand()» utilizamos la función «mt_rand()» la cual, aparte de ser más rápida nos permite utilizar números más grandes (de ser necesario). Dicha mejora la propone un usuario llamado «caos30» en los comentarios de la entrada del blog en la cual se inspira este tema. Esta función tiene dos argumentos que nos permiten acotar el número devuelto: para este caso es (0, 32) que es precisamente el largo del patrón que escogimos (el abecedario inglés 26 caracteres más los diez dígitos numéricos son 36 menos 4 que eliminé para evitar confusiones a los humanos).
- Es necesario el comando «return» acompañado de la variable que debe devolver la función, en nuestro caso es un tipo «cadena de texto».
Guardado del archivo «captcha.php».
Ya suficientemente explicado línea por línea el código unimos ambos algoritmos y con el editor de texto nano (o el que ustedes prefieran) guardamos en la carpeta «captcha» que hicimos en «\var\www» (donde generalmente Apache guarda el sitio web):
<?php
//Archivo 'captcha.php'
function randomText($length) {
$pattern = "23456789abcdefghijkmnpqrstuvwxyz";
for($i=0;$i<$length;$i++) {
$key .= $pattern{mt_rand(0,32)};
}
return $key;
}
session_start();
$_SESSION['tmptxt'] = randomText(7);
$captcha = imagecreatefromgif("bgcaptcha.gif");
$colText = imagecolorallocate($captcha, 0, 0, 0);
imagestring($captcha, 5, 16, 7, $_SESSION['tmptxt'], $colText);
header("Content-type: image/gif");
imagegif($captcha);
imagedestroy($captcha);
?>
Antes de continuar nos aseguramos que la CAPTCHA se ejecute y muestre correctamente en nuestro navegador conectado a nuestro servidor LAPP de pruebas:
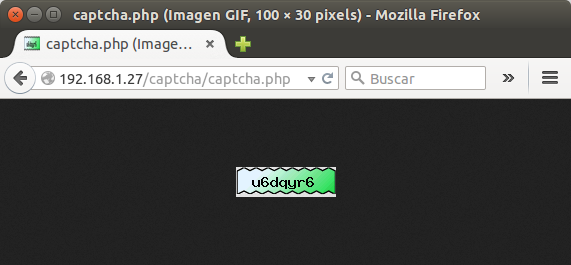
Cada vez que pulsamos CTRL+F5 nos mostrará una CAPTCHA diferente cada vez y asigna a la variable «$_SESSION[‘tmptxt’]» el valor deberá comparar con el valor introducido por el usuario humano. El siguiente paso es hacer la interfaz para la presentación e introducción de los datos.
Formulario web «captchademo.php».
El uso básico de sesiones bajo PHP está explicado en detalle en este enlace. No obstante buscando la simplicidad para la comprensión de todos ustedes, amables y pacientes lectores, haremos un archivo php para mostrar la CAPTCHA e introducir la respuesta del usuario y otro archivo php donde compararemos la respuesta; a este archivo lo llamaremos «captchaanswer.php» y esta explicado más adelante.
Sin más pretensiones de seguridad ni estética escribiremos el siguiente código:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>CAPTCHA con PHP</title>
<meta name="description" content="CAPTCHA con PHP: ejemplo para demostrar la creacion de Captcha con PHP." />
</head>
<body>
<table width="100%" border="0" cellspacing="0" cellpadding="0">
<tr>
<td align="center">
<strong>CAPTCHA con PHP </strong><br>
Ingresar el texto mostrado en la imagen: <br>
<form action="captchaanswer.php" method="post">
<img src="captcha.php" width="100" height="30" vspace="3"><br>
<input name="tmptxt" type="text" size="30"><br>
<input name="btget" type="submit" class="boton" value="Enviar">
<input name="action" type="hidden" value="checkdata">
</form>
</td>
</tr>
</table>
</body>
</html>
Al navegar nuestro servidor de prueba podrán ver algo parecido a esto:
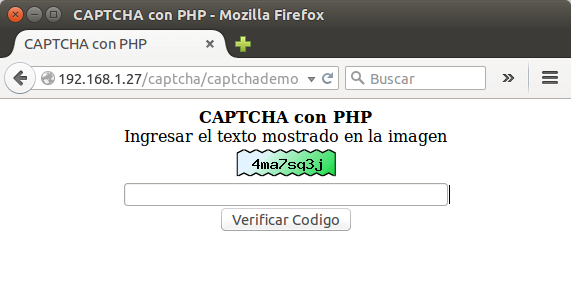 Todo el código anterior es puro lenguaje HTML y mencionaré brevemente línea por línea y su cierre correspondiente (nota: los términos que usaré para describir lo que sucede probablemente hiera la sensibilidad académica de algún lector, no obstante recuerdenme y escríbanme si estoy equivocado) :
Todo el código anterior es puro lenguaje HTML y mencionaré brevemente línea por línea y su cierre correspondiente (nota: los términos que usaré para describir lo que sucede probablemente hiera la sensibilidad académica de algún lector, no obstante recuerdenme y escríbanme si estoy equivocado) :
- Etiquetas «<html>…</html>»: le indica a nuestro servidor dónde comienza y dónde termina el lenguaje HTML, veremos en una entrada futura que esto es esencialmente útil en nuestros «scripts php».
- Etiquetas «<head>…</head>»: contiene información prioritaria que nuestro servidor tendrá que darle tratamiento especial, leer próximo punto.
- Etiquetas «<meta (…) />»: estas etiquetas contienen datos que describen datos y están categorizados. La categoría «Content-Type» la describimos anteriormente pero en esta ocasión la usaremos para decirle al navegador del cliente que la vamos a enviar lenguaje HTML y que lo interprete como tal. Envuelve mayor complejidad una solicitud HTTP pues incluye códigos numéricos de respuesta y aceptación pero con saber que esta información es una de las primeras que se envían es más que suficiente.
- También en los metadatos podemos incluir la codificación de caracteres utilizados en la página web (algún día cuando usemos todo en 128 bits esto caerá en desuso) por medio del comando «UTF-8».
- Hay ciertas palabras claves reservadas en los metadatos y es lenguaje de alto nivel, el que usamos usted y yo, seres humanos. Uno de ellos es la palabra name=»description» que nos permite especificar a manera general el propósito principal de la página.
- En este punto es útil preguntarnos ¿para qué es todo esto del encabezado? Para ello debemos recordar que hace 20 años el ancho de banda en internet era «oro en polvo» y el protocolo se diseñó para no cargar la página completa de un solo golpe sino que echaramos «un ojo» antes de descargar completo. Hoy en día se ha vuelto obsoleto (yo escucho una radio por internet, mientras corro una máquina virtual que actualiza su software desde varios repositorios y otra máquina virtual «baja» parches de seguridad mientras escribo estas líneas ‘en línea’ y además de tanto en tanto superviso servidores de datos remotos; el tráfico de datos es asombroso) pero aún sigue siendo útil para las «arañas» o buscadores como https://duckduckgo.com/ a fin de categorizar las páginas web visitadas y de las cuales hasta guardan una copia espejo, datos, datos y más datos; discos duros a reventar (alguien dijo alguna vez «lo que se sube a internet allí se queda», yo lo creo fehacientemente 😯 ).
- Con las etiquetas «<title>…</title>», valga la redundancia, titulamos nuestra página (el «caption» de la ventana) y algunos navegadores agregan su propio nombre como pueden ver el ejemplo mostrado.
- Dentro de las etiquetas «<body>…</body>» insertaremos la página web en sí, sólo que en este caso es un formulario para mostrar e introducir los datos.
- Con «<table><tr><td>…</td></tr></table>» dibujaremos una tabla de un solo cuadro ayudados por el concepto de anidación de etiquetas ¿recuerdan el método de la «doble C» para dividir fracciones? Pues bueno es algo parecido a eso.
- Con «<strong>…</strong>» podremos poner en negritas lo escrito entre las etiquetas.
- Con «<br>» le decimos al navegador que termina una línea y comience una nueva.
- He aquí lo más importante: «<form>…</form>». Allí declaramos y establecemos los elementos del formulario en sí.
- Con form <form action=»captchaanswer.php» method=»POST»> indicamos que las variables siguientes sean pasadas a otro «script php» con el método «POST» para que el usuario no visualize las variables(a diferencia del método «GET»).
- He aquí la «magia»: al pasar la orden de visualizar la imagen CAPTCHA realmente le indicamos es que ejecute el «script»: <img src=»captcha.php» width=»100″ height=»30″ vspace=»3″> y que lo muestre como tal (con ayuda de «header()»).
- Los demás elementos son para dibujar el cuadro de texto y el botón enviar, creo no merecen mayor explicación.
- Las normas estéticas las agregaremos en una próxima entrada pero de manera normalizada, como el tema es largo y quiero escribirlo desde hace tiempo le dedicaré una entrada aparte.
Actualizado el lunes 22 de febrero de 2016.
Para prevenir que los servidores proxy instalados en redes de área local NO guarden en caché la imagen de nuestro CAPTCHA podemos hacer uso de generar diferentes nombres al «archivo» de imagen misma con, por ejemplo, la función uniquid de la siguiente manera:
<?php
echo "<img src='";
echo uniqid("captcha", true);
echo ".php' width='100' height='30' vspace='3'><br>";
?>
Formulario web «captchaanswer.php»
Como ustedes pueden ver loq ue yo llamo «formularios web» o «páginas web» en este servidor LAPP son en realidad unos «scripts» en lenguaje PHP. El que nos ocupa ahora es el que se invoca cuando el usuario pulsa el botón «Enviar»:
<?php
session_start();
if ($_POST['action'] == "checkdata") {
if ($_SESSION['tmptxt'] == $_POST['tmptxt']) {
echo "Bienvenido.";
} else {
echo "Intentalo nuevamente.";
}
exit;
}
?>
De nuevo lo analizamos línea por línea obviando, por supuesto, las funciones y comandos que de nuevo encontremos y hayamos explicado antes:
- Es necesario llamar a la función «session_start()», recordemos dicha función también nos permite recuperar los datos de la sesión almacenados en la variable global.
- La próxima acción es verificar que la variable ‘action’ esté establecida a ‘checkdata’ de no ser así pues simplemente finaliza y sale sin aviso alguno.
- El punto decisivo es la comparación de la cadena aleatoria creada por el script «captcha.php» y compararla con la enviada por el usuario. De ser iguales emite el mensaje «BIENVENIDO» y aquí es donde podemos ubicar el código que nos interesa: la publicación de un comentario a una entrada de blog, la confirmación a una lista de correos, etc.
Conclusiones.
Esto es sólo un abreboca de lo que podemos realizar con PHP en cuanto a gráficos se refiere, estoy consciente que para las normas actuales es un CAPTCHA bastante débil pero lo podemos mejorar hasta llevarlo a un nivel básico. Para mi caso particular lo voy a implementar de una vez en un «servidor de producción» y que trabaje de una vez.
Lecturas adicionales
En idioma castellano
En idioma inglés
<Eso es todo, por ahora>.