Esta útil y práctica aplicación escrita en lenguaje Python permite ubicarnos de manera rápida en cada una de las terminales remotas que abramos. Y eso sin contar los usos en cuanto al protocolo Git y los resultados de los guiones de comandos o comandos que ejecutemos. Veamos.
Instalando Powerline en Ubuntu 25.10
sudo apt install powerline -y
Esta línea también instalará fonts-powerline el cual ha de ser necesario si trabajamos con una máquina remota: la máquina local ha de tener dichas fuentes de letras (mejor dicho tipografías):
sudo apt install fonts-powerline -y
Configurando Powerline
En teoría esto vale para cualquier GNU/Linux… Editamos el archivo:
nano ~/.bashrc
Y agregamos al final:
if [ -f /usr/share/powerline/bindings/bash/powerline.sh ]; then source /usr/share/powerline/bindings/bash/powerline.sh fi
Cerrar sesión y al volver a conectar tendremos empoderada nuestra ventana terminal.
Como tal vez sepamos, con este último wget y el parámetro –mirror bien podemos realizar un sitio web espejo. El asunto está en que si necesitamos extraer datos específicos y en hacerlo plenamente funcional sustituyendo el motor que lo publica pues para eso es esta entrada. Veamos.
En el campo de la ingeniería muchas veces necesitamos números al azar ya sea dentro de un conjunto acotado o libremente. Son muy útiles para comprobar funciones matemáticas que hemos «creado» a partir de datos recabados («dos puntos definen una linea recta, tres puntos definen un plano», etcétera). Veamos cómo lograr eso con Python.
Python es un lenguaje de programación flexible y versátil que puede ser aprovechado para muchos caso, especialmente en guiones, automatización, análisis de datos, aprendizaje automático y desarrollo en infraestructuras que soportan servicios. Fue publicado por primera vez en 1991 con un nombre inspirado por el grupo de comedia Monty Python, ya que el equipo de desarrollo quería hacer de Python un lenguaje de programación que fuera divertido de usar. Rápido para ser configurado y escrito en un estilo relativamente sencillo con retorno inmediato de errores, Python es una gran opción tanto para desarrolladores principiantes y avanzados. Python 3 es la versión más reciente de este lenguaje y es considerado su futura opción.
Este tutorial le permitirá tener configurado un servidor Ubuntu 18.04 con un entorno de programación para Python 3. El programar sobre un servidor tiene muchas ventajas y ofrece apoyo en la colaboración a través de varios proyectos en desarrollo. Los principios generales expuestos en este tutorial son válidos para ser hechos bajo cualquier distribución Linux basada en Debian.
Este asunto tenía tiempo en nuestras mentes hasta que este vuestro sitio web estuvo «caído» durante varias horas debido a que nuestro propio proveedor de alojamiento web decidió instalar los certificados necesarios para poder establecer comunicaciones seguras y encriptadas entre los navegantes y nuestro servidor web (TLS o https, como quieran verlo). Por cierto que lo recibimos, dicho servicio, con mucho gusto y justificamos el tiempo fuera de línea debido a este evento (todo esto lo especulamos porque aún no hemos recibido un comunicado explícito al respecto).
Python logo original
En todo caso el tema va, y debió haber ido (publicado) hace muchísimo tiempo por estos lares, mejor tarde que nunca, aquí vamos.
El día de ayer por medio del perfil de línea de tiempo del Doctor Juan González observamos el interesante artículo tutorial sobre Python publicado por Juan J. Merelo Guervós el cual incluye retos de programación. Ni tardo ni perezoso, a pesar de llegar cansado a mi hogar, y tras una vigorizante taza de café negro con leche de avena sin azúcar nos dimos a la tarea de practicar algunas cositas para mantener el cerebro en forma y al día con las novedades en programación.
Desde hace tiempo venimos utilizando nuestro propio robot (o «bot» como es la moda ahora mentarlos) para promocionar esta nuestra y vuestra humilde página web por Twitter y la verdad es que no habíamos prestado mayor atención al trabajo hecho con la librería que permite hacerlo. Utilizamos Twitter por su simplicidad y el soporte que tenía por medio de mensajes de texto «Short Message Service SMS«a los móviles celulares: sencillo y elegante. Pero mejor estructuremos esta entrada para explicaros (y compartir) nuestro conocimento acerca del tema ¡Vengan con nosotros en este nuevo registro en la bitácora!
Breve historia del Twitter.
Que no os vamos a aburrir mucho con esto, pero por algo se empieza. Como preludio consideramos justo reconocer que los creadores de Twitter debe haberse inspirado en algún momento en el famoso protocolo de comunicaciones llamado «Internet Relay Chat IRC» el cual fue creado en 1988 por Jarkko Oikarinen y que tuvo su apogeo en el año 2004 con el popular juego de acción QuakeNet (240 mil usuarios -solo esa red, a nivel mundial hay muchas otras redes de usuarios-). Desde ese año el IRC ha ido declinando en el número de usuarios y llegado el año 2006 Jack Dorsey, Noah Glass, Biz Stone y Evan Williams fundan Twitter y en seis años consiguen 100 millones de usuarios que «tuiteaban» 340 millones de mensajes diarios. Inicialmente no fue pensada como una red social sino como un blog que utilizaría los mensajes de texto por teléfono móvil y debido a su limitación de 140 caracteres se convirtió de facto en un microblogging.
Nosotros usamos Twitter desde el año 2011, justo un año después de haber comenzado a utilizar la tecnología OAuth -desarrollada en las entrañas de Twitter desde el mismo año de su nacimiento en el 2006- para ganar seguridad y libertad de programación a aplicaciones de terceros con una «Application Programming Interface API«. Acá en Venezuela el operador Movistar (antes conocida como Telcel) daba soporte para enviar mensajes al Twitter por medio de mensajes de texto al número 89338 (TWEET) y funcionaba de maravillas pero actualmente no prestan el servicio, imaginamos que por falta de arreglo económico entre ambas empresas, recordad que nadie trabaja gratis (sin embargo se ganan una buena pasta vendiendonos megabytes de datos que usamos en Twitter). Otro aspecto del impacto de Twitter en nuestra vida diaria es la inclusión del verbo «tuitear» en el Diccionario Castellano de la Real Academia Española así que si en adelante no lo incluimos entre comillas pues ya veis que es «legal» usarlo así ya que es un anglicismo formalmente reconocido (¡qué fuertes son los Poderes Fácticos del siglo XXI!).
Para aquellos que queréis saber más de la historia y funcionamiento del Twitter -en inglés, publicado en el año 2016 por Amelia Norton y creado por Andreas Schreiber en 2009- navegad hasta este sitio donde publica unas diapositivas digitales donde la primera mitad explica todo esto y más adelante entra en materia más profunda; está profusamente ilustrado y va paso a paso:
¿Que cómo era el Twitter antes del OAuth? Podéis leer este artículo publicado en el año 2009 donde dan cuenta de como «tuitear» por medio del comando curl:
¡Increíble! Fijaos que Twitter ni siquiera era una página segura (https) y el usuario y contraseña viajaban libres por la red ¡eran otros tiempos, éramos más confiados (y con menos preocupaciones)! (Gracias Nacho por tu explicación, como veís 8 años después tus palabras aún resuenan en el ciberespacio). Acá otro artículo comentan como, incluso, como «tuitear» con PHP y curl y analizar la respuesta en formato tanto en formato XML como JSON.
Pero he aquí que ya el Sr. Nacho explicaba como utilizar el lenguaje Python con las librerías del sr. Mike Verdone creador de la «Python Twitter Tools PTT«, un software de código abierto y apoyado plenamente por la Fundación Python, y éste es el artículo principal de esta entrada.
«Python Twitter Tools PTT» por Mike Verdone.
Funcionamiento básico de la red Twitter.
Twitter siempre ha utilizado el software libre para lograr sus propósitos y en un principio utilizaba MySql como manejador de base de datos, pero pronto le quedó pequeña para sus propósitos.
Lo que aquí expresamos es a grandes rasgos, no esperéis una explicación al detal de la tecnología usada por Twitter; lo expresamos a nuestra forma y entendimiento y lo plasmamos de la manera más simple posible y si cometemos algún error hacednolos saber por nuestra cuenta Twitter @ks7000.
Ahora Twitter utiliza Ruby on Rails en servidores Java con «Content Delivery Network CDN» distribuidos en todo el mundo y cada identificador de mensaje es único y tiene información acerca de su geolocalización para poder manejar la gran cantidad de información que se genera segundo a segundo. En el acortador de direcciones ubicado en http://t.co aparte de ahorrar espacio en los mensajes también revisa y detiene los enlaces maliciosos (páginas falsas, páginas con código dañino, etc) y en el servicio https://twimg.com/ permite almacenar las imágenes que acompañan el mensaje. También han incluido soporte para emoticons que en realidad es soporte para todos los caracteres que soporta el UNICODE, así como soporte para «gifs animados» (que en realidad son convertidos a formato MP4), así como transmisión de vídeo en vivo por Periscope y a futuro vienen muchos cambios más para mantener con vida esta red. Uno de los más redituables son los «Twitter Ads» que es publicidad personalizada ¡repetimos, nadie trabaja gratis!
Twitter y el software desarrollado por terceros.
El equipo de Twitter creó y desarrolló de manera abierta la tecnología OAuth para que aplicaciones de terceros puedan acceder a ciertas características de nuestra cuenta en Twitter sin necesidad de darle nuestra contraseña de cuenta. Esto se logra de la siguiente manera:
Un equipo de desarrolladores se unen y crean una cuenta en Twitter. Deben colocar, al menos, un número de teléfono celular para recibir por mensaje de texto la confirmación de apertura de la cuenta deseada, así es que al menos es una persona real a quien le pertenece el número telefónico y es responsable de dicha cuenta.
Si es un proyecto muy grande el siguiente paso más probable es que contacten a Twitter -en San Francisco si viven y trabajan en los Estados Unidos de América o en Dublín, Irlanda, para el resto de los países del mundo- para solicitar una cuenta verificada (las cuentas que son identificadas con un símbolo azul y tooltip que las anuncia). Twitter recomienda que para proyectos pequeños -que por supuesto tienen su propio dominio web- publiquen en su página web la cuenta twitter oficial -tal como nosotros hacemos acá-. Esta norma rige también para personalidades, artistas, políticos, páginas de los gobiernos, etc.
Una vez hayan configurado sus datos en Twitter hay un apartado que permite crear dos token llamados “Consumer Key” (Clave de Consumidor) y “Consumer Secret” (Secreto de Consumidor) que deben ser almacenados de forma segura por los desarrolladores de la futura aplicación (en PTT está almacenada en donde alojan el código fuente, GitHub). Un token no es más que una larga secuencia alfanumérica de caracteres regidos por fórmulas matemáticas que permiten identificar de manera unívoca un objeto de software.
Una vez obtenida la Clave del Consumidor la aplicación debe proveer un enlace hacia Twitter con la siguiente orden: «https://api.twitter.com/oauth/authorize?oauth_token=Consumer_Key». Si no hemos iniciado sesión en Twitter introduciremos nuestro usuario y contraseña la cual se la estamos entregando a Twitter por medio de una página web segura https, no a la aplicación en sí.
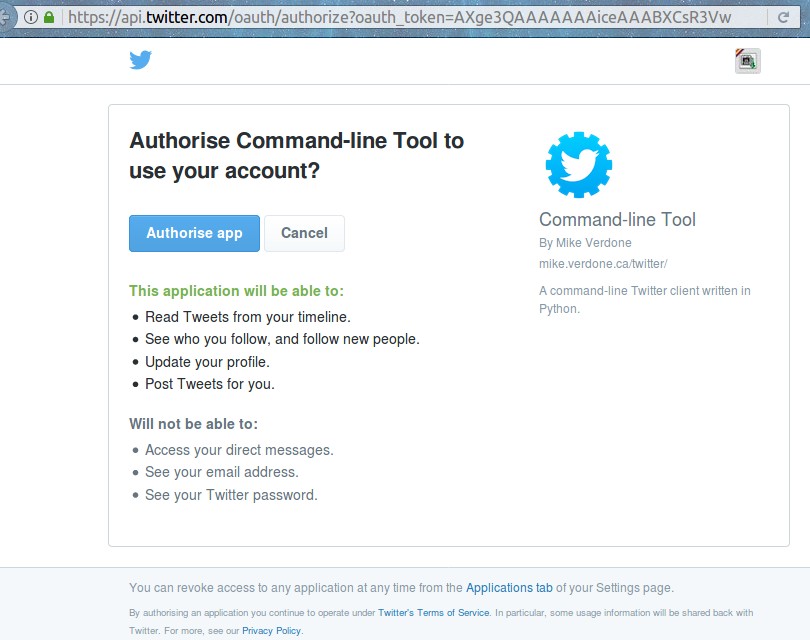
Una vez entramos en Twitter nos redirigirá a una página donde explica qué privilegios solicita la aplicación y y botón para aprobarla. Muy importante que leamos bien que derechos de acceso otorgamos, si estamos de acuerdo le damos aceptar.
Una vez que aprobamos Twitter genera a su vez otros dos token que son enviados a la aplicación que desea acceder a ciertos elementos de nuestra cuenta. Si la aplicación web está instalada en nuestro ordenador o dispositivo móvil por medio de un PIN que nos muestra Twitter por pantalla lo copiaremos y suministraremos a la aplicación para que ella obtenga por sus propios medios los dos token personalizados para nosotros y procederá a guardar en nuestra máquina. Si es una aplicación web se redirijirá la página y obtendrá ella misma los dos token necesarios.
El punto anterior funciona de dos maneras diferentes: en la aplicación instalada en nuestro ordenador o celular los token se almacenarán en nuestros equipos. Si es una aplicación web los token se almacenarán en el o los servidores de la aplicación. En el primer caso nosotros usaremos los 2 token personalizados -público y privado-, en el segundo caso será la aplicación de manera autónoma quien los usará -y nosotros nunca sabremos los valores de los token generados, a diferencia del primer método-.
En cualquier momento podemos eliminar el acceso a la aplicación si nos dirigimos a «https://twitter.com/settings/applications» y pulsamos el botón de revocar: esto simplemente hace que Twitter inactive los dos token que generamos y así negará el acceso a las partes de nuestra cuenta que habíamos autorizado.
Las partes de nuestras cuentas que podemos otorgar acceso son las siguientes (caso PTT):
Acceder a nuestra línea de tiempo (los tuits de las cuentas que seguimos).
Enviar mensajes públicos y/o privados con nuestra cuenta.
Permitir leer nuestros datos: avatar, nombre e incluso nuestro correo electrónico.
Seguir y/o dejar de seguir otras cuentas en Twitter.
Se ha hecho ya costumbre el crear estas aplicaciones simplemente para permitirnos emitir comentarios en las páginas web o por medio de varias páginas web que se afilien a esa aplicación: Disqus es un buen ejemplo de ello, son aplicaciones con una API basadas a su vez en las herramienta API de Twitter con el esquema de autorización OAuth.
Aunque logren acceder a nuestro ordenador o si nos roban o se pierde nuestro teléfono celular siempre podemos iniciar sesión en Twitter en cualquier otro equipo confiable y revocar el acceso a dichas aplicaciones: eso inutiliza los token personalizados que fueron generados.
Ya hemos publicado como instalar el lenguaje Python en nuestras máquinas, así que aquí solo escribiremos como instalar las utilerías desarrolladas por el sr. Mike Verdone. Debemos entonces referiros a otro de nuestros posts donde explicamos la clasificación de las funciones en Python: las que provienen de terceros deben instalarse con PIP. Hacemos notar por experiencia propia que GNU/Linux Debian Jessie 8.8 no trae instalado por defecto el pip.No hay problema, lo que debemos hacer es escribir -con derechos de administrador root ganados con su-:
apt-get install python-pip
Tras lo cual no solicitará que introduzcamos el DVD N° 1 (el 2° y el 3° contienen aún mucho más software pero menos utilizados) por lo que nos ahorramos el conectarnos a internet (por eso decimos que viene «instalado por defecto» en las distribuciones GNU/Linux). Una vez tengamos instalado el pip debemos lanzar la siguiente instrucción:
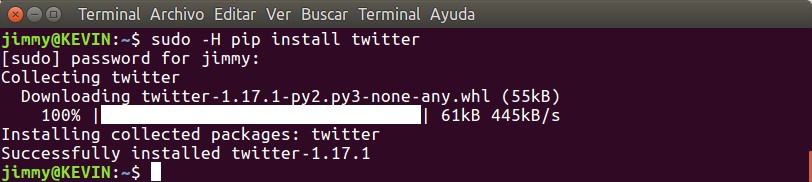
sudo -H pip install twitter
El parámetro -H en sudo (o, si gustan, –set-home) especifica que la política de seguridad sea fijada en el usuario actual que ejecuta el comando a efectos de registrar una entrada en la base de datos de contraseñas del usuario, aunque es la opción por defecto hay que recalcarsela cuando instalemos cualquier otro paquete con PIP. Acá podéis ver el resultado del comando, nos instala la última versión disponible a la fecha, la 1.17.1:
sudo -H pip install twitter
Comentarios de Mike Verdone sobre la versión 1.9.1
En enero de 2013 anunció la liberación de la versión 1.9.1 con las nuevas características para el momento pero lo que nos llamó la atención fue el siguiente comentario en el último párrafo en su blog:
At this point I rarely do dev work on Python Twitter Tools. I merely evaluate and merge the pull requests submitted by other talented developers. A great big thank you to all of them! Their names reside safely in the Git project history, for all eternity.
Que traducido al castellano sería más o menos lo siguiente:
En este momento raramente desarrollo trabajo en «Python Twitter Tools». Yo simplemente evaluo y uno las propuestas enviadas por otros talentosos programadores. ¡Un grandioso agradecimiento a todos y cada uno de ustedes! Sus nombres reposarán de forma segura en la historia del proyecto (en formato Git), por toda la eternidad.
Esto, para nosotros, es poesía para nuestros oídos y una muy buena apología al Software Libre, ¡Libertad!
Configurando PTT por primera vez.
El Python Twitter Tools viene conformado por dos componentes: las librerías en si mismas -que podremos usar si tenemos nuestras propios token otrogados por Twitter a traves de nuestra cuenta allí creada- y un archivo ejecutable llamado twitter que podremos llamar por medio de una ventana terminal.
Primero explicaremos como usar el ejecutable compilado con ayuda los token pertenecientes a Mike Verdone, es decir, vamos a autorizar única y exclusivamente al programa twitter que instalamos por medio de PIP para que interactue con nuestra cuenta en Twitter.
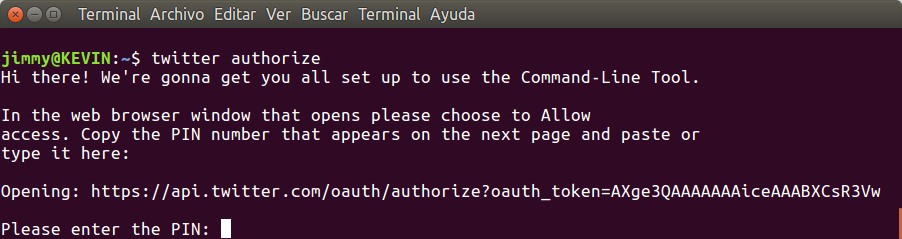
twitter authorize
Lanzamos una ventana terminal y escribimos simplemente «twitter authorize» lo cual hará que dicho software lance un navegador por el siguiente enlace:
Authorise Command-line Tool to use your account?
Notad que la página web es segura, «candado verde» (si no hemos iniciado sesión e Twitter, pues ingresad y la página se redirige) y que nos explica brevemente que accederá a leer los tuits que publican a quienes seguimos -esto es conocido como línea de tiempo o «timeline» en inglés-, ver la lista de quienes seguimos -y el permiso de seguir nuevas cuentas-, actualizar nuestro perfil cosa que nos sorprende ya que no vemos opciones documentadas para hacer esto (cambiar nuestro nombre, avatar, etc) lo cual investigaremos en detalle para qué quiere tener acceso a este renglón, y por último la habilidad de tuitear por nosotros de una manera automatizada (vamos a comenzar por esto último, enviar un mensaje al ciberespacio).
Una vez hallamos autorizado a la aplicación en la página del Twitter nos mostrará un PIN el cual fue pensado para aplicaciones que no tienen una interfaz web -léase aplicaciones de líneas de comandos- al cual el PTT llama con un argumento distinto al comando oauth_callback (toma el valor oob «out-of-band»). Dicho PIN debemos introducirlo en la entrada que requiere PTT tras lo cual se comunicará -vía curl, imaginamos– con Twitter para obtener nuestros token personalizados que serán almacenados en la siguiente ubicación: ~/.twitter_oauth (un archivo oculto en nuestra carpeta personal «home»).
Una vez hallamos configurado adecuadamente la aplicación, no tenemos mas que escribir nuestro primer mensaje por medio de PTT: «twitter set» tras lo cual pedirá que ingresemos nuestro mensaje, presionamos intro y listo, se fue al universo del microblogging nuestra prueba:
Usando PTT (agradecimiento incluido):
Mit süßen «Python Twitter Werkzeuge» des @sixohsix.
Este mensaje lo enviamos el día 20 de mayo de 2017, cuando publicamos esta entrada (nosotros publicamos cuando consideramos tenemos algo suficientemente redactado, luego lo refinamos y con el paso del tiempo lo mantenemos actualizadas cada una de nuestras entradas en nuestro blog). En ese mensaje recibimos un «me gusta» por parte del usuario @sixohsix (ya comentamos que toda aplicación web de Twitter debe tener, por supuesto, una cuenta en Twitter).
Revisando cada una de las acciones de PTT.
Seguimos revisando la aplicación compilada twitter por la línea de comando, luego veremos el uso de las utilerías y programaremos. Para PTT es necesario tener instalado argparse –que ya os hemos explicado como funciona– y es la que permite introducir «twitter -h» para saber sus acciones y preferencias. De número uno la opción por defecto es la que estudiaremos.
«twitter» ó «twitter friends».
Al escribir «twitter» estamos invocando en realidad «twitter friends«: esto devuelve por pantalla los mensajes o tuits -incluyendo los retuits- de las cuenta a las cuales seguimos. Recordad que vuestra velocidad de conexión al internet influirá en la respuesta, paciencia que puede tomar cierto tiempo.
Como nosotros vamos de programación, y por ende de tareas automatizadas, el primer uso que le vamos a dar es filtrar resultados con grep mediante el comando tubería. Lo que vamos a buscar son los tuits que contengan la palabra -valga la publicidad- «Samsung» utilizando la salida stdout al comando de filtrado grep de la siguiente manera:
twitter friends | grep «Samsung»
Primero notad que debemos acostumbrarnos a entrecomillar siempre la clave a buscar ya que Twitter utiliza etiquetas cuyo prefijo es el caracter numeral «#» el cual significa comentario en el shell bash.
«twitter help» ó «twitter -h».
Por supuesto esta opción es insoslayable: retribuye las opciones documentadas o declaradas (como tenemos acceso al código fuente podremos estudiar y buscar opciones no documentadas debidamente).
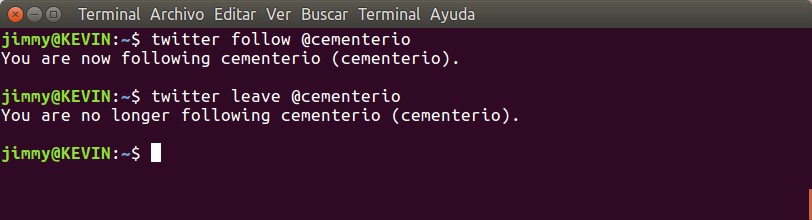
«twitter follow» y «twitter leave».
Recordemos que le dimos permiso a la aplicación de seguir o dejar de seguir otra cuenta en Twitter, así que para seguir una cuenta escribimos «twitter follow@nombre_de_la_cuenta» y para dejar de seguirla «twitter leave @nombre_de_la_cuenta«. Nosotros la probamos con @cementerio una cuenta argentina que se dedica a emitir día a día el fallecimiento tanto de personajes famosos a nivel mundial como a nivel local, mirad la imagen:
twitter follow y twitter leave
«twitter list» y «twitter mylist».
Una lista en Twitter simplemente es un conjunto de cuentas que agrupamos según un criterio definido, en nuestro caso clasificamos a los desarrolladores de software por cada país del mundo. Las listas pueden ser públicas como privadas así que si vemos alguna cuenta que NO sigue a nadie no necesariamente quiere decir que sea una cuenta inactiva, tal vez tenga una lista privada para recibir información de manera discreta. Con «twitter list @nombre_de_usuario» podremos obtener los nombres de las listas públicas de un usuario de Twitter, lo estemos siguiendo o no (por supuesto, si no lo seguimos y su perfil es público). De lo contrario, si la cuenta está «protegida» (perfil privado) devolverá el error 34 con el mensaje «‘Sorry, that page does not exist.«; esto es así por la máxima privacidad al usuario: cuando le preguntamos al Twitter éste lo niega, incluso su existencia (es decir, no anuncia que la cuenta es privada). De esta opción hicimos pruebas pero no publicamos las cuentas protegidas que consultamos para conservar la privacidad pero hemos de deciros que funciona a la perfección (si acaso podríamos hacer un «fork» para el tratamiento de mensajes de error, -vamos a ver hasta dónde llegamos-). Con la opción mylist y como son nuestras propias listas, obtendremos tanto listas públicas como privadas.
«twitter replies».
Con este comando nos retribuye las últimas respuestas a nuestros tuits -primero los más antiguos-, valga decir que son mensajes que se hilan en una nueva conversación o en una existente. En Twitter esto es como un árbol con la raíz invertida: si solo son dos usuarios es una linea directa de conversación pero si varios usuarios intervienen entonces se convierte en un árbol. Es de notar, por supuesto, que si uno opta por silenciar «mute» una conversación, ya no recibiremos aviso alguno de la misma.
«twitter search».
Al nosotros utilizar esta opción de inmediato nos devolvió error (y no, no es por incluir el «octothorpe» o símbolo numeral que tiene un signficado especial en Python). El error está «denunciado» en este enlace y en la medida de lo posible estamos revisando el código para ver si podemos ayudar en algo.
«twitter shell».
Todos los argumentos que acabamos de ver los ejecutamos directamente de la consola de nuestra distribución GNU/Linux pero si usamos «twitter.shell» entraremos en el prompt del propio PTT: así podremos escribir «set ‘mensaje'», presionar intro y enviamos nuestro mensaje. Es decir, nos ahorramos la palabra «twitter» en cada llamado.
Para salir del shell del PTT solo debemos pulsar la tecla CTRL+D tras lo cual preguntará la aplicación «You really want to Leave (Y/n)? » y pulsamos la tecla «Y», presionamos intro y «salimos» al shell de nuestro ordenador.
«twitter rate».
Así como hay un límite máximo de 100 tuits por hora para cada cuenta en Twitter (si emitimos 100 tuits en 100 segundos -un minuto y cuarenta segundos- estaremos bloqueados por una hora más o menos) también hay unos límites en las tareas automatizadas. Cada límite está establecido para cada uno de los métodos establecidos en la API y sería largo de enumerar aquí; algo relevante es que dichos valores se «reinician» cada 900 segundos, osea cada 30 minutos. Como veís, es muy similar al límite que comentamos al principio, solo que el bloqueo dura media hora en vez de una hora completa.
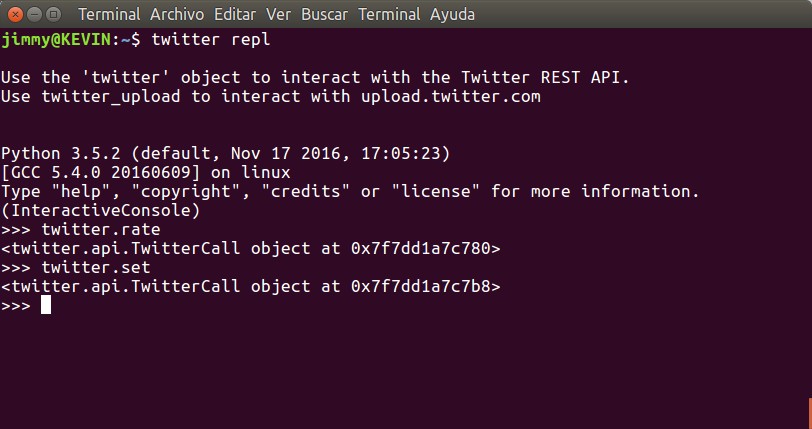
«twitter repl».
Con este comando entraremos en una ventana normal de Python pero con un mensaje de bienvenida que es más que elocuente:
twitter repl
En el anuncio nos indica que por medio del objeto «twitter» (declarado y conectado por un script o guion previo) podremos interactuar con la REST API lo cual consideramos algo avanzado y creemos con propósitos de depuración a bajo nivel. Para salir usamos CTRL+D, recuerden que estamos en Python terminal. Por ahora no le encotramos mayor utilidad y lo dejamos tranquilo para pasar al otro comando que nos parece tremendamente útil.
«twitter pyprompt»
Esto si lo consideramos muy útil y sirve como paso previo antes de comenzar nuestros ejemplos y pruebas con las librerías en sí mismas: si con twitter shell podemos escribir solo los comandos (set, rate, etc.) con este comando tendremos un objeto «twitter» declarado y conectado con el cual podremos programar aspectos más vanzados, como por ejemplo tuitear incluyendo imágenes. La diferencia principal es que estaremos conectados con los token que autorizamos (¿recuerda «twitter authorize»?) y podemos programar a nuestras anchas, en cambio al lanzar Pythom e importar la librería debemos nosotros mismos sumistrar los 4 elementos completos:
token (del lado de la aplicación registrada en Twitter).
token_secret (del lado de la aplicación registrada en Twitter ¡estricto cuidado NO difundir!).
consumer_key (del lado nuestro, los token que solicitamos y autorizamos).
consumer_secret (del lado nuestro, los token que solicitamos y autorizamos ¡estricto cuidado NO difundir!).
Si a la final metemos la pata y hacemos pública nuestro token privado de cliente, pues iniciamos sesión en Twitter y revocamos el acceso a la aplicación. Si somos desarrolladores y hacemos pública nuestro token privado de aplicación (tal como hizo PTT) pues vamos con la cuenta twitter con que creamos la aplicación y le revocamos el acceso. Como veís la seguridad está en parte garantizada y Twitter feliz de la vida delegando esas responsabilidades en nosotros: ellos ponen la maquinaria, nosotros la mano de obra.
Preferencias u opciones de PTT.
De las acciones que estudiamos anteriormente, estas preferencias son compatibles con todas ellas, comenzemos por «–refresh».
Opción «-r» ó «–refresh».
Cuando utilizamos el comando grep para filtrar resultados -de una manera «rudimentaria» bien pensamos agregar el comando al crontab de nuestro sistema GNU/Linux pero no es necesario llegar a tanto. Para ello contamos con la opción «-r» ó «–refresh» para que el comando que corriendo indefinidamente hasta que presiones CTRL+C para interrumpir el proceso. De manera predeterminada el intervalo es de 5 minutos (300 segundos) pero con la opción «-R» ó «–refresh-rate» podemos especificarle un valor en segundos que querramos -e incluso programar para que sea un valor aleatorio-. De las pruebas que hicimos nos dimos cuenta que valores inferiores a 60 segundos devuelve error el Twitter: recordad que no debemos sobrecargar a los servidores de dicha empresa con solicitudes tan frecuentes.
twitter friends –refresh
Opción «-l» ó «–length».
Otro valor por defecto es el número de mensajes retribuidos, el valor normal es 20 pero podemos pedir uno solo o el que queramos pero con un maximo de 200 mensajes o tuits. Como por consola es difícil ver dónde termina y dónde comienza cada mensaje la siguiente opción nos permitirá contar de lo lindo el número de tuits retribuidos a ver si es verda que se ejecuta tal como lo pedimos.
Opciones «-t» ó «–timestamp» y «-d» ó «–datestamp».
Con estas opciones podremos colocar tanto la hora y minuto como la fecha de cada mensaje, algo útil si queremos guardar los datos en una tabla de base dedatos y ordenarlos luego de forma cronológica. Atención: la hora y fecha de cada mensaje es, por supuesto, cuando lo emitieron originalmente pero cuando alguien a quien nosotros seguimos lo retuitea -o reenvía- nos mostrará fecha y hora del retuiteo, no de la hora y fecha original.
Opción «–no-ssl».
Esta opción de facto está eliminada: toda transacción hoy en día con los servidores de la empresa Twitter solamente están disponibles en formato segor https: toda nuestra información viaja cifrada entre nosotros y Twitter.
Opción «c» ó «–config».
Si decidimos almacenar nuestro usuario y contraseña en un archivo con esta informacón la podemos cargar con esta opción. No se nos ocurre un uso práctico, sin contar que los datos, de manera implícita, estarán almacenadas en texto plano, un riesgo de seguridad para nosotros. Por esa razón es que dudamos -como dice la ayuda- que es para guardar usuario y contraseña. En más detalle indica que dicho archivo de configuración permite guardar consultas personalizadas siempre y cuando dentro del archivo tenga el encabezado «[twitter]» y a continuación en una línea que comienza con la etiqueta «format:» le colocamos las opciones que ya revisamos y en otra línea algo nuevo: un prompt personalizado en texto y colores. Esta opción es la más adecuada «para despertar al nerd que hay en tí» ja, ja, ja 😉 .
Opción «–oauth».
De igual manera que la anterior pero con nuestras propias crdenciales como es nuestro caso. os explicamos mejor, nosotros registramos una aplicación en Twitter que generó los cuatro tokens que explicamos párrafos atrás. Si los colocamos en un archivo ocn esta opción nos conectaremos por nuestra aplciación y no por la de PTT.
Opción «–format».
Si lo que queremos es ver nosotros mismos de una manera agradable por pantalla podemos optar entre los siguientes:
default: bueno, es como si no hubieramos escrito nada, una línea por mensaje.
verbose: múltiples líneas por mensaje.
json: devuelve los datos en este popular formato.
urls: si solamente queremos ver los enlaces (recordad que Twitter usa acortador de direcciones).
ansi: la mejor opción, colores a diestra y siniestra.
Licencia de uso de PTT.
Python Twitter Tools se rige por la Licencia del Instituto Tecnológico de Massachusetts (Massachusetts Institute of Technologies MIT) del año 2008 y donde aparece el sr. Mike Verdone como único propietario:
Copyright (c) 2008 Mike Verdone
Permission is hereby granted, free of charge, to any person
obtaining a copy of this software and associated documentation
files (the "Software"), to deal in the Software without
restriction, including without limitation the rights to use,
copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the
Software is furnished to do so, subject to the following
conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES
OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
OTHER DEALINGS IN THE SOFTWARE.
La Licencia del MIT permite uso privado, modificación, distribución y uso comercial con la condición de que la licencia sea distribuida junto con los demás ficheros de la aplicación y la advertencia de que no se hacen responsables del mismo (en el software libre los únicos responsables somos nosotros mismos, esta parte de la licencia es muy dura de entender por los usuarios acostumbrados al software privativo).
Equipo de desarrollo de PTT.
He aquí una lista de las personas que participan -y mantienen al día- el proyecto «Python Twitter Tools» -una lista actualizada la podeis encontrar en este enlace en GitHub, al momento presente son los siguientes:
Developers:
Mike Verdone <mike.verdone@gmail.com>
Hatem Nassrat <hnassrat@gmail.com>
Wes Devauld <wes@devauld.ca>
Contributors:
Horacio Duran <horacio.duran@gmail.com> (utf-8 patch for IRC bot)
Rainer Michael Schmid (bugfix: crash when redirecting output to a file in 1.1)
Anders Sandvig (cmdline -l, -d, and -t flags)
Mark Hammond (OAuth support in API)
Prashant Pawar (IRC bot multi-channel support)
David Bittencourt (python 2.3 support)
Bryan Clark (HTTP encoding bugfix, improved exception logging)
Irfan Ahmad <http://twitter.com/erfaan> (Fixed #91 rate limit headers and #99 twitter API timeouts)
StalkR (archiver, follow)
Matthew Cengia <mattcen> (DM support, ISO timezone support, more API 1.1 support)
Andrew <adonoho> (Fixed streams support for HTTP1.1 chunked answers)
Benjamin Ooghe-Tabanou <RouxRC> (Helped fix streams support for HTTP1.1 chunked answers, added image support and more API 1.1 support)
En el tutorial anterior sobre registro de eventos con «logging» utilizamos a «argparse« para permitir a nuestros usuarios y usarias a establecer un nivel de registro de eventos en caso de ser necesario hacer seguimiento a nuestra aplicación. Prometimos allí ahondar con un tutorial completo sobre el tema y aquí lo prometido, ¡estudiemos juntos!
Introducción.
Para no caer en la redundacia, os recomendamos leer nuestro trabajo anterior, la sección «aislada» sobre argparse. Allí colocamos como ejemplo el comando ls;en realidad casi todas las aplicaciones que corren sobre la línea de comando aceptan argumentos a la derecha conformando parte de la orden de ejecución al presionar la tecla enter o intro.
Como dijimos en nuestro anterior tutorial sobre el registro de eventos en nuestras aplicaciones, argparse proviene de optparse el cual a su vez fue «descontinuada» desde la versión Python 2.7 ¿Por qué entrecomillamos? Lo hacemos porque como es software libre cualquiera puede hacer una bifurcación «fork» y continuar desarrollandolo a su gusto y conveniencia. De hecho se lleva un desarrollo en paralelo en GithHub como adelante veremos.
Lo bueno del asunto es que son bastantes similares en cuanto a su sintaxis y esto es así para facilitar a los desarrolladores que usaron optparse y ahora necesitan la migración a argparse.
Código previo a argparse.
Pero antes de entrar de lleno en argparse y como éste es un tutorial dedicado a dicha librería, vamos a ir un poco más allá: las bases sobre las cuales funciona argparse. Ya bien lo dice Richard Stallman, padre del software libre: «Nadie, ni siquiera Beethoven podría inventar la música desde cero. Es igual con la informática».
He aquí que una de las librerías básicas en el entorno de programación Python lo es sys. Para agregarlo a nuestros programas debemos enlazarlo con el comando import sys y podremos comenzar a usar sus objetos, los cuales no estudiaremos completamente en este tutorial sino que vamos a centrarnos en uno de sus componentes: sys.argv. Por medio de éste podremos acceder a la cadena de texto completa con la que el usuario o usuaria haya invocado nuestra aplicación por medio de la línea de comando. De una vez vamos a la práctica, tras esta muy breve teoría:
import sys
print("Número de argumentos: ", len(sys.argv))
print("Los argumentos son : ", str(sys.argv))
Explicación: sys.argv es, simplemente, una lista con cada palabra (entendiendose como palabra cualquier cadena de texto delimitada por al menos un espacio) con la que se invoca el guion «script» de nuestro, o de cualquier, programa.
La primera línea «enlaza» con la librería sys, permite cargarla en memoria y nos permite acceder a sus métodos , eventos y constantes.
La segunda línea usa la función len() que obtiene el largo de la lista, osea, el número de elementos -léase palabras-con la que se invocó nuestro guion «script».
La tercera línea muestra por pantalla todos y cada uno de los elementos de la lista especial.
Lo más curioso del asunto es que podemos no solamente acceder a la lista sino que también podemos cambiar sus valores, ¡probad! Lo que si es cierto es que el primer elemento (elemento cero) será siempre el nombre del fichero que almacena el guion escrito en python, con todo y extensión (aunque si no tuviera extensión .py igual se ejecuta) y los demás elementos de la lista son los argumentos o parámetros ya sea que lo escriba el usuario o le sea pasado al programa por el comando tubería «pipe» o «|» o en una variable en un guion «script» BASH.
Instalando argparse en nuestros ordenadores.
Para eliminar todo tipo de dudas, usamos Python versión 3.X -ya lo hemos dicho en nuestras entradas anteriores, revisad- y probablemente ya tengáis instalado argparse en vuestro ordenador. Al usar el comando import argparse y de no estar instalado de inmediato sale el mensaje de error en Python por lo que podemos instalarlo de diferentes maneras.
Por medio de pip3.
Para instalar argparse por medio de pip3 debemos escribir pip install argparse con los debidos derechos de administrador y así poder descargarlo de internet. Explicamos: pip3 es un esfuerzo en reunir en un repositorio de aplicaciones oficial de muchos software hecho por terceros pero que son supervisadas de manera directa por el equipo desarrollador de Python. Para saber si tenemos instalado pip3 simplemente escribimos pip3 –version y mostrará la versión instalada (ah, y de paso mirad otro ejemplo de argumentos en una aplicación «–version«) y dado el caso que no la tengamos instalada podremos usar:
En GitHub hallaremos el repositorio de Thomas Waldmann quien claramente advierte que el desarrollo de argparse es almacenado oficialmente por el equipo de desarrollo de Python pero que él mantiene una copia para quienes tengan Python 2.X y quieran agregar argparse a sus aplicaciones. De tal manera que si vosotros no lo tenéis instalado y no queréis -o no podéis- usar pip3 pues clonad el proyecto y ejecutad setup.py
Para los que les gusta la «arqueología» de software en Google podéis deleitaros en el siguiente enlace (tal parece que años atrás estaba alojado por aquellos lares antes de ser migrado el código fuente de argparse a la Fundación Python).
Observación importante:
Si sois como nosotros que tenemos instalado tanto Python 2 como Python 3 os damos el siguiente dato: si abrís un guion o programa con Python 2 y usáis argparse se generará un archivo precompilado «.pyc» cuya finalidad es cargar más rápidamente nuestro programa en sucesivos llamados. Luego si abrís el mismo «script» con Python 3 obetendréis un mensaje de error más o menos indicando «error en magic number«. Lo que debéis hacer es simplemente borrar todos los archivos «*.pyc» -por si las dudas- que en cuanto se vuelvan a ejecutar se generarán de nuevo. Advertidos quedáis ? .
Primeros pasos con argparse.
Tan solo debemos escribir nuestro guion de la siguiente manera:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.parse_args()
Primero llamamos a la librería y luego a un ubjeto analizador le asociamos con nuestra descripción de aplicación. Luego le ordenamos que muestre por pantalla los argumentos recibidos desde la línea de comandos. Así de sencillo -y esa es la idea- con tres simples líneas tenemos acceso al pase de parámetros y opciones por la línea de comando. Al llamar sin más el guión no veremos ningún resultado -aparente-. Pero si ejecutamos lo siguiente:
python3 tutorial_argparser.py -a
Veremos la siguiente respuesta:
usage: tutorial_argparser.py [-h]
tutorial_argparser.py: error: unrecognized arguments: -a
Nota importante: nosotros guardamos el programa en un fichero llamado tutorial_arparse.py y tal vez se sientan tentados a no escribir tanto y nombrarlo simplemente argparse.py ¡No lo hagáis! Sucederá que al ejecutar el guion se llamará a si mismo primero antes que buscarlo en las librerías Python. Este es el comportamiento predeterminado para nosotros cargar nuestras propias librerías: toda «importación» buscará primero en la carpeta donde está guardado el guion. Ya sabéis entonces.
Como véis ya argparse está trabajando para nosotros. La primera línea con el encabezado «usage:» indica los argumentos válidos -en este caso opcionales ya que está encerrados entre corchetes- y vemos que tiene la opción «-h». La segunda línea nos indica que ha sucedido un error en el archivo tutorial_argparser.py e indicando que es un argumento no reconocido lo que le acabamos de escribir: «-a«.
Lo que tenemos que experimentar ahora es precisamente «correr» el programa con el argumento «-h» y como probablemente ya sabéis ése es precisamente la orden para solicitar ayuda, veamos:
python3 tutorial_argparser.py -h
Obtendremos el siguiente mensaje:
usage: tutorial_argparser.py [-h]
Tutorial sobre argparse.
optional arguments:
-h, --help show this help message and exit
De nuevo la primera línea nos muestra los argumentos disponibles. La segunda ofrece la descripción de nuestro programa, la que le indicamos al inicializar la librería. La tercera línea (obviamente las líneas en blanco no la numeramos por propósitos didácticos) nos indica lo que hace el argumento solicitado: muestra el mensaje de ayuda y sale sin ejecutar ningún otro código. Notad que incluso nos muestra una opción «larga» del argumento de ayuda: «–help«. El siguiente paso es agregar nuestro primer argumento, veamos.
Agregando nuestro primer argumento a nuestro programa.
Argumento opcional:
Para que un argumento se opcional debemos antecederlo de un guion «-«; modifiquemos nuestro fichero de la siguiente manera:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument("-a", help="Detecta y confirma nuestro primer argumento.")
argumento = analizador.parse_args()
if argumento.a:
print("Argumento opcional solicitado: -a")
print("Argumento acompañado de:"+argumento.a)
else:
print("Ningún argumento.")
Allí con el método «.add_argument» establecimos la palabra clave «-a» y colocamos una breve descripción que será mostrada al solicitar ayuda con la consabida «-h» o «–help» la cual de una buena vez pedimos y obtenemos:
usage: tutorial_argparser.py [-h] [-a A]
Tutorial sobre argparse.
optional arguments:
-h, --help show this help message and exit
-a A Detecta y confirma nuestro primer argumento
Ahora empezamos a probar el nuevo argumento, se lo pasamos a la aplicación con el comando
$ python3 tutorial_argparser.py -a
y gentilmente nos advertirá que se necesita un argumento para la opción «-a«, es decir, será opcional, pero una vez que lo llamamos debemos acompañarlo de una cadena de texto, mirad:
Argumento opcional solicitado: -a
Argumento acompañado de:¡Hola!
Es hora de acompañar el argumento «-a» de una opción larga, nemotécnica, así que establecemos que sea «–aviso«: ya uséis uno u otro el comportamiento será el mismo.
analizador.add_argument("-a", "--aviso", help="Detecta y confirma nuestro primer argumento.")
argumento = analizador.parse_args()
if argumento.aviso:
print("Argumento opcional solicitado: --aviso")
print("Argumento acompañado de:"+argumento.aviso)
else:
print("Ningún argumento.")
Notad que tuvimos que cambiar el método «.a» por «.aviso«. También debemos agregar un entrecomillado si la frase que queremos pasar contiene varias palabras, de lo contrario argparse los interpretará como si fueran varios argumentos diferentes unos de otros:
Debemos acotar que, por defecto, argparse espera que sean cadenas de texto los argumentos que le pasemos a menos que le indiquemos expresamente lo contrario. Si necesitaramos pasar algún valor numérico, y que sea interpretado como tal, debemos agregar la opción type=int en donde definimos el argumento. Para darle utilidad esto último, cambiamos para que muestre repetidamente tantas veces como indique el número que pasemos, mirad atentamente:
mport argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"-a",
"--aviso",
help="Detecta y confirma nuestro primer argumento",
type=int
)
argumento = analizador.parse_args()
if argumento.aviso:
print("Argumento opcional solicitado: --aviso")
for x in range(0, argumento.aviso):
print("Argumento acompañado de:"+str(argumento.aviso))
else:
print("Ningún argumento solicitado")
Los cambios que hicimos implican usar la función str() que convierte la variable de tipo entero numérico a cadena de texto para poder usar el ciclo «for():«, así imprimirá el mensaje tantas veces como sea solicitado.
La isntrucción «type=» es poderosa, de hecho puede albergar cualquier tipo de variable, objeto ¡e incluso una función! Por ser tan avanzada por ahora no la estudiaremos en profundidad.
Ahora vamos a ver argumentos necesarios para ejecutar nuestro guion.
Argumento obligatorio.
Muchas aplicaciones precisan de un argumento obligatorio, por ejemplo, si está diseñada para analizar y trabajar con el contenido de un fichero pues es necesario indicarle que se debe pasar un nombre de archivo. Para ello modificaremos de nuevo de esta manera:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"archivo",
help="Indica el nombre del fichero a trabajar.",
)
argumento = analizador.parse_args()
if argumento.archivo="archivo":
print("Argumento OBLIGATORIO solicitado: archivo")
print("Nombre del archivo:"+argumento.archivo)
Si corremos sin parámetro alguno nos indicará que DEBEMOS indicar un nombre de fichero; si lo agregamos veremos esto:
$ python3 tutorial_argparser.py lista.txt
Argumento OBLIGATORIO solicitado: archivo
Nombre del archivo:lista.txt
Argumento obligatorio repetido n veces («nargs=n«).
Muchas veces una aplicación necesita un archivo origen de donde sacar datos, procesarlos y verter la respuestra en otro archivo: para ello podemos utilizar el siguiente código:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"nom_arch",
nargs=2,
help="Indica el nombre de los ficheros origen y destino a trabajar.",
)
argumento = analizador.parse_args()
if argumento.nom_arch:
print("Argumento OBLIGATORIO solicitado: nom_arch")
print("Nombres de los archivos:")
print(argumento.nom_arch[0])
print(argumento.nom_arch[1])
Observad la línea nargs=2: le estamos indicando que necesita dos argumentos (o los que necesitemos) , la desventaja de este método es que al usuario colocar un solo argumento argparse emite un mensaje que puede ser confuso, no es un mensaje explícito (recordad las reglas de oro de Python: explícito es mejor que implícito), es decir:
$ python3 tutorial_argparser.py arch1
usage: tutorial_argparser.py [-h] nom_arch nom_arch
tutorial_argparser.py: error: the following arguments are required: nom_arch
Como véis repite lo mismo n veces cuando la cantidad de argumentos NO coincide con nargs. La ventaja acá es que codificamos menos porque no tenemos que incluir dos parámetros con diferentes nombres pero dejemos aparte la flojera, seamos explícitos:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"nom_arch_orig",
help="Indica el nombre del archivo origen.",
)
analizador.add_argument(
"nom_arch_dest",
help="Indica el nombre del archivo destino.",
)
argumento = analizador.parse_args()
if argumento.nom_arch_orig:
print("Argumentos OBLIGATORIOS solicitados: nom_arch_orig y nom_arch_dest")
print("Nombres de los archivos:")
print(argumento.nom_arch_orig)
print(argumento.nom_arch_dest)
Así es menos confuso para nuestros usuarios y usuarias:
$ python3 tutorial_argparser.py
usage: tutorial_argparser.py [-h] nom_arch_orig nom_arch_dest
tutorial_argparser.py: error: the following arguments are required: nom_arch_orig, nom_arch_dest
$ python3 tutorial_argparser.py arch_orig.txt arch_dest.txt
Argumentos OBLIGATORIOS solicitados: nom_arch_orig y nom_arch_dest
Nombres de los archivos:
arch_orig.txt
arch_dest.txt
¿En cuales condiciones nos es útil nargs en modo múltiple? Ahora no viene nada a la cabeza pero alguna utilidad de seguro tendrá.
Ningún argumento, uno o más argumentos (» nargs=‘*’ «).
Por otro lado, así como nargs especifica un número exacto de argumentos, también permite el caracter asterisco que funciona a modo de comodín: puede aceptar uno, dos o más argumentos –o ninguno–. Escribamos este código:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"nombres",
nargs="*",
help="Recibe una lista de nombres de personas.",
)
argumento = analizador.parse_args()
if argumento.nombres:
print("Argumento(s) OBLIGATORIO(S) solicitado(s): nombres")
print("Nombres de las personas:")
print(argumento.nombres)
Y probemos su salida:
$ python3 tutorial_argparser.py
$ python3 tutorial_argparser.py José
Argumento(s) solicitado(s): nombres
Nombres de las personas:
['José']
$ python3 tutorial_argparser.py José María Pedro Carmen
Argumento(s) solicitado(s): nombres
Nombres de las personas:
['José', 'María', 'Pedro', 'Carmen']
En la primera línea del terminal notamos que no necesita argumento alguno para funcionar, eso sería «cero o más». Avizorad que si necesitamos por lo menos una persona en la lista podemos utilizar el signo de suma «+» en vez del asterisco («uno o más»), y al sustituirlo y ejecutar el programa veremos lo siguiente:
$ python3 tutorial_argparser.py
usage: tutorial_argparser.py [-h] nombres [nombres ...]
tutorial_argparser.py: error: the following arguments are required: nombres
Así nos dice que «nombres» necesita al menos uno (no está entre corchetes, es obligatorio) y que podemos agregar otros nombres de personas, esto lo indica entre corchetes y con tres puntos suspensivos.
Un argumento no obligatorio ya que utiliza un valor por defecto (» nargs=‘?’ «).
En este caso se utiliza nargs=»?» en combinación de un valor por defecto default=’cadena_de_texto’ por lo que esta opción es un tanto extraña no es obligatoria ya que si no se le pasa un valor toma el que por defecto le pongamos, este ejemplo ilustra muy bien lo que decimos:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"nombre",
nargs="?",
default='Jesús',
help="Recibe un nombre de persona y si no es suministrado utiliza 'Jesús'.",
)
argumento = analizador.parse_args()
if argumento.nombre:
print("Argumento: solicita un nombre (por defecto utiliza 'Jesús')")
print("Nombre:")
print(argumento.nombre)
Ahora bien, al ejecutarlo fijáos bien en lo que hace:
$ python3 tutorial_argparser.py
Argumento: solicita un nombre (por defecto utiliza 'Jesús')
Nombre:
Jesús
$ python3 tutorial_argparser.py Pedro
Argumento: solicita un nombre (por defecto utiliza 'Jesús')
Nombre:
Pedro
Esta opción es tremendamente útil si le pedimos a la usuaria que indique un archivo de origen y, si lo desea, un archivo destino. De no colocar un archivo destino entonces utilizará el nombre de archivo que nosotros mismo escojamos (y si ese archivo existe bien le podemos agregar datos al final o creamos un archivo nuevo con el nombre por defecto acompañado de un número que esté libre: arch1, arch2, … arch_n). Colocamos el código necesario para enseñaros claramente la opción nargs=»?»:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"arch_orig",
help="Solicita un nombre de archivo de origen.",
)
analizador.add_argument(
"arch_dest",
nargs="?",
default='arch_dest.txt',
help="Solicita un nombre de archivo destino, si se omite utiliza 'arch_dest.txt'.",
)
argumento = analizador.parse_args()
print("Argumentos: archivo de origen y destino ('arch_det.txt' si se omite destino)")
print("Nombres de archivos:")
print(argumento.arch_orig)
print(argumento.arch_dest)
Y esta sería la salida:
$ python3 tutorial_argparser.py
usage: tutorial_argparser.py [-h] arch_orig [arch_dest]
tutorial_argparser.py: error: the following arguments are required: arch_orig
$ python3 tutorial_argparser.py lista.txt
Argumentos: archivo de origen y destino ('arch_det.txt' si se omite destino)
Nombres de archivos:
lista.txt
arch_dest.txt
$ python3 tutorial_argparser.py lista.txt lista_ordenada.txt
Argumentos: archivo de origen y destino ('arch_det.txt' si se omite destino)
Nombres de archivos:
lista.txt
lista_ordenada.txt
Como abreboca al estudio avanzado de argparse colocamos el siguiente ejemplo, muy sencillo pero que ilustra hasta donde podemos llegar combinando opciones:
import argparse
import os
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"arch_orig",
help="Solicita un nombre de archivo de origen.",
)
analizador.add_argument(
"arch_dest",
nargs="?",
default= os.getcwd()+'/arch_dest.txt',
help="Solicita un nombre de archivo destino, si se omite utiliza 'arch_dest.txt'.",
)
En color verde resaltamos la añadidura: primero tenemos que importar la librería os. Uno de los métodos es os.getcwd() la cual devuelve la ruta donde está almacenado nuestro guion, ¡probad vosotros! Es la manera de aprender.
Argumento opcional convertido en obligatorio.
Volviendo a nuestro ejemplo del argumento «-a» o»–aviso» (¿recordáis arriba?) lo podemos convertir en obligatorio adicionando un parámetro a la declaración del argumento, lo resaltamos en color verde:
analizador.add_argument(
"-a",
"--aviso",
required=True,
help="Detecta y confirma nuestro primer argumento."
)
Atención: el parámetro required NO es compatible con nargs=»*» ni con nargs=»?».
A medida que avanzamos se torna compleja nuestra aplicación, nuestra recomendación es transcribir y ejecutar, experimentar cada una de las diferentes combinaciones y una vez las tengamos comprendidas y bajo control avanzamos al siguiente nivel más complejo aún.
Argumento opcional con valor por defecto.
Ahora veremos que un argumento opcional le podemos dar un valor por defecto y así lo invoquemos sin ningún tipo de argumento utilice dicho valor prefijado. Además, si el usuario desea introducir algún valor deberá colocar la palabra clave acompañada de un tipo de valor por nosotros especificado (texto, entero, etc.). En este punto nos vamos acercando a la manera de como normalmente se comportan las aplicaciones más comunes, es decir, un comportamiento bastante común; acá la codificación de ejemplo:
import argparse
analizador = argparse.ArgumentParser(".:|Tutorial sobre argparser|:.")
analizador.add_argument(
'--limite',
default=3,
type=int,
help="Especifique el número máximo de elementos, (por defecto 3).")
argumento = analizador.parse_args()
print("Límite: {}".format(argumento.limite))
Si
$ python3 tutorial_argparser.py
Límite: 3
$ python3 tutorial_argparser.py --help
usage: .:|Tutorial sobre argparser|:. [-h] [--limite LIMITE]
optional arguments:
-h, --help show this help message and exit
--limite LIMITE Especifique el número máximo de elementos, (por defecto 3). 3.
$ python3 tutorial_argparser.py --limite 17
Límite: 17
Argumento obligatorio y que exige escoger de una lista de opciones.
Muchas veces necesitamos que un usuario escoja un solo valor de una lista de opciones. Por ejemplo, solicitamos qyue escoja un mes de inicio de trimestre, el código sería el siguiente:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"mes",
choices=['Enero','Abril','Julio','Octubre'],
help="Permite escoger un mes de comienzo de trimestre.",
)
argumento = analizador.parse_args()
print("Argumento: solicita un mes de una lista predeterminada.")
print("Mes escogido:")
print(argumento.mes)
Y cuando lo ejecutamos:
$ python3 tutorial_argparser.py
usage: tutorial_argparser.py [-h] {Enero,Abril,Julio,Octubre}
tutorial_argparser.py: error: the following arguments are required: mes
$ python3 tutorial_argparser.py Junio
usage: tutorial_argparser.py [-h] {Enero,Abril,Julio,Octubre}
tutorial_argparser.py: error: argument mes: invalid choice: 'Junio' (choose from 'Enero', 'Abril', 'Julio', 'Octubre')
$ python3 tutorial_argparser.py Julio
Argumento: solicita un mes de una lista predeterminada.
Mes escogido:
Julio
Como ven, ¡tremendamente útil!
Un breve receso antes de continuar con…
Get comfortable with abstraction. If you try to understand how everything works, you'll get nothing done. pic.twitter.com/jfsXtdIySk
Como ya estamos prácticos con argparse (o deberíamos, sino retroceded y repasad) vamos a abstraernos un poco. Imaginemos que poseemos una impresora 3D, es decir, una ‘impresora’ capaz de producir objetos físicos tangibles. Nuestro programa será capaz de ‘imprimir’ bien sea un cubo, bien sea una esfera pero no ambos al mismo tiempo. Para ello codificamos de la siguiente forma y manera:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
grupo = analizador.add_mutually_exclusive_group()
grupo.add_argument(
"-c",
"--cubo",
action = "store_true",
help="Imprime un cubo en tercera dimensión.",
)
grupo.add_argument(
"-e",
"--esfera",
action = "store_true",
help="Imprime una esfera en tercera dimensión.",
)
argumento = analizador.parse_args()
if argumento.cubo:
print("'Imprime' un cubo")
if argumento.esfera:
print("'Imprime' una esfera")
En este caso, como los parámetros son opcionales si no «pasamos» nada pues nada hace. Pero si empleamos –cubo o –esfera dará como resutlado lo correspondiente, pero si usamos las dos al mismo tiempo nos indicará que escojamos solo una de ellas.
Si sois avezados notando los detalles, veréis lo coloreado en verde: un parámetro nuevo llamado action. Por increíble que les parezca, en realidad ya lo estuvimos usando desde hace rato: lo empleamos para saber si un parámetro opcional ha sido «pasado» a la aplicación, nuestro primer ejemplo hace uso de ello. La diferencia estriba que en aquel ejemplo debíamos acompañar de una cadena de texto y en este caso solo nos interesa el parámetro en si. Es decir, lo que nos interesa es si especificaron cubo o esfera y que lo represente como una variable booleana. Para que almacene un valor verdadero le asignamos store_true y si es un valor falso pues store_false. Esto último es un poco liado ¿para qué diantres necesitamos un valor falso?
En el siglo IX los chinos inventaron la brújula (aguja imantada suspendida que siempre apunta al polo norte) y desde entonces le destinaron en cada barco un habitaculum (en latín, habitáculo en castellano) al cual los franceses le nombraron habitacle y que luego abreviaron como bitacle y que pasó a ser traducido al castellano como bitácora (a pesar de que ya teníamos la palabra traducida directamente del latín, habitáculo). Pues bien, se necesitaba llevar un registro de la posición del barco en los largos viajes por nuestro globo terráqueo (y junto al sextante para registrar los astros) todo se anotaba en un cuaderno de bitácora, o simplemente bitácora.
¿A donde nos lleva esta introducción que aparentemente no tiene nada que ver con computación? ¡Ya veremos!
Introducción.
Así como los gobiernos en tierra necesitaban conocer qué sucedió en un navío en altamar a su regreso, nosotros necesitamos saber qué sucedió en los programas que para bien desarrollemos para nuestros usuarios. Lo más básico es mostrar mensajes por pantalla a los usuarios y confiar en que ellos y ellas nos retribuyan debidamente la información… pero con muy contadas excepciones, podemos esperar sentados para no cansarnos porque eso será difícil que se haga realidad.
Es por ello que debemos guardar un registro metódico para que posteriormente podamos evaluar qué funcionó mal (por extraño que parezca, si funciona bien pues felices de la vida aunque no recibamos las felicitaciones de nuestros usuarios y usuarias de software). Otra razón de llevar un registro sería la de análisis de desempeño o incluso ejecutar un programa en modo de depuración.
La razón y la lógica indica que dichos registros que pensamos llevar deberían ser guardados en una base de datos pero en proyectos pequeños tal vez no necesitemos tal nivel de complejidad. Pongamos por caso el programa Filezilla que tiene ambas versiones tanto como servidor como cliente: por defecto no se registra mensaje alguno a menos que así lo deseemos y si decidimos guardarlo podemos especificar un archivo llevando la fecha de cada evento (opcional) e incluso podemos limitar a un tamaño específico tras lo cual al alcanzar dicho valor se procede a crear un archivo nuevo pero sin la extensión «.log» la cual es sustituida por una numeración consecutiva.
Por esta y muchas otras razones el lenguaje Python 3 tiene disponible una librería destinada para tal efecto, estudiemos pues.
Creando una aplicación modelo.
Antes de crear siquiera registro alguno debemos tener, claro está, un software al cual llevarle un registro. Para ello proponemos un programa que llamaremos calculadora1.py cuyo código es el siguiente (si queréis repasar vuestro conocimientos básicos sobre Python, revisad nuestro tutorial al respecto):
El código es bastante sencillo, solo las cuatro operaciones aritméticas básicas: suma, resta, multiplicación y división; reconocemos que el código es un tanto extraño pero recordad que tiene propósitos didácticos solamente. Creamos una clase con funciones que no emplean return sino que muestran por pantalla los resultados excepto en la inicialización que muestra un mensaje puramente informativo, emulando el «on» de una calculadora electrónica y anunciando el modelo virtual. Abstraigámonos entonces en el ejemplo para comenzar a modificarlo con el registro de eventos.
Agregando la utilería «logging».
Para comenzar a utilizar la librería logging debemos incorporarla a nuestro archivo con el siguiente código:
La primera línea enlaza la librería y la segunda línea configuramos con una constante logging.DEBUG (que tiene un valor decimal de diez), osea, el nivel («level«) que vamos a usar: modo de depuración.
Notad todos y todas que en GNU/Linux son distintas las mayúsculas de las minúsculas, por lo tanto logging.DEBUG es una constante y logging.debug es un método, diferenciad bien esto en el siguiente código que modificamos a partir de la aplicación modelo.
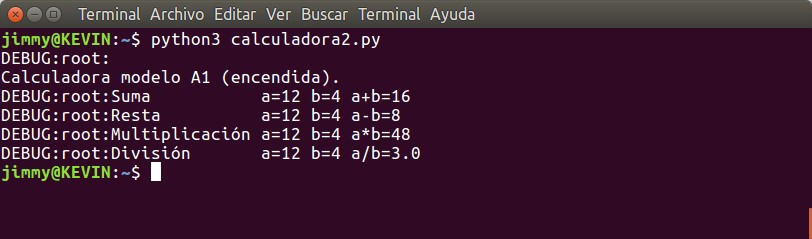
Como vemos en la siguiente imagen la salida por pantalla ha sido modificada ya que le agrega «DEBUG:root» a todos los mensajes de resultado.
python3 calculadora2.py
La primera palabra indica que estamos en modo de registro a nivel de depuración «DEBUG» y la segunda palabra indica que estamos depurando el módulo principal aunque esto no es realmente cierto. Lo mejor sería indicar desde dónde estamos imprimiendo el mensaje de depuración, en nuestro caso cualquiera de las cuatro funciones. Para ello vamos a volver a modificar el programa -que ya hemos renombrado como calculadora2.py– especificando cada función por separado:
Bien, pues ya estamos listos para comenzar a grabar en un archivo de texto plano nuestros eventos. Esto se logra configurando de nuevo el encabezado logging.basicConfig el cual ahora lo ocuparemos en varias líneas para buscar una mayor claridad para cada uno de sus parámetros:
Por supuesto el archivo será guardado en la misma carpeta donde se ejecuta la aplicación y para nuestra sorpresa al ejecutarla ya no muestra nada por pantalla… lo cual no es lo que realmente queremos hacer pero paciencia, primero analizemos el archivo resultante.
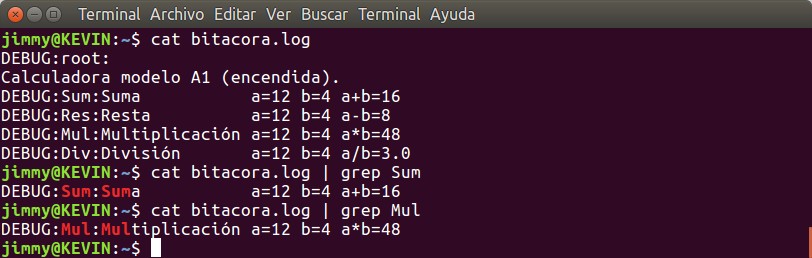
cat bitacora.log y combinado con el comando grep
Al usar el comando cat podremos, entre otras cosas, listar el contenido de un archivo por pantalla y como probablemente la cantidad de mensajes generará gran cantidad de líneas podremos filtrar los resultados por palabra clave. ¿Recordáis que dimos nombres diferentes para la muestra de resultados a nivel de cada función? Pues con el comando grep que recibe el resultado del comando cat por medio del comando «tubería» «|» y la palabra clave «Sum» o «Mul» podremos ver lo que nos interese. Ya nuestra aplicación está entrando en modo pragmático, ¡lo realmente útil para nosotros!
Agregando más pragmatismo aún: claridad al registro.
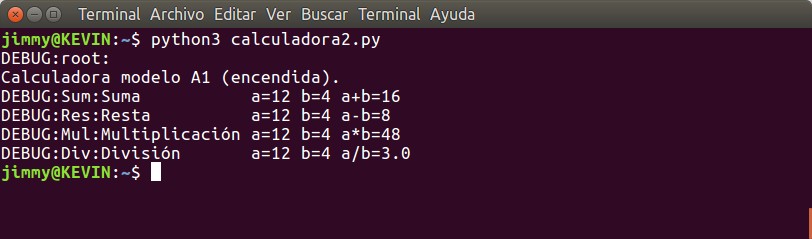
Nosotros los seres humanos en nuestro cerebro siempre buscamos darle «orden» a nuestro mundo, así está torcido lo tratamos de ver derecho y esto en el registro de eventos no ha de ser la excepción. Ya le colocamos para saber cual función produce tal registro pero le agregaremos mayor claridad en el apartado de configuración al inicio de la aplicación:
Recordad siempre al final de cada línea colocar una coma para separar los parámetros, que como es multilínea tendemos a pensar que cada retorno de carro automáticamente separa cada parámeto pero no es así.En el tercer parámetro mandamos a separar con par de espacios y un guion las diferentes secciones de cada evento en cada línea:
Fecha y hora exacta hasta en milisegundos cuando ocurrió el evento.
Nombre del módulo donde se origina cada evento, en nuestro caso cada función.
Nivel del mensaje, clasificación (hasta ahora estamos en modo de depuración solamente DEBUG).
El mensaje en sí mismo.
cat bitacora.log
Formato de tiempo mejorado.
Al formato de estampado de fecha y hora lo podremos mejorar agregando otra línea más al encabezado de configuración con una máscara que también es utlizada por el comando time.strftime():
Dejamos para vosotros os ejercitéis y veáis cómo es distinto los nuevos registros que se siguen adicionando de manera automática al final de nuestro archivo destinado a tal efecto, bitacora.log
Nivel de registro de eventos.
Como hemos repetido varias veces, del modo de depuración DEBUG no nos hemos movido hasta ahora. Por ello debemos estudiar los diferentes niveles -y constantes- que utiliza la librería logging: ya sabemos que logging.DEBUG vale diez -y se van incrementando de diez en diez- pero he aquí la tabla completa de valores:
Nivel
Valor
numérico
Función
Uso
NOSET
0
no aplica
no aplica
DEBUG
10
logging.debug()
Diganóstico de problemas, muestra información bien detallada.
INFO
20
logging.info()
Confirma que todo está funcionando correctamente.
WARNING
30
logging.warning()
Indica que algo inesperado ha sucedido, o pudiera suceder.
ERROR
40
logging.error()
Indica un problema más serio.
CRITICAL
50
logging.critical()
Muestra un error muy serio, el programa tal vez no pueda continuar.
Agregando mensajes de error y su registro.
A nuestra aplicación vamos a agregarle un mensaje de error en la función de división, bien sabemos que cualquier número dividido entre cero tiende al infinito el cual es un concepto que entedemos los seres humanos pero los ordenadores no. La modificación es la siguiente (notad que b valdría uno si el valor no es pasado a la función para tratar de evitar este error):
def dividir(self, a=0, b=1):
if (b==0):
bita_div.error("Alerta: el divisor debe ser distinto a cero.")
else:
bita_div.debug("División a={} b={} a/b={}".format(a,b,a/b))
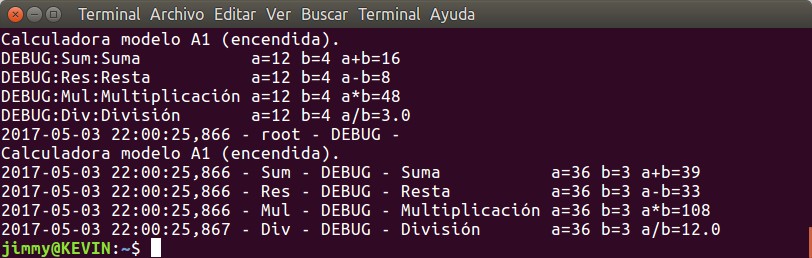
También modificamos el divisor en la función de división a calc.dividir(36,0) y el resultado en el registro de errores mostraría algo aprecido a esto:
Calculadora modelo A1 (encendida).
03/05/2017 11:03:07 PM - Sum - DEBUG - Suma a=36 b=3 a+b=39
03/05/2017 11:03:07 PM - Res - DEBUG - Resta a=36 b=3 a-b=33
03/05/2017 11:03:07 PM - Mul - DEBUG - Multiplicación a=36 b=3 a*b=108
03/05/2017 11:03:07 PM - Div - ERROR - Alerta: el divisor debe ser distinto a cero.
Lo próximo que haremos es modificar de manera completa nuestra aplicación con los diferentes «niveles» de mensajes.
Empleando diferentes niveles de registro.
Volvamos nuestros pasos sobre la sección logging.basicConfig donde contiene el nivel de registro de eventos para nuestra aplicación. Recordemos que la establecimos a nivel DEBUG y ahora la estableceremos a nivel INFO, guardaremos y ejecutaremos de nuevo la aplicación. Luego revisaremos el fichero bitacora.log y notaremos que no se registró el mensaje de inicialización pero si quedaron registrados los mensaje de información (y por supuesto el mensaje de error).
El siguiente paso es elevar al nivel de WARNING para obtener solamente el mensaje de error por la división entre cero y se repite el resultado si lo elevamos a nivel ERROR. No obtenderemos mensaje alguno si lo establecemos a nivel CRITICALya que la divisón entre cero no solamente ha sido debidamente advertida sino que también ha sido debidamente desviada.
Pro último, y más difícil de obtener (según la aplicación de modeo didáctico que de exprofeso escogimos) es el mensaje a nivel CRITICAL. Volvemos a repetir, este comportamiento es circunstrito estrictamente a nuestra aplicación modelo: la división está en el mensaje mismo a mostrar en bita_div.CRITICAL y nunca lograremos que se muestre ya que está debidamente desviado además, si no lo desviaramos al ejecutar el compilador Python3 inmediatamente nos mostraría el error si intentamos dividir entre cero y por ende no se ejecuta el programa.
Nosotros somos de experimentar al máximo, nos hacemos muchas, muchísimas preguntas: ¿Y si compilamos la aplicación, es decir la convertimos a lenguaje binario para ejecutar y lograr el mensaje a nivel CRITICAL?
Para ello -brevemente- podemos instalar PyInstaller:
sudo pip3 pyinstaller
Luego simplemente vamos a la carpeta con nuestro fichero calculadora2.py (habiendo eliminado la desviación del error de división entre cero):
pyinstaller calculadora2.py
Y luego de cierto tiempo (¡oh, sorpresa, también utiliza logging para mostrar el progreso de la compilación pero con unos códigos no recomendables de niveles de registro -valores personalizados-) y en una carpeta dist encontraremos nuestro ejecutable listo para ser experimentado. Nosotros obtuvimos esto, si queréis practicad que algo parecido obtendréis:
pyinstaller calculadora.py
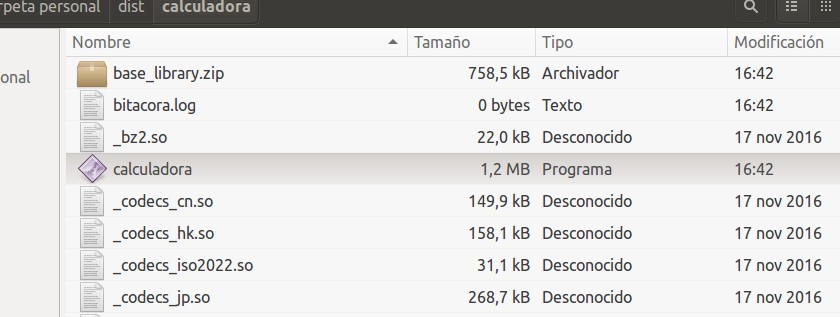
Entonces estaremos listo para ejecutar nuestro flamante binario, nos vamos con el explorador de ficheros Nautilus de Ubuntu a la carpeta dist le damos click derecho, ejecutar y ¡oh, sorpresa! el fichero bitacora.log se genera y aparece… pero con cero bytes, sin nada dentro, ¿qué ha sucedido aquí?
bitacora.log vacio cero bytes
Pues que simplemente la librería de registro abre el archivo bitacora.log (crea el archivo) pero la división entre cero no le permite llegar a ejecutar el grabado del mensaje, ya que las instrucciones son anidadas y primero trata de dividir y luego mostrar el mensaje, pero como se «cuelga» pues no registra nada de nada.
En este punto ya es bueno concluir algo muy cierto: el registro de errores incluso nos beneficiará al obligarnos a pensar dónde colocar los mensajes necesarios para futuras mejoras y en el caso del software libre donde TODOS podemos ser parte de un equipo de programadores esta ayuda es tremendamente bienvenida.
Otra pregunta que nos hacemos, ¿qué sucede si no establecemos un nivel de registro específico en logging.basicConfig? De manera predeterminada la utilería está en nivel WARNING y los mensajes que sean iguales o superiores a este nivel serán registrados (WARNING, ERROR y CRITICAL). No obstante vamos a dar un paso más allá en nuestros estudios y vamos a configurar para que sean nuestros propios usuarios quienes establezcan un nivel de registro lo cual consideramos útil para ellos que NO son programadores y que tal vez necesiten cierta orientación sin necesidad que ellos y/o ellas lleguen a tener que descargar el código fuente de la aplicación -que siempre estará al alcance por ser software libre-.
Que los usuarios y usuarias establezcan su nivel de registro.
Pasando parámetros a una aplicación desde la línea de comando.
En el mundo de Python hay varias librerías que nos permiten «pasar» parámetros hacia «lo interno» de nuestras aplicaciones, algunas de ellas son -pero no son todas-:
getoptes una librería la cual se deriva de una del lenguaje C llamada, claro, getopt().
optparseescrita para Python pero que actualemente está «descontinuada».
argparse la cual curiosamente deriva de optaprse pero ofrece total compatibilidad a la versión 3 -y a futuro-.
Por esa razón escogemos esta última para evitarnos dolores de cabeza a futuro.
argparse.
Introducción a argparse.
Debemos hacer una breve introducción al concepto de parámetros tanto opcionales como obligatorios. De manera general las aplicaciones corren sin ninguna isntrucción especial: escribimos el nombre del fichero, el sistema operativo revisa si es un ejecutable, o carga en memoria y ejecuta las instrucciones contenidas.
Un ejemplo sencillo es el comando para listar ficheros y directorios en una ventana terminal: ls. Sin más dicho comando nos muestra por pantalla los ficheros y directorios contenidos en la carpeta desde donde la ejecutamos. Si hubiera alguna carpeta y queremos saber su contenido debemos escribir ls nombre-de-la-carpeta y allí tenemos un parámetro opcional que le estamos pasando a la aplicación: le estamos ordenando listar el contenido de un directorio. Decimos que es opcional porque, como vimos, el comando no necesita nada para funcionar pero somos nosotros los que tenemos la necesidad de pedirle algo muy específico. Pero adicionalmente a la petición específica queremos que nos lo muestre de una manera específica y para poder diferenciar los nombres de las carpetas -o archivos- que pidamos de la forma como la va a presentar pues nació la idea de colocar palabras claves para diferenciar (recalcamos que estamos con el comando ls como ejemplo útil ya que es un comando extremadamente básico). Así podemos teclear ls nombre-de-carpeta -l para listar en modo columna o el también llmado modo largo (nombres de ficheros o directorios uno encima del otro con detalles de tamaños, fecha, atributos, etc.).
Es por esta razón que se estableció ciertas normas para pasar parámetros, en general podemos decir que:
Se utiliza un guion «-» como prefijo para indicar un parámetro y se acompaña generalmente con una sola letra que más que suficiente porque tenemos 54 opciones distintas (27 caracteres mayúsculas y minúsculas).
Como estrategia nemotécnica se utilizan dos guiones juntos «–» junto con palabras o incluso frases para que sea de manera explícita su recordación.
También se da el caso que a las dos opciones anteriores se le agregue sin dejar espacios un signo de igualdad y a continuación algún valor condicionante (que puede ser imprescindible o no).
Como para algunos el punto anterior no les parece elegante, también se estila colocar un espacio y a continuación algún valor condicionante.
Siguiendo con el ejemplo del comando ls:
Ejemplo del punto 1: comando «ls -r» (lista los archivos y carpetas en orden alfabético inverso, de la letra zeta hacia la letra a).
Ejemplo del punto 2: comando «ls –reverse» ídem al punto anterior pero más fácil de recordar y explícito para mostrar.
Ejemplo del punto 3: comando «ls –sort» ordena las lista de ficheros por orden de tamaño, del más grande hacia el más pequeño, pero sucede que hay muchas maneras de ordenar ese listado y si lo ejecutamos así sin más nos solicita un parámetro necesario. Podemos pedirlo por tamaño así que escribimos «ls –sort=size» y veremos el resultado con primero los más grandes yendo luego progresivamente hasta los más pequeños. Por cierto, este comando «largo» tiene un equivalente «corto»: ls -s.
Ejemplo del punto 4: comando «ls patron-a-buscar» como por ejemplo si queremos ver solamente los archivos que comienzen con la letra «a»: «ls a*«.
Primeros pasos con argparse.
Para comenzar a utilizar argparse en nuestro programa, simplemente hagamos un fichero nuevo y le colocamos los siguiente:
import argparse
analizador = argparse.ArgumentParser(description="Programa demostrativo de argparse")
analizador.parse_args()
Al salir lo nombramos como mi_programa.py y lo ejecutamos con python3 mi_programa.py y, por supuesto, no hace nada de nada ya que no le escribimos ningún código adicional. Pero ahora vamos a ejectuarlo acompañado de un parámetro como lo es el siguiente:python3 mi_programa.py -h y obtendremos la siguiente salida:
usage: mi_programa.py [-h]
Programa demostrativo de argparse.
optional arguments:
-h, --help show this help message and exit
Como vemos todo viene preconfigurado para utilizar el idioma inglés por defecto, pero pronto podremos darle un uso mejor para orientarlo hacia el idioma castellano en un tutorial dedicado al tema. Notad que especifica que el «parámetro largo» para ayuda es –help. Adicionalmente, cualquier otro parámetro que le pasemos manifestará desconocerlo -no hemos programado nada áun, por ahora-. Por lo pronto ya cumplimos con iniciar el uso práctico de argparser, continuemos aprendiendo.
Agregando otro argumento opcional.
Como vemos argparse tiene al menos un argumento establecido por defecto, el de ayuda [el cual es opcional, está mostrado entre corchetes], y ahora nosotros vamos a agregarle nuestro propio argumento para establecer el nivel de registro de eventos. Para ello especificaremos la palabra clave -log_lev acompañado del nivel que deseemos establecer, a continuación lo pasamos por una serie de tamices con la instrucción condicional if~elif~else y si coincide mostramos por pantalla la opción elegida:
import argparse
analizador = argparse.ArgumentParser("Programa demostrativo de argparse")
analizador.add_argument("-log_lev", help="Utilice DEBUG, INFO, WARNING, ERROR o$
analizador.parse_args()
argumentos = analizador.parse_args()
if argumentos.log_lev == 'DEBUG':
print("DEBUG")
elif argumentos.log_lev == 'INFO':
print("INFO")
elif argumentos.log_lev == 'WARNING':
print("WARNING")
elif argumentos.log_lev == 'ERROR':
print("ERROR")
elif argumentos.log_lev == 'CRITICAL':
print("CRITICAL")
else:
print("Opcion no válida de nivel de registro de eventos.")
Como vemos esto simplemente es el armazón para el manejo del pase de parámetros a nuestro programa didáctico para el registro de eventos con la utilería logging.
En este punto corred vuestro programa varias veces, experimentad con el pase de parámetros para que luego continuemos con el último paso de este tutorial: la fusión de logging con argparse.
Uniendo «logging» con «argparse».
Ya para finalizar unimos el código de ambos ejemplos y la idea es la siguiente: al utilizarse sin parámetros se establece el nivel de registro en WARNING que es el nivel predeterminado. Si se utiliza el parámetro -log_lev sin acompañarlo de valor alguno, la librería argparse se encargará debidamente de orientar al usuario sobre las opciones disponibles. Si el usuario usa alguna opción disponible válido pues se establece debidamente el nivel de registro correspondiente.
Queda para vuestra práctica el permitir que los usuarios especifiquen un nombre de archivo para el registro de eventos.
Acá tenemos el código final, espero os haya servido para aprender algo nuevo sobre el lenguaje Python.
La verdad es que revisando los temas publicados por nuestros colegas de GNULinuxBlog (por ahora quien publica el tema, el sr. Elías Rodríguez Martín y el sr. José Miguel, creador del blog) encontramos uno en particular muy útil y que nosotros habíamos enfocado de una manera un tanto complicada en comparación con la facilidad de lo que allí proponen. Cuando conseguimos que alguien es más listo que nosotros inmediatamente lo reconocemos y aprendemos de dichas personas, no tenemos rubor en admitirlo, por eso os pedimos que nos acompañéis en nuestro artículo de hoy: compartir ficheros de una manera rápida y sencilla con Python.