
Aún utilizo Lubuntu 18 x86 y trae LXterminal únicamente y por defecto. La idea es hacer la distribución lo más ligera posible, el problema es que dicha terminal presenta un inconveniente, veamos.

Aún utilizo Lubuntu 18 x86 y trae LXterminal únicamente y por defecto. La idea es hacer la distribución lo más ligera posible, el problema es que dicha terminal presenta un inconveniente, veamos.

En esta entrada veremos cómo agregar usuarios para delegar la responsabilidad de administrar un servidor CentOS 7. Aunque está basado para realizarlo con el proveedor DigitalOcean, nada impide que lo puedan hacer en sus propias máquinas físicas (bare-metal). Veamos.


Laravel es un entorno de trabajo escrito en lenguaje PHP bajo licencia de código abierto que ofrece un conjunto de herramientas y recursos para construir modernas aplicaciones en PHP. Con un completo ecosistema aprovechando sus características integradas, la popularidad de Laravel ha crecido rápidamente en los últimos años, con muchos desarrolladores adoptándolo como su entorno de trabajo preferido para un proceso de desarrollo simplificado.
En este artículo usted instalará y configurará una nueva aplicación de Laravel en un servidor Ubuntu versión 18.04, usando Composer (software) para descargar y administrar las librerías del entorno de trabajo. Cuando usted finalice tendrá una aplicación demostrativa totalmente funcional, la cual obtiene información desde una base de datos MySQL.

Como dijimos, tuvimos que hacer una instalación nueva en un disco duro pequeño para el año en curso y la instalación fue mínima por lo que al utilizar gucharmap notamos que muchísimos de los caracteres no estaban representados…
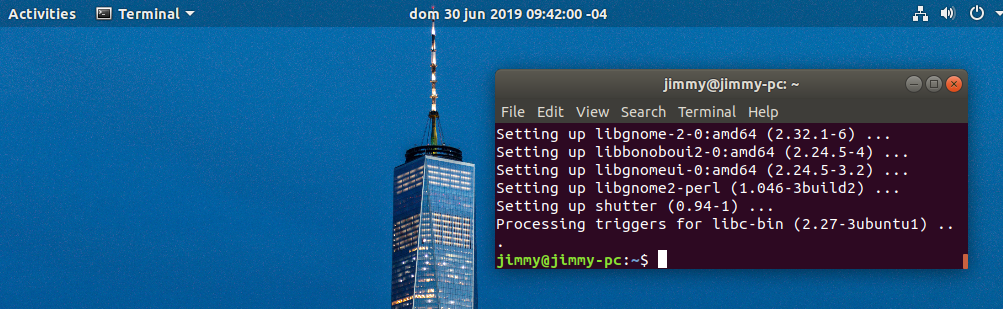
Somos gente práctica y sencilla y una de las cosas con las que estamos en desacuerdo en Ubuntu 18.04 es el formato de la hora («bandeja del sistema») el cual no permite ser personalizado por nosotros, en esta entrada explicamos como cambiar esa característica.
Actualizado el viernes 3 de julio de 2020
En una entrada anterior explicamos como instalar Shutter en Ubuntu 18 (por cierto nuestra distribución favorita) como herramienta auxiliar de Tesseract OCR, así como también en Fedora 25. Ahora vamos a explicar como lo instalamos en Lubuntu 18.04, incluyendo ciertos tropiezos que tuvimos en el camino.

Esta entrada debimos haberla publicada desde hace tiempo, así que mejor tarde que nunca. Aprovechamos la oportunidad de traducir lo publicado en Nixcraft y además nuestro propio artículo sobre BASH, veamos entonces.
GNU/ Linux
Ubuntu.

Con Ubuntu 17.10 Artful Aardvark reiniciamos las 26 letras del abecedario inglés, como vemos en la siguiente lista, se conserva cierto orden, si se quiere llamar de esa manera, a las diferentes versiones que a lo largo de los años ha tenido esta popular distribución derivada de Debian.
Seguir leyendo
 (No Ratings Yet)
(No Ratings Yet)![]() Cargando…
Cargando…
Yo renombraría esta utilería como «e-Speak», un apócope de «Electronic Speak» porque para nosotros los castellanohablantes nos suena como un «espanglish«, pero bueno, así se llama «eSpeak» (así nos confunda) ¿Y qué hace este software? Pues simplemente nos «habla» el texto que querramos y es especialmente útil para añadir ayuda auditiva para los discapacitados visuales en nuestros programas. La imagen de los labios la he sacado de su propio sitio web, el programa es de los años 90 y las gráficas se necesitaban así, ligeras y toscas (por extensión a la licencia imagino la imagen será de dominio público, en todo caso siempre enlazamos dando crédito de autoría). Acá haremos unas simples líneas de comando (nosotros siempre usando solo la venta terminal ¡cuándo no es pascua en diciembre!) así que disfrutad de nuestra primera entrada de agosto de 2017.

Cuando tuvimos que actualizar nuestros conocimientos sobre Diseño Asistido por Computadora (CAD) nuestra experiencia era limitada y amarrada al software privativo Autocad® y como estamos decididos a ser libres nos decantamos por Freecad para realizar nuestro trabajo. Comenzamos así nuestro aprendizaje, que sobre el tema abunda en internet pero quien de inmediato llamó nuestra atención por su trabajo estructurado y paciente fue «ObiJuan» González y su Escuela de Padawan’s «CloneWars». Por ello cuando tuvimos noticias de que se le había otorgado el premio de Google llamado O’Reilly Open Source Award en reconocimiento a su labor (aunque es tonto de nuestra parte) nos contentamos en sumo grado y de que no solamente el Software Libre esté en tan alto nivel en España sino que también el HARDWARE LIBRE está surgiendo en América tutelado por (a pocas personas llamamos por su título, y por sus títulos menos) el Ingeniero y Doctor Juan González Gómez.
Muchas gracias a todos 🙂 #clonewars #FPGAwars pic.twitter.com/wY3pWBGoQB
— Juan Gonzalez (@Obijuan_cube) 11 de mayo de 2017
Nuestro voto para los O'Reilly #OpenSource Awards 2017
es para @Obijuan_cube, por su tenacidad #ObijuanSeLoMerece.https://t.co/dAbjFZB8Sh pic.twitter.com/RgtFeW9JkI— ks7000.net.ve💾🇻🇪😷🏡 (@ks7000) 15 de febrero de 2017
El jueves 11 de mayo en Austin (Estados Unidos), durante la celebración del congreso mundial OSCON, fue entregado el premio O’Reilly 2017. Fueron creados en el año 2005 por Tim O’Reilly y hasta el 2009 llevaban el prefijo Google-O’Reilly pero hasta la fecha de hoy simplemente lleva el nombre O’Reilly Open Source Award: un reconocimiento a los individuos por su dedicación, innovación, liderazgo y destacada contribución al código abierto.
Open source award winners#OSCON2017 #CDKtoOSCON pic.twitter.com/9LZh1BakNO
— Senthil SP (@senthilaru) 11 de mayo de 2017
El premio, creado y organizado por Google en colaboración con la factoría de Tim O’Reilly, desde el 2005, se entregó este jueves 11 de mayo en Austin (Estados Unidos) durante la celebración del congreso mundial OSCON, evento que reúne a toda la comunidad de ingenieros y desarrolladores de software y hardware libre.
Es así que ObiJuán se ha ganado su hito en la muy famosa Wikipedia (hasta que Skynet? cobre conciencia de sí misma y borre nuestra adición de los ganadores del año 2017 en esa página, ja, ja, ja).
Ni os imagináis la ilusión que me hace aparecer en wikipedia?Este es el mayor de los premios¡Muchas gracias a todos!https://t.co/wgUTcNScTP
— Juan Gonzalez (@Obijuan_cube) 18 de mayo de 2017
Eterno empedernido de la saga de películas «La Guerra de las Galaxias «Star Wars»» -¡ejem! nosotros también ?- se autodenomina por este juego de pronunciación en inglés y castellano del Maestro Jedi de los films Obi-Wan Kenobi como ObiJuán (nosotros castellanizamos aún más las cosas con la inclusión del acento) este madrileño ejemplar comenzó sus andanzas …
¡Este blog no va de ciencias sociales! No somos biógrafos de profesión, nuestra intención es dar justo reconocimiento al que «sabemos que sabe»; los lectores de este humilde portal y de nuestra cuenta Twitter pueden dar fe de que siempre reconocemos al que sabe más que nosotros y es así que aprendemos y luego difundimos el conocimiento adquirido. Sigamos pues, con nuestra entrada de hoy.
…comenzó sus andanzas en el servicio militar obligatorio («la mili») y es allí donde le «encasquetaron» el apodo por ser tan fanático de «Star Wars».
Hoy he notado una perturbación en la fuerza… muahahahahahahaha pic.twitter.com/YJ1iuR7H5o
— Juan Gonzalez (@Obijuan_cube) 22 de marzo de 2017
Ya desde el año 1996 «lidia» con Linux pero ya desde muy joven «lo que se le da» es lo de la informática. Sufrió lo mismo que Richard Stallman (y nosotros también desde los años 80): un mundo privativo donde te ofrecen «comprar, usar y desechar» * pero no preguntes cómo funciona*.
Uno de sus primeros cacharros fue ZX-Spectrum donde comenzó con el lenguaje BASIC (¿y quién no ha comenzado con ese lenguaje? ¡Ah, ahora los chavales estudian Python, menuda «paliza» para nosotros los vejetes!). Luego aprendió por su propia cuenta Pascal (¡ea, que yo tuve que pisar la universidad para poder aprender este lenguaje! ?) , C, Prolog, y ensamblador (eax, ebx, ebp y esp fueron sus grandes amigos). Luego al entrar en el mundo GNU/Linux reafirma C, y aprende C++ y Python.
Comenzó la universidad en 1991 y su primera obra fue el Sistema Tower Pro Tarjeta CT6811 para su sueño hecho realidad: el robot Tritt (que ya vendrá algún día el «Mazinger ?», porque ya el R2D2 lo tuvo… ¡como impresora 3D, con dinastía y todo!). De 1996 al 98 se dedica en cuerpo y alma -pesetas de por medio- al campo de los micro-robots y es cuando emprende su cruzada de hacer una España con un fuerte desarrollo endógeno para librarse de la dependencia tecnológica extranjera: producir y crear todo en su tierra natal (dichas batallas aún se libran fuertemente y se ganan poco a poco con muchísimo esfuerzo, solo que ahora no está solo, sus padawan‘s lo acompañan y apoyan).
En 2003 ya hablaba de los problemas del hardware libre mediante conferencia dictada en el VI Congreso de Hispalinux y llegó a la conclusión que son los planos de hardware son los que cumplen con las 4 premisas del software libre y por ende es así que debe ser considerado el hardware libre (ahora va de que preguntéis de dónde proviene el nombre GNU y obtendréis una respuesta enrevesada parecida).
En 2007-08 trabajó sobre un mando para wii y pudo lograr que controlara su robot Skybot, demostrando con ello que las empresas privativas tienen aún mucho más campo que cubrir si tan solo se dignaran a compartir el conocimiento.
Su «grito de guerra» es:
«Más vale proyecto publicado con licencia libre, que ciento en el cajón»
"Más vale proyecto publicado con licencia libre, que ciento en el cajón" #proverbioFriki
— Juan Gonzalez (@Obijuan_cube) 22 de septiembre de 2015
Y su lema es:
Patrimonio Tecnológico de la Humanidad: es que vamos a avanzar muchísimo más como Humanidad si compartimos el conocimiento! ¡Salimos ganando todos! La riqueza se va a distribuir muchísimo más… Esto se vio desde el principio en el mundo de la ciencia. Si tú no compartes lo que has descubierto, y te lo revisan otras personas, no avanzas, ya no es ciencia lo que haces.
Tuvo una fuerte influencia el trabajo del profesor Adrian Bowyer quien lanza al mundo la primera impresora para tercera dimensión «3D» a modo de hardware libre: fue desde entonces una revolución imparable en la cual ObiJuán se especializó y contribuyó -y seguirá aportando- en su conocimiento y masificación. Hasta ahora tiene construidas 270 impresoras 3D y podéis leer su trabajo en CloneWars en este enlace.
#CloneWars impresoras 3D que pueden auto-replicarse #freehardware #freesoftware https://t.co/HelCPI9xpy
— klaudia (@piruletaklo) 13 de mayo de 2017
Así mismo lleva un canal en Youtube con multitud de tutoriales donde explica y comparte con suma paciencia su conocimiento y experiencia, añadiéndole como siempre su toque personal:
El País con tu futuro: «#Robótica» por @Obijuan_cube https://t.co/hnbqMOm64r
— ks7000.net.ve ? (@ks7000) 28 de enero de 2017
ObiJuán es apasionado de la tecnología y en 2016 comezó su proyecto épico: la reconstrucción del CPU del «Apolo 11», el proyecto espacial de la NASA que llevó a nuestra humanidad a la Luna; la «paleoarquitectura» de los ordenadores, sin duda una tarea ardua. Escuchemos en palabras del propio ObiJuán el proyecto de marras:
Para él fue una bendición la tecnología que aportó Arduino en los años 90, fue como la revista «Mecánica Popular» aplicado al mundo de la electrónica. Si Arduino abrió la posibilidad de combinar los componentes y ponerlos a funcionar con los FPGAs (Field Programmable Gate Array) tendremos la posibilidad de construir nuestros propios «chips» y eso ahora mismo es lo que mantiene más ocupado a ObiJuán. Esto es así porque a pesar de todos los títulos universitarios que ha logrado, lo que le apasiona es construir y verificar por sus propios medios (vamos que la ciencia se han de replicar los mismo resultados en las mismas condiciones): es de los que crea y observa, basado en la teoría, pero la destreza manual es bien sabido que abre nuestros cerebros a nuevas conexiones sinápticas y nuevas formas y maneras de ver las cosas, ¡es de los que dicen «no me fío de lo que me dices o alegas, dejadme probar y comprobar»!
A ObiJuán no le gustan los agradecimientos; nosotros por estos lares tampoco (de hecho, debido a la dura situación de nuestro país hasta ahora es que aceptamos donaciones) pero cuando la obra es grande ES IMPOSIBLE QUE PASE DESAPERCIBIDA. Desde 1989 que comenzamos a estudiar en la Facultad de Ingeniería de la Universidad de Carabobo nuestro punto de difusión de conocimiento era el boulevard al lado del cafetín principal, AHORA LO ES EL INTERNET POR EL MUNDO ENTERO y aunque en esa época ya sabíamos que difundir el conocimiento era la clave, no es sino hasta hace poco -en serio y en firme desde el año 2014- que entramos en el mundo del saber del software libre. Pero he aquí que ObiJuán no solo usa y difunde el software libre, ¡EL HARDWARE LIBRE TAMBIÉN! Nos aventaja por largo rato, y además se involucra en persona en causas sociales ¿Cómo no reconocer su labor? ¡Sería una injusticia!
@Obijuan_cube Vaya hasta usted nuestro eterno agradecimiento por llevar el #SoftwareLibre y el #HardwareLibre "al infinito y más allá".? pic.twitter.com/AsQOpB4zGp
— ks7000.net.ve ? (@ks7000) 14 de mayo de 2017
Bien merecido galardón O’Reilly para @ObiJuan_cube González
El español @Obijuan_cube González,
galardonado en los O'ReillyOpenSourceAward
por su contribución al #SoftwareLibre:https://t.co/Q4LHu6huj0— ks7000.net.ve ? (@ks7000) 14 de mayo de 2017
« @Obijuan_cube » el primer madrileño nominado a los «oscars del #SoftwareLibre» https://t.co/gFJ2LkvSYp via @abc_es
— ks7000.net.ve ? (@ks7000) 14 de mayo de 2017
3 estudiantes #makers de bachillerato preparando entrevista a @Obijuan_cube sobre RepRap y Clone Wars. Aceptas?
— Carolina C (@Tecno_Logics) 18 de mayo de 2014
@Tecno_Logics Challenge accepted!
— Juan Gonzalez (@Obijuan_cube) 18 de mayo de 2014