
100 -> Continuar.
101 -> Protocolo de conmutación.
102 -> Procesando (WebDAV).
103 -> Primeras Pistas.
200 -> OK

100 -> Continuar.
101 -> Protocolo de conmutación.
102 -> Procesando (WebDAV).
103 -> Primeras Pistas.
200 -> OK
Este artículo en específico se rige por la licencia CC-BY que fue asignada por su correspondiente(s) autor(es) o autora(s). Dicha licencia permite así la propagación de este material y su traducción a cualquier idioma. Usted podrá encontrar un resumen de tal licencia en este enlace (en idioma castellano) y la licencia en sí misma de forma completa y totalmente traducida al español en este otro enlace.

This article is under License Creative Commons Attribution 4.0 International.
Traducción al castellano del artículo «Level up your HTML document with CSS» escrito por Jim Hall en OpenSource.com
https://opensource.com/article/22/8/css-html-project-documentation
13 de agosto de 2022.
Seguir leyendoDocument Object Model o DOM (‘Modelo de Objetos del Documento’ o ‘Modelo en Objetos para la Representación de Documentos’) es esencialmente una interfaz de plataforma que proporciona un conjunto estándar de objetos para representar documentos HTML, XHTML y XML. El ente encargado de normar, documentar y difundir todos estos modelos y lenguajes de marcado es World Wide Web Consortium (W3C).

Actualizado el lunes 28 de octubre de 2019.
Publicado el 24 de abril de 2016.
¿Problemas para escribir HTML? ¿Olvidamos su sintaxis? ¿Colocan nuevas etiquetas para hacer las mismas cosas?
Aunque seamos muy buenos codificando y tengamos muy buena memoria, lo único constante es el cambio y las definiciones de HTML pueden cambiar -de alguna forma o manera- entre versiones. Un ejemplo es la etiqueta <strong></strong> que en HTML 4.01 significa texto enfatizado y en 5.0 significa texto importante (nota: solo los nerds🤓 como nosotros le damos importancia a este tipo de cosas). En todo caso, para concretar la idea, es molesto por ser repetitivo, estar colocando los corchetes angulares a cada rato «<» y «>», son más golpes de tecla innecesarios. Por ello, para ahorrarnos trabajo, tenemos a Markdown.

En un artículo anterior hablamos sobre las «Norma de Diseño de Cuadrícula» y en esta oportunidad presentaremos lo básico de realizar figuras fundamentales ¡y hasta el cómo integrarlas en WordPress! (no en balde nuestro leit motiv es «KS7000 + WP»).
Por supuesto que no estamos hablando del elemento químico cromo («chromium» en inglés) sino del popular navegador web de código abierto para todos. Lo que desarrollaremos es una «extensión», una herramienta integrada al navegador y que tiene muy diferentes propósitos. Con fines didácticos haremos una extensión muy sencilla que nos redirige hacia una página web que nos devuelve simplemente nuestra propia dirección IPv4, ¡manos al teclado!
Para abrir el mes de junio seguimos el hilo en nuestros artículos que buscan difundir el conocimiento libre del Patrimonio Tecnológico de la Humanidad. En anterior oportunidad estudiamos PHP curl, una herramienta basada en cURL y por ende en libcurl (¡ea, esto último no lo mencionamos allá!). Como en ese caso obtuvimos un método para descargar páginas web enteras, incluso si hay que pasarle datos con el método POST y/o hay que introducir usuario y contraseña. Esta entrada busca extraer, analizar e incluso modificar dichos datos ¡vente con nosotros!
En el MarkDown tutorial que hicimos explicamos de manera rápida la manera de escribir una página web con un formato desenfadado y sin tantas pretensiones. También publicamos acerca de Marp, un software libre capaz de realizar presentaciones y exportar a PDF a partir de un fichero hecho con MarkDown. Analizando el software de familias Wikis nos topamos con PMWiki que tiene una peculiar manera de escribir código «pseudo HTML» y por ello comenzaremos explicando las reglas de sintaxis y luego veremos como se instala y mantiene una página web con dicha solución en software libre, ¡adelante!
PMWiki utiliza un lenguaje de marcado a diferencia del paradigma actual del siglo XXI: «lo que usted ve es lo que obtiene» («What You See Is What You Get» o por sus iniciales WYSIWYG). Esto último consiste en utilizar herramientas de modelado que presentan en tiempo real la apariencia del trabajo que hacemos sin importarnos cómo se logra ya que el «interprete» nos abstrae del código subyacente. El asunto es que nosotros nunca dejamos de estar conscientes que los ordenadores solo entienden de unos y ceros (y ni siquiera eso, ya que es una abstracción que nos hacemos: solo entiende con apagado o encendido, hay o no hay en el último de los casos).
Hay seis reglas básicas para editar las páginas web cuyo motor web es la PMWiki:
Los párrafos se delimitan dejando una línea en blanco, por lo tanto todo lo que escribamos en varias líneas será presentado como un solo párrafo. Para los que amamos el utilizar la venta terminal para trabajar nos ofrece la ventaja de escribir con un máximo de 40, 80 o 90 caracteres de anchura lo cual nos permite una cómoda edición sin preocuparnos del ancho de pantalla que utilizarán nuestros usuarios.

Generalmente monitores con relación 16:9 que es apto para ver películas pero incómodo para ver párrafos muy anchos ya que dificulta seguir la línea que estamos leyendo -recordad el famoso papel pijama del siglo XX , pero bueno, ese no es nuestro problema sino del usuario de la página, je, je, je ? ).
Este párrafo aunque | Este párrafo aunque tiene varias líneas será mostrado como uno solo. |
Para unir una línea con otra \ | Para unir una línea con otra usaremos la barra invertida (a pesar que este es el comportamiento predeterminado, unir líneas). |
Sin embargo, si necesitamos que el párrafo | Sin embargo, si necesitamos que el párrafo tenga múltiples líneas, como por ejemplo un diálogo, debemos usar al final dos barras invertidas en cada línea, ejemplo: -"¿Qué dijo ella acerca del tema?". -"Que eso no era problema de ella". |
Para forzar fin de línea y dejar | Para forzar fin de línea y dejar una línea de por medio usamos tres barras invertidas. |
Para forzar la separación de una línea | Para forzar la separación de una línea usaremos para indicar el corte. |
Para indentar un párrafo | Para indentar un párrafo (que sirve para hacer citas o resaltar ideas) usaremos "->":"Citas Citables" Mientras más guiones usemos más indentado el párrafo. |
Una cita que comienze con | Una cita que comienze con una línea prominente es una forma atractiva para ello usaremos "Cita con línea prominente muy larga para que se note" |
Para comentarios usaremos los | Para comentarios usaremos los símbolos mayor que y menor que por pares. |
En la tabla anterior os mostramos de manera práctica los comandos y cómo se vería, sin embargo es un artilugio de programación que le hicimos a WordPress para ilustraros el temas, hay algunos detalles que no se ven igual en PMWiki (lo mejor sería hacer un subdominio y correr una pequeña wiki allí para que veaís bien claro el resultado).
Ya sabemos que para hacer una lista debemos comenzar con un asterisco «*» cada línea, y si acaso quiséramos asignarle una numeración automática debemos usar un numeral «#». Cualquier línea a continuación que NO comience con asterisco o numeral es implícito que finaliza la lista.
Acá ampliamos un poco con las sublistas: una línea que comienze con dos asteriscos (despúes de una línea que comienze con un asterisco) se visualiza como una sublista:
* Esta es una lista. * Segundo elemento de lista. ** Comienza sublista. ** Segunda línea de sublista.
Producirá el siguiente resultado:
Se pueden combinar:
* Lista ## Sublista. ## Dos. ## Tres.
Salida:
Algo que gusta mucho a los autores es la numeración romana o con letras del abecedario, ya sea en maypusuculas o minúsculas; esto se logra colocando las siguientes palabras claves luego de el o los asteriscos y/o numerales de cada línea (por supuesto, no se mostrará al usuario dichas palabras claves al momento de «servir» el artículo wiki):
Ejemplos de códigos:
* %roman% Lista con números romanos. * Línea dos en números romanos. ## %ALPHA% Sublista con letras del abecedario en mayúsculas. ## Segunda línea de sublista.
Y arrojaría lo siguiente:

Estos «trucos» necesarios para mostrar en WordPress listas y sublistas a «nuestra manera personalizada» tendrán su artículo aparte y será un complemento a nuestro tutorial HTML5 para no hacer ese tutorial más voluminoso de lo que ya es -y enseñar a usar WordPress, que ni un temita le hemos dedicado a nuestro «motor» de blog.
Este concepto de palabras claves se repite si debemos forzar la numeración u orden: «%item value= número%«.
También si queremos parar la numeración y reiniciarla solo debemos insertar una línea con la siguiente palabra clave: «[==]«:
# %item value=7000% Línea siete mil. # Siete mil uno. [==] # Reinicia numeración.
Salida:
Nota: el indentado que veís lo hace WordPress para alinear las listas con diferentes numeraciones, se agradece para nosotros los maniáticos del orden.
Para cada elemento de una lista podemos anexar un párrafo a continuación para ampliar o definir un concepto o descripción. El estilo indica que ha de ser lo más breve y conciso posible para mantener el panorama de la lista en sí misma. Dijimos que cualquier línea a continucación que NO comience con asterisco o numeral significa el fin de la lista pero he aquí que si una línea comienza con un espacio se considera esa línea como perteneciente al elemento de la lista que lo precede pero no se enumera -no es un elemento de la lista en sí-. Para lograr el indentado se debe finalizar la línea elemento de lista con «\\» (que aunque no es esctrictamente necesario, mejora el aspecto).
Un ejemplo:
'''Grandes venezolanos''' * Simón Bolívar, Caracas 1783, Santa Marta 1830.\\ ''«Llamarse jefe para no serlo es el colmo de la miseria»''. * Francisco de Miranda, Caracas 1750, Cádiz 1816. ''«¡Le Venezuela est Blessée au coeur!»''. * José Antonio Páez.
Produce lo siguiente:
Grandes venezolanos:
«Llamarse jefe para no serlo es el colmo de la miseria».
«¡Le Venezuela est Blessée au coeur!».
Si escribimos el comando «—-» (cuatro o más guiones seguidos) en una sola línea de texto nos produce una línea horizontal gráfica que sirve para separar párrafos o denotar importancia como una advertencia -o el uso que queráis-.
Supongamos que en nuestra PMWiki queremos hacer un tutorial en castellano sobre todo esto que estamos explicando acá vía WordPress: para indicarle que no proceso nuestros código ejemplos y los muestre tal cual, cómo código que son debemos «escapar» el texto de código con «[@ texto código @]». Puede ser utilizado para un párrafo completo o para una o más palabras en un párrafo.
Para un «escapado» estricto utilizamos «[= texto código =]», la diferencia esta que con arroba se respetarán los saltos de líneas y espacios pero con el signo de igualdad se escribirá todo junto como un párrafo .
Si además necesitamos una fuente monoespaciada, es decir, un tipo de fuente cuyas letras todas y cada una tienen el mismo ancho simplemente debemos comenzar la línea con un espacio (que no esté después de una lista, ojo con eso). Imaginad (o recordad) los famosos cuadernos cuadriculados para matemáticas, una letra por retícula.

Para las tablas emplearemos el caracter doble «tubería» o «||»:
Una tabla sin borde se logra con «border=0», de uno en adelante produce un borde doble con un sombreado que aumenta según aumenta el valor entero que le demos.
Existe una sintaxis alterna para tablas más avanzadas pero en honor a la verdad dicha sintaxis es igual de compleja que escribir en código HTML. Pensamos que solamente vale la pena para un cuadro de navegación como el siguiente:
(:table border=1 width=30% align=right bgcolor=#cccc99 cellspacing=0 : ) (:cellnr: ) '''Páginas de buscadores''' (:cellnr: ) *[[https://duckduckgo.com/ | DuckDuckGo]] *[[https://fr.wikipedia.org/ | Wikipédia L'encyclopédie libre]] (:tableend:)
En esta imagen podemos ver la tabla avanzada mezclada con los ejemplos últimos, debajo de la imagen coloamos TODO el código completo que produce ese resultado en PMWiki:
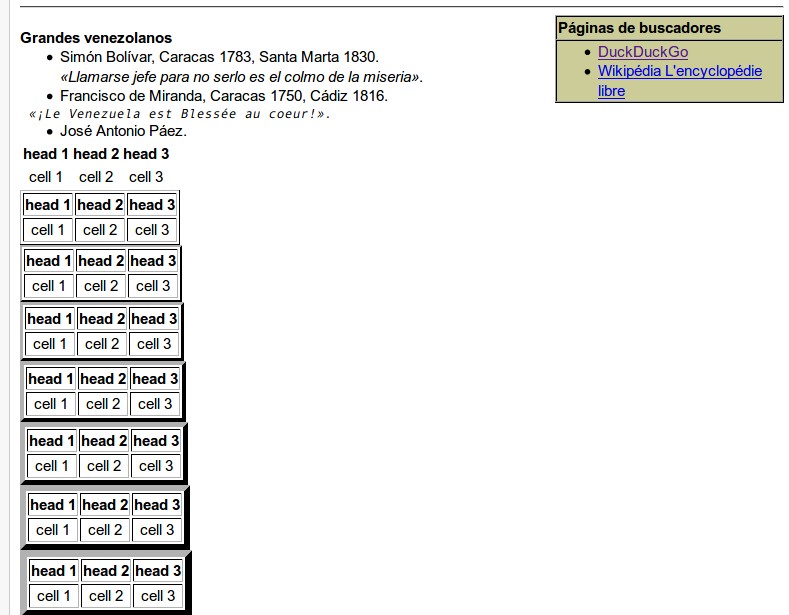
(:table border=1 width=30% align=right bgcolor=#cccc99 cellspacing=0 :) (:cellnr:) '''Páginas de buscadores''' (:cellnr:) *[[https://duckduckgo.com/ | DuckDuckGo]] *[[https://fr.wikipedia.org/ | Wikipédia L'encyclopédie libre]] (:tableend:) '''Grandes venezolanos''' * Simón Bolívar, Caracas 1783, Santa Marta 1830.\\ ''«Llamarse jefe para no serlo es el colmo de la miseria»''. * Francisco de Miranda, Caracas 1750, Cádiz 1816. ''«¡Le Venezuela est Blessée au coeur!»''. * José Antonio Páez. || border=0 ||! head 1 ||! head 2 ||! head 3 || || cell 1 || cell 2 || cell 3 || || border=1 ||! head 1 ||! head 2 ||! head 3 || || cell 1 || cell 2 || cell 3 || || border=2 ||! head 1 ||! head 2 ||! head 3 || || cell 1 || cell 2 || cell 3 || || border=3 ||! head 1 ||! head 2 ||! head 3 || || cell 1 || cell 2 || cell 3 ||
Nota: la tabla avanzada se colocará siempre a la derecha, tal como instruimos en código pero al mismo nivel de los elementos que tenga a continuación -uno al lado del otro-
Otros comandos nos permiten dar formato al texto para representar fórmulas, citas, etc
* Texto con '^superíndices^'.
* Texto with '_subíndices_'.
* Texto {-tachado-}.
* Texto {+subrayado+} (poco utilizado, se confunde con hipervínculo).
* Texto [+grande+], [++más grande++].
* Texto [-pequeño-], [--más pequeño--].
En la siguiente sección colocamos una imagen tomada del WikiSandBox: es un área donde podremos libremente practicar nuestros códigos, podremos hacer y deshacer sin problema alguno, programamos y visualizamos resultado mientras agarramos práctica, la idea es luego escribir rápidamente artículos completos y publicar de una vez sin mayor dilación.
«Sandbox» significa «cajón con arena» que nunca falta en los parques de los Estados Unidos y donde colocan a los pequeños y pequeñas para que desarrollen sus habilidades motoras sin peligro alguno; acá en Venezuela hacemos algo mucho mejor: los llevamos a las playas maravillosas de nuestro país.
Por defecto el texto está alineado a la izquierda, pero podemos centrarlo comenzamos la línea con «%center%» y «%right%» para alinearlo a la derecha.
Para que el texto «flote» a la derecha sobre el siguiente párrafo que haya a continuación iniciamos con «%rfloat%» y si lo queremos en un marco «%rframe%«.
Para aplicar color simplemente escribimos el color, en inglés, encerrado entre signos de porcentaje. Esto se aplicará por defecto al resto del párrafo a partir del código, si necesitamos solamente colorear una palabra escribiremos «%blue% palabras a colorear %black%«. Por defecto el color de fuente es negro, por eso escribimos %black% pero eso no es necesariamente cierto, todo depende del estilo general de la PmWiki (tema avanzado). Lo correcto para restablecer el color es cerrar con doble signo de porcentaje «%%».
También se pueden combinar los comandos, por ejemplo centrado y en color rojo: «%center red%».
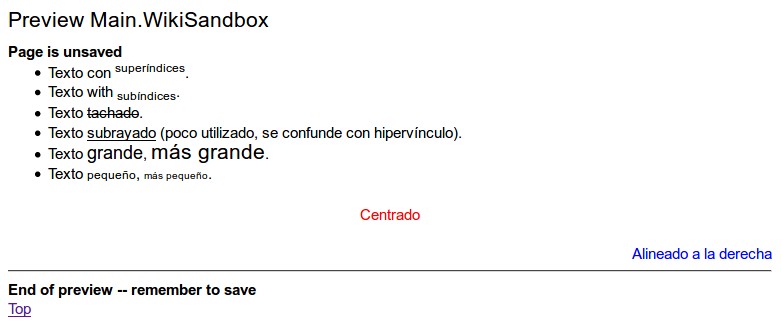
No necesariamente se deben colocar los códigos al inicio de un párrafo, por ejemplo, a mitad de un párrafo podremos escribir «%p red% indicando que el párrafo, representado por la letra «p» sea rojo «red» sin importar dónde lo ubiquemos: al principio, en el medio o al final. Similar comportamiento aplica para otros elementos:
Podremos definir clases de estilos, definidos por nosotros mismos. En mejor uso es poder escribir en castellano, especialmente para aquellos u aquellas que no dominan ese idioma. Para ello al comienzo de un artículo podríamos escribir lo siguiente:
%define=amarillo color=yellow% %define=fondo_amarillo bgcolor=yellow% %define=azul color=blue% %define=fondo_azul bgcolor=blue% %define=rojo color=red% %define=fondo_rojo bgcolor=red% %amarillo%Conocerás los principios básicos%% de la programación en PHP como su sintaxis, estructuras de control, etc. %azul%Además explorarás un nutrido conjunto de características%% y funcionalidades, las necesarias para desarrollar la mayoría de las aplicaciones, %fondo_rojo%como el acceso a la base de datos%%, el sistema de archivos, etc.

Así entonces será más fácil recordar los comandos, pero supone escribir guiones al principio de cada artículo. Es mejor definir estilos globales, que funcionen en toda la página PmWiki alojada, eso es avanzado y más adelante lo estableceremos en la configuración de instalación.
Pues con nuestros teclados o copiando y pegando podemos escribir los caracteres «especiales»: las vocales acentuadas, el símbolo de la moneda euro €, etcétera y para ello rigen las mismas normas del HTML: la «á» se escribiría «á» el símbolo del €: €.
Por increíble que parezca, para mostrar una imagen en nuestra PmWiki simplemente colocamos el enlace hacia la imagen web… ¡y listo! (en WordPress es igual, aunque no lo creáis, pero este tutorial es de PmWiki y no otra cosa, disculpad).
El meollo del asunto es que normalmente gustamos de darle formato a las imágenes, texto alterno si el navegador no puede mostrar imágenes -o las tienen bloqueadas de alguna manera-, títulos, tamaños, bordes, etc. Comencemos a realizar una lista con las principales características:
http://pmichaud.com/img/misc/pc.jpg
La palabra wiki proviene del idioma hablado en la isla de Hawaii, quincuagésimo estado federal de los Estados Unidos de América. Significa rápido y wiki wiki súper rápido (ya en los años 80 acá en Venezuela vendíamos un tinte para ropa llamado «wiki-wiki»: no teníamos dinero para comprar pantalones nuevos y los pintábamos de negro y listo, «pantalones nuevos» rápidamente).
Las páginas web que tienen un motor wiki son como cualquier otra página web pero tienen dos características únicas:
El caso concreto de PmWiki el Doctor Patrick Michaud (la letra «d» NO se pronuncia) es el autor con más de 40 años de experiencia en computación (graduado con «Post High Degree» en la University of Southwestern Louisiana -aquí le decimos Doctorado-) y podéis acceder a su página web http://www.pmichaud.com/ donde, faltaría más, faltaría menos con el motor PmWiki donde mantiene un resumen de su vida profesional y formas de contactarlo ya sea por correo eletrónico o redes sociales.

Fueron establecidas durante el desarrollo de PmWiki y aunque el Dr. Michaud comparte muchas de ellas no son exclusivas de su persona, de hecho mantienen un foro abierto a nuevas ideas y sugerencias para mantener activo este software a los requerimientos modernos de la humanidad.
Los pilares son:
Primero debemos descargarlo de forma comprimida desde PmWiki, solo pesa menos de medio megabyte, la versión estable 2.2.98 -ya os dijimos: PmWiki es sencillo y simple pero muy útil-.
Como un servicio a la comunidad por acá también la ponemos a la orden, si la queréis descargar desde acá.
Se ofrece paquetes adicionales para diferentes idiomas en esta dirección de la misma PmWiki.org pero deja mucho que desear por ahora para nuestro trabajo la vamos a dejar así, en purito inglés pero no creáis que nos hemos rendido con el castellano, de hecho tenemos en mente unas ideas laboriosas por realizar y una vez terminemos la publicaremos por acá.
Una vez descargado lo descomprimimos en nuestra carpeta /var/www/html -en nuestro caso usamos un servidor web Apache2 con PHP5 en nuestro ordenador en VirtualBox- y debemos darle los derechos adecuados de escritura para que se puedan grabar nuestras preferencias.
Se recomienda crear una carpeta llamada pmwiki en la carpeta pública de nuestro servidor web y redirigir debidamente modificando el .htaccess (o por otros métodos). No es la tarea de esta entrada y tomando en cuenta que tenemos un servidor de pruebas y por propósitos didácticos NO LO HAREMOS ASÍ sino que simplemente colocaremos los ficheros y directorios como si el servidor fuera dedicado a retribuir una sola página web.
Una vez hayamos copiado los archivos tendremos la siguiente estructura que pasamos a traducir directo del propio tutorial en inglés:
Por ahora esos son los ficheros y directorios iniciales, los cuales, por seguridad, solo necesitamos que tengan derecho de lectura más no de escritura. Para poder guardar nuestras configuraciones y futuros artículos debemos tener derechos de escritura en una carpeta especial llamada «wiki.d/«.
![]()
¡Atención! no confundir con la carpeta wikilib.d
Si nuestro servidor permite acceso vía SSH por ventana terminal usaremos el comando «chmod» para otorgar permisos de escritura, si es un servidor web compartido generalmente tenemos acceso vía softwfare CPANEL que permite lanzar un navegador de archivos y otorgar derechos de escritura a esas dos carpetas. También recordemos que el comando «chmod» funciona en muchos programas clientes FTP, así que cuando «subamos» los archivos de PmWiki podríamos cambiar de una vez los derechos de escritura.
Dado el caso que NO hayamos configurado lo anterior y nos decidimos por ejecutar directamente de una el fichero principal pmwiki.php éste nos lo recordará amablemente con un mensaje de que no podemos seguir adelante.
Pues bien, acá se mostrará la página de bienvenida con tutoriales e indicaciones -en inglés- de todo lo que explicamos acá en idioma castellano.
Dependiendeo de como tengáis configurado vuestro servidor, necesitaréis un archivo llamado «index.php» o si tenéis configurado tratar los archivos con extensión .html como .php debeis escribir en él lo siguiente:
[cc lang=»php» tab_size=»2″ lines=»60″]<?php
include(«pmwiki.php»);
?>[/cc]
Lo que nos toca por hacer es configurar el archivo config.php en la carpeta «local/«. Dicho archivo es de solo lectura pero debemos tener permisos de escritura para copiarlo desde la plantilla llamada «sample-config.php» (carpeta «docs/») la cual modificaremos a nuestro gusto y conveniencia: en nuestro ordenador donde hayamos descargado y descomprimido PmWiki copiamos el archivo con el nombre «config.php» lo modificamos para luego subirlo (vía https o sftp) a nuestra carpeta «local/».
Este fichero contiene las configuraciones comunes pero vienen inactivas gracias a un caracter numeral al principio de cada línea de comando, eliminando dicho caracter las «descomentamos» y ponemos a nuestro servicio.
¡LISTO! Guardamos y copiamos a su ubicación final y vemos los cambios recargando la página.
Al modificar config.php establecimos nuestra contraseña como administrador, nuestra llave para crear, modificar o eliminar contraseñas, es el más alto nivel efectivo en nuestro sitio. La reservamos para nosotros, los programadores y encargados del mantenimiento y funcionamiento de la página web en sí ya que la mayor del tiempo serán los autores los que estarán a cargo de proteger sus propios trabajos.
El enfoque que utilizaremos, siempre pragmáticos, es de ir de menos a más, según nuestras necesidades, analizemos:
Siendo un grupo pequeño solo se necesita que a nivel global todos los botones de edición de página tengan una simple contraseña. Para lograr esto debemos descomentar y modificar (o agregar) la línea siguiente en /local/config.php
$DefaultPasswords['edit'] = pmcrypt('nuestra_contraseña_de_edicion');
Acá no hay más complicaciones, solo es cuestion de comunicarse entre ellos y verbalmente dirimir sus diferencias, en teoría no debería haber mayor problema y si lo hubiera nosotros como administradores deberemos tener la última palabra y «reiniciar» la contraseña a nivel global para excluir a algún miembro de la edición de artículos -caso extremo-. Luego veremos que tal vez tengamos unas tareas adicionales que realizar, tened paciencia y os explicamos, vamos a continuar con la idea de grupos.
Manejar a esta cantidad de personas la cosa se complica un poco. Tratar de reunirlos todos a la vez va a ser difícil y si se lograra se nos va a ir el tiempo en reuniones grupales, lo cual es mucho trabajo para el poco dinero que nos pagan por la tarea. ?
El mejor enfoque en este caso es establecer nosotros mismos normas de publicación (grupo de páginas) de caracter privado por lo que tendremos que establecer contraseñas para poder leer este particular grupo de páginas. Establecidas las normas, ya saben a qué atenerse. Una vez «tamizados» los autores podremos elegir a dos sub administradores que nos ayuden en nuestro trabajo, pero ¿cómo lograr esto sin dar nuestra contraseña de edición a los subadministradores? A nivel global se pueden establecer matrices de contraseñas (esto ya es lenguaje PHP en sí) de nuevo en el ya famoso archivo config.php:
$DefaultPasswords['read'] = array(pmcrypt('alfa'), pmcrypt('beta')); $DefaultPasswords['edit'] = pmcrypt('beta');
«alfa» y «beta» serán dos contraseñas distintas, para elevar un autor a subadministrador (ojo, esta figura no está canonizada en el sistema PmWiki, la estamos «inventando» en este artículo práctico) pues le daremos una nueva contraseña que será «beta«. Es más, si son dos subadministradores, como proponemos ,nada nos impide generar una contraseña «gamma»:
$DefaultPasswords['read'] = array(pmcrypt('alfa'), pmcrypt('beta'), pmcrypt('gamma')); $DefaultPasswords['edit'] = array(pmcrypt('beta'), pmcrypt('gamma'));
Luego veremos que tal vez tengamos unas tareas adicionales que realizar, tened paciencia y os explicamos, vamos a continuar con la idea de grupos.
Acá la cosa se pone «color de hormiga»: ya en este punto debemos habilitar usuario y contraseña (léase «login» y «password») para todos y cada uno de los usuarios a fin de determinar quién hizo qué y tomar las medidas correspondientes. ¿Recordáis la figura de subadministradores? Pues bien, ¡vamos a necesitar entre 3 y 6! Esto es así porque el mantener cuentas y contraseñas de usuario se va a llevar bastante trabajo y necesitamos
El primer paso para habilitar esta característica es agregar (o descomentar) la siguiente línea en /local/config.php:
include_once("$FarmD/scripts/authuser.php");
Demás está decir que ya habremos establecido nuestra contraseña de «admin», lógicamente, en vez de la que trae por defecto la instalación de PmWiki (un hacker -buenas intenciones- o un cracker -malas intenciones- lo primero que haría sería intentar entrar con esa contraseña por defecto).
La manera de registrar a los usuarios es editar una página llamada pmwiki.php?n=SiteAdmin.AuthUser, es decir, al guión principal llamado pmwiki.php le «pasamos» en la barra de direcciones un signo de cierre de interrogación y solicitará nombre de usuario y contraseña al editar (usaremos la superclave de admin) y agregaremos cada cuenta con la siguiente sintaxis:
nombre_de_usuario: (:encrypt contraseña:)
Guardamos la página y la contraseña se mostrará encriptada. Dichas cuentas, por manía de orden, la colocamos justo después del subtítulo «Login accounts» y más abajo veremos el subtítulo «Authorization groups» donde podramos definir los grupos de usuarios que inventamos, a saber: autores y subadministradores.
@autores: Kevin, Jimmy @subadministradores: Kevin
Al crear este tipo de grupos de usuarios se nos facilita enormente la tarea de administración si invertimos el enfoque: nombramos a cada usuario a los grupos que puede pertenecer, el ejemplo anterior pero por usuarios:
Kevin: @autores, @subadministradores Jimmy: @autores
¿En qué nos beneficia todo esto? En que en cada página podemos definir cuales grupos tienen acceso e incluso podemos delegar -con sumo cuidado- de poder editar la mismísa página SiteAdmin.AuthUser. A primer vista esto parecería una locura pero es que para definir cuentas de usuarios y grupos de usuarios la otra manera de hacerlo permitir editar el fichero config.php y esto no es para que lo haga todo el mundo, cualquier cosa podría salir mal y tendríamos nosotros mismo que enmendar el capote.
Luego veremos que tal vez tengamos unas tareas adicionales que realizar, tened paciencia y os explicamos, vamos a continuar con la idea de grupos.
Manejar tal cifra de personas ya no es posible hacerlo así, «de manera manual», tendremos que recurrir al uso de protocolos y normas adecuados y que manejen bases de datos para llevar cuenta de todo. PmWiki ofrece acceso mediante el protocolo LDAP pero escapa al alcance de este tutorial. También existe apoyo para htpasswd: el cual utiliza el servidor Apache2 pero no supone ventaja alguna porque al igual que PmWiki se basa en texto plano -incluso encriptado- y no utiliza base de datos además deja por fuera a Ngix que es otro poderoso servidor web, así que no le vemos futuro a esa alternativa.
Además, para manejar tal cantidad de usuarios, se espera una gran cantidad de artículos y por ello debemos hacer uso de un manejador de base de datos que no exija demasiado recursos de cómputo: SQLite es el elegido para ello. Para habilitar su uso debemos descargar y ejecutar este guion creado por Petko Yotov con el cual creamos la base de datos, tablas, índices y relaciones y una vez hecho esto si que debemos modificar de nuevo el consabido config.php en alguna de sus primeras líneas lo siguiente:
[cc lang=»php» tab_size=»2″ lines=»60″]include_once(«$FarmD/cookbook/sqlite.php»);
$WikiDir = new PageStoreSQLite($WorkDir.’/pmwiki.sqlite.db’, 1);
$WikiLibDirs = array(
&$WikiDir,
new PageStore(‘wiki.d/{$FullName}’),
new PageStore(‘$FarmD/wikilib.d/{$FullName}’)
);[/cc]
El fichero pmwiki.sqlite.db será entonces el único que conservará las página que creemos y será el que dabamos respaldar llegado el momento necesario. Esto apenas es un resumen ya que todo programador sabe muy bien que no hay base de datos «rebeldes» sino mal administradas. Por ejemplo, de tanto en tanto deberemos ejecutar la orden pmwiki.php?action=vacuum; también podremos establecer un valor automático para que ejecuta esta acción por nosotros si lo establecemos en config.php:
$SQLiteAutoVacuum = 300;
Incluso si le colocamos el valor de cero (no ejecutar), siempre podremos hacerlo cuando necesitemos con ?action=vacuum.
Pues que varias veces nombramos unas dichosas «tareas adicionales» que debíamos realizar para «cerrar el círculo de seguridad» para ello los siguientes datos:
$Author = $AuthId; # after include_once()
session_name('XYZSESSID');
En PmWiki «normalizaron» los diálogos comunes, que son las instrucciones que visualiza el usuario. Las más visibles de ellas son «View Edit History Print Backlinks» que vemos en la parte superior derecha de cada página. El mecanismo es el siguiente: existe un archivo principal, el núcleo o corazón de PmWiki llamado «pmwiki.php» el cual nuestro servidor web ejecuta y carga los diversos componentes -que no vienen al caso por la complejidad del asunto-.
Lo que queremos ejemplarizar es cuando se carga el archivo «Site.PageActions» en la carpeta wililib.d allí tenemos unos cuantos mensajes al usuario, uno de ellos un enlace para modificar la página que esté en ese momento visualizando, otro para ver su historial además de las paǵinas relacionadas (y hay más enlaces/opciones).
En forma de matriz llamada text() se cargan los diferentes mensajes predefinidos por una estructura (de nuevo, estamos simplifanco al máximo) hasta llegar a los simples mensajes que acompañan una «acción», cargar pmwiki.php más el parámetro a ejecutar (cuando el usuario hace click en la opción/enlace correspondiente):

Aquí es que vamos a llegar al meollo del asunto: dichas palabras «Edit», «History» y «Backlinks» aparecen en el código no como texto en sí, sino como «variables»: «$[Edit]», «$[History]» y «$[Backlinks]» de manera tal que esas variables definidas se puedan especificar en un archivo con la extensión «.XLPage» con el siguiente contenido según nuestros ejemplos seleccionados:
Resulta ser que para nosotros en supuesto «idioma español» nos asignaron dos letras «Es» de esta manera nuestro idioma vienen ser definidos los mensajes comunes en un archivo llamado «PmWikiEs.XLPage«. Pensamos que deberíamos diferenciarnos porque en España se hablan varioas idiomas: gallego, castellano, catalán, vasco y portugués… que está bien, Portugal se independizó y cogió otro rumbo y otro idioma pero forma parte de lo que los romanos al civilizar llamaron «Hipania» (perdón por la lección de historia, je, je, je). Somos de la idea de que deberíamos tener OTRAS letras como, se nos ocurre «cas» (ya «ca» está tomado por el idioma catalán) pero en fin, todos llevamos dentro nuestro pequeño «Don Quijote de la Mancha» y en cada molino vemos fieros gigantes ¡ja!
Al abrir la página principal de PmWiki sin haberla internacionalizado (a eso vamos) en el panel izquierdo («slide panel») aparecerá varias opciones -en inglés- de las cuales las tres primeras (hay site opciones en esa sección) dirán:
Si colocamos el puntero sobre ellas, sin hacer click, veremos que sus enlaces web (llamados a pmwiki.php acompañados de un parámetro) serán los siguientes -coloreamos para que veáis las diferencias, no colocamos el enlace completo porque cada dominio web es diferente-:
Lo coloreado en color marrón son «páginas del sistema» de PmWiki y son las que debemos traducir ¿recordáis las dos letras de código de nuestro idioma? Pues las debemos intercalar para que apunten a los archivos que vamos a descargar con las traducciones:
Del siguiente enlace podréis descargar los idiomas disponibles en incluso un «megapaquete» con todas las traducciones. Nosotros solo descargaremos el archivo «i18n-es.zip» el cual descomprimiremos y «subiremos» a nuestro servidor teniendo cuidado de darle los permisos de lectura necesarios y los ubicaremos todos en la carpeta wikilib.d
En este punto debemos editar de nuevo el dichoso fichero llamado «config.php» que está ubicado en la carpeta /local y modificar y adicionar las siguientes líneas:
include_once("scripts/xlpage-utf-8.php"); # optional
XLPage('es','PmWikiEs.XLPage');
La primera línea en realidad la descomentamos porque viene así de la plantilla por defecto, y ese comentario que indica «optional» osea opcional para nosotros es obligatorio (ya eso lo explicamos en nuestro tutorial HTML). La segunda línea indica el llamar a la función XLPage y tiene dos parámetros:
No sabemos quien visitará nuestra página en este mundo tan globalizado, pero si utilizan un navegador web que se haya programado según las normas del W3C lo mejor que podemos hacer es incluir en config.php el siguiente guion:
[cc lang=»php» tab_size=»2″ lines=»40″]$lang = substr($_SERVER[‘HTTP_ACCEPT_LANGUAGE’], 0, 2);
switch ($lang){
case «es»:
XLPage(‘es’,’PmWikiEs.XLPage’);
break;
case «en»:
XLPage(‘en’,’PmWikiEn.XLPage’);
break;
default:
XLPage(‘en’,’PmWikiEn.XLPage’);
break;
}[/cc]
En la primera línea por medio de PHP le preguntamos al servidor web el encabezado con que solicita la página nuestro visitante y extraemos las dos primeras letras para luego seleccionar de los idiomas disponibles que tengamos instalados, y por defecto, si no se consigue, pues lo mostramos en ingéls, el lenguaje «materno» de PmWiki. Lo hemos probado con Mozilla Firefox 53 y funciona.
PMWiki funciona como la Wikipedia, está abierta para que todos y todas coloquemos nuestras sugerencias y propuestas. Por ello el 13 de junio de 2017 propusimos en la página oficial del Proyecto PMWiki el código anterior y a la fecha de hoy la propuesta se mantiene, ergo, no la han eliminado y suponemos que ya con tanto tiempo transcurrido queda aprobada de manera implícita. Dicha propuesta la pueden consultar en este enlace y si aun dudaís de nuestra autoría basta conq ue hagáis click en el historial del artículo. Fue un honor haber contribuido en algo al tema.
Pues tan simple como recargar la página y los mensajes comunes estarán en nuestro idioma… pero hasta allí llega nuestra «alegría de tísico» (por lo poco que dura antes de entrar en un atque de tos). Resulta que igual nos aparece en inglés todo lo demás y he aquí que debemos comenzar a trabajar.
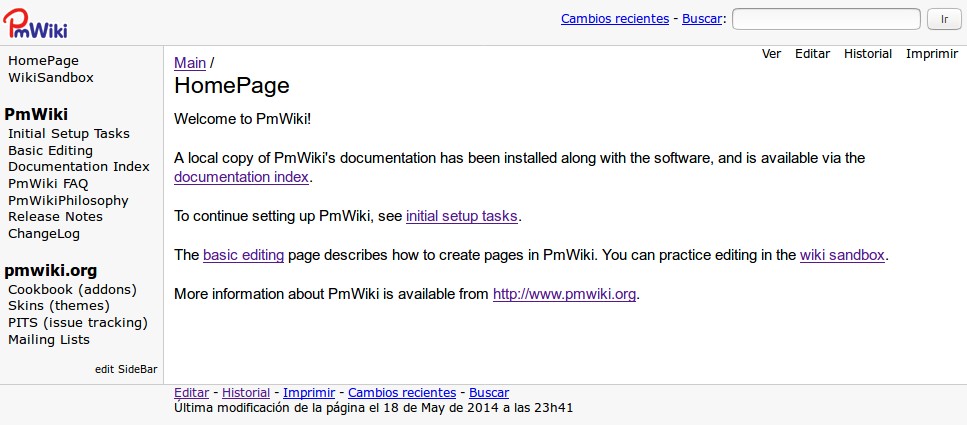
La primera página que modificaremos es precisamente la principal llamada «Main.HomePage» la cual, por ahora, no hemos encontrado manera de cambiar al castellano. Lo que es cierto es que podemos -y debemos- modificarla borrando todo el contenido en inglés e ir creando nuestro propio contenido para luego modificar el panel izquierdo («edit SideBar»).
Aunque suene extraño vamos a aventurarnos a crear dos grupos de páginas de una vez. Para ello ya estamos modificando la «Main.HomePage» (luego de haber introducido nuestra contraseñade edición, si la hubiéramos establecido) y escibiremos el siguiente código:
[[WikiAeroplanos | Aviones]] * [[WikiAeroplanos.Cazas | Uso militar]] * [[WikiAeroplanos.Pasajeros | Transporte]] * [[WikiAeroplanos.Hidroaviones | Mixto]] [[WikiTrenes | Trenes]] * [[WikiTrenes.Electricos | Siglo XXI]] * [[WikiTrenes.Vapor | Siglo XX]]
Le damos guardar y al recargar la ápgina veremos lo siguiente:
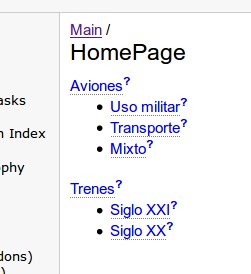
¿Observáis los signos de interrogación que nosotros no escribimos? Pues es la maner de PmWiki indicarnos que dicho tema no ha sido escrito. Aquí radica la sencillez y rapidez de PmWiki: cuando hacemos click se abre inmediatamente para editar cada una de las págins que queremos desarrollar. He aquí que le vamos agregar un poco de complejidad a cada una de ellas.
Un lenguaje importante y que hemos dejado de lado por años es el ya muy famoso lenguaje PHP. En desagravio publicamos esta entrada y le queremos dar características especiales: no insisteremos en ser detallistas al extremo, se trata de una introducción, un tutorial que lleve paso por paso a cualquier persona que desee aprender dicho lenguaje de programación. Por ello no publicaremos su historia, configuración del servidor, etcétera. Os recordamos que para aprender PHP sería bueno tener conocimientos mínimos de HTML, CSS y JavaScript.

Interesante es saber sobre cómo funciona el navegador web Mozilla Firefox (para nosotros, nuestro favorito) y vamos a diseccionar y explicar de manera sencilla, sin mayores pretensiones, sus diversos componentes. Para ello comenzaremos de atrás para adelante: el último Proyecto de Mozilla Firefox llamado «Quantum«, ¡Investiguemos juntos!