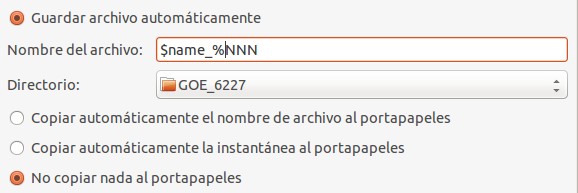
Recientemente tuvimos la estupenda oportunidad de asistir al Congreso de Tecnologías Libres 2016 y tuvimos la necesidad (madre de las invenciones) de publicar las fotografías que capturamos en el evento. En un principio redimensionamos unas pocas para nuestra cuenta Twitter, pero pronto nos dimos cuenta que la tarea es tediosa y debemos aligerar la carga con herramientas del Software Libre. No hace mucho tiempo uno de nuestros faros en GNU/LINUX -en lengua castellana- Ubunlog publicaron un artículo sobre ImageMagick: instalación y usos básicos del mismo. Pero como nos percatamos que el proceso masivo de 300 imágenes en una sola linea de comando puede «colgar» nuestra computadora por largo tiempo decidimos publicar esta entrada con el valor agregado de nuestros anteriores temas publicados y además unos «scripts» que tal vez les puedan ser útiles a ustedes, amén de la recomendación de un «plugin» para WordPress con el cual escribimos estas líneas a la fecha (quien sabe, tal vez algún día evolucionemos hacia otra plataforma de blogging).
ImageMagick.
Breve historia.
Bien lo retrata en su página web la historia de ImageMagick que pasamos a traducir y resumir, contada en idioma inglés por John Cristy (Principal ImageMagick Architect):
Corría el año de 1987 cuando el Dr. David Pensak, supervisor de John Cristy en la empresa de productos químicos llamada Dupont, le solicitó poder mostrar imágenes de 24 bits (color verdadero) en los nuevos -y costosos- monitores de 256 colores ya que hardware de aquella época tenía muy poca potencia -y por ende debían ser convertidos a 256 colores-. Es por ello que John Cristy utilizó el buscador de moda para ese entonces: Usenet. Obtuvo respuesta de Paul Ravelin donde le indicaba no una, sino varias soluciones de software para la tarea encomendada y puso a su disposición un servidor FTP del «Information Sciences Institute» (ente adscrito a la Universidad del Sur de California) con el código fuente de numerosas aplicaciones. Tras varios años de conseguir muchas de las respuestas, en lo que a computación se refiere, en su trabajo para la empresa Dupont -y el exigente Dr. David Pensak- él se decidió a mejorar y retribuir todo el software utilizado y decidió igualmente liberar las herramientas de procesamiento de imágenes para que otros -¡ejem! nosotros por ejemplo- nos beneficiriamos de ello (de hecho nosotros contribuimos en esta entrada con un «script» en «bash» y otro en lenguaje PHP, así que la historia ¡sigue y sigue!).
Pero como del «dicho al hecho hay enorme trecho» él primero tenía que solicitar permiso a la empresa Dupont en la cual laboraba, ya que en horas de trabajo fue que él desarrolló dichas herramientas. Es así que de nuevo interviene el Dr. David Pensak y convence a sus superiores de otorgar permiso de «copyleft» a John Cristy ya que no era ni un producto químico ni biológico y ellos no tenían noción del valor del software para entonces. Es así que el 1° de agosto de 1990 ImageMagick ve la luz en Usenet en el grupo «comp.archives» (gracias de nuevo Dr. Pensak).
A mediados de los años 1990, y con miles de usuarios en el mundo entero, ImageMagick versión 4.2.9 fue incluido en un nuevo sistema operativo que era distribuido libremente: GNU/Linux.
Es así que luego de su distribución junto a GNU/Linux el sr. Bob Friesenhahn contacta a John Cristy a fin de «normalizar» la aplicación para que sea compatible con el resto de las herramientas de dicho sistema operativo (más adelante veremos que gracias a esto es que hoy en 2016 nosotros podemos desarrollar «scripts» o guiones funcionales y compatibles en otros idiomas de programación).
A partir de la versión 5 de ImageMagick se incorpora de esta manera el lenguaje C++ y se unen al desarrollo los siguientes programadores:
- Bob Friesenhahn (proponente)
- Glenn Randers-Pehrson.
- William Radcliffe.
- Leonard Rosenthol.
Ya eran decenas de miles de usuarios de ImageMagick cuando sucedió lo impensable: el desarrollo evolucionó tanto que en un momento dado la nueva versión era incompatible con una API existente e hizo que los usuarios reaccionaran bruscamente y exigieron paralizar la programación mientras que los desarrolladores quería seguir adelante. John Cristy no dio su brazo a torcer así que ImageMagick -de la mano de Bob- recibe su primera bifurcación de código y nace Magick++, el primer «fork» (como se conoce en el idioma inglés). Recordemos que precisamente esta es una de las normas de la licencia que rige el software libre, así que John Cristy continuó solo su camino.
Pero no trabajó solo por mucho tiempo: Anthony Thyssen le indicó ciertas fallas en la linea de comandos, los cuales no solo se corrigieron sino que también se mejoraron hasta tal punto que vieron que era necesario emitir una nueva versión: ImageMagick 6.0.
Tan lejos llegaron las librerías de Anthony Thyssen que el mismo John Cristy quedó sorprendido de la capacidad del código fuente original, y que públicamente reconoce la labor hecha en el avance de la colaboración en proyectos de software libre. A continuación, y en honor de quienes contribuyeron (y respetando las normas de la licencia GNU bajo la cual está concebida ImageMagick) nombramos a:
- Fred Weinhaus (cientos de «scripts» que son libres para uso no comercial, caso contrario contactar a Fred Weinhaus para su autorización).
- Glenn Randers-Pehrson (gurú del formato PNG).
- Dirk Lemstra (desarrollo en ambiente «Windows» bajo .NET)
ImageMagick tiene ya una edad de 25 años al momento de escribir este artículo, y rumbo a los siguientes 25 años se desarrolló la versión 7.0 con importantes novedades descritas en este enlace web. Además, ustedes pueden encontrar la licencia que rige a ImageMagick en este otro enlace.
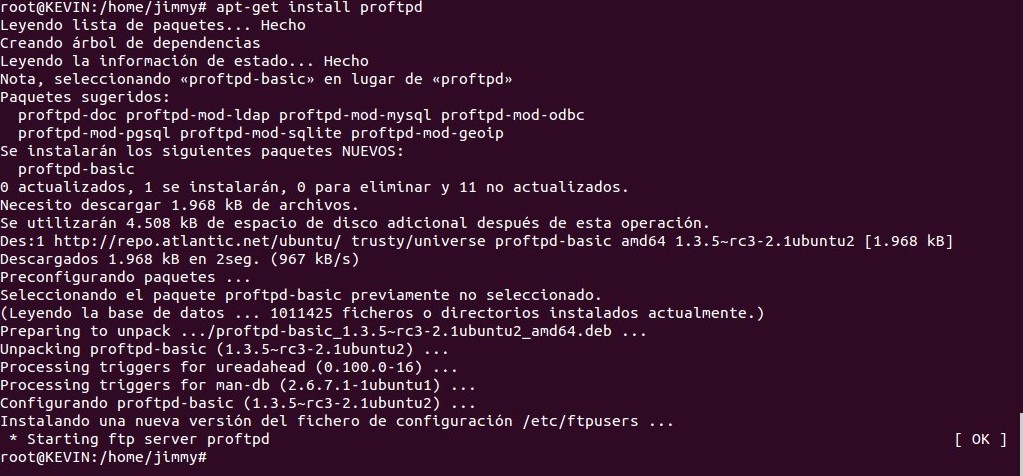
Instalación de ImageMagick en Ubuntu.
La instalación es común a las distros GNU/Linux basados en Debian:
apt-get install imagemagick
Recuerden que deben tener derechos de usuario raíz, para mayores detalles al trabajar la línea de comandos consulten nuestro tutorial al respecto.
Finalmente, para verificar si está correctamente instalado en nuestro ordenador, podemos ejecutar las siguientes lineas de comando con las cuales «crearemos» el logotipo de ImageMagick, visualizaremos sus especificaciones con el comando identify y luego lo abriremos en una ventana gráfica con el comando display:
convert logo: logo.gif identify logo.gif display logo.gif
Al ejecutar el comando display tal vez recibiréis un mensaje un tanto singular: el reporte de unas fuentes de texto faltantes. La explicación rápida es que son fuentes privativas, no libres, y no acompañan a las distribuciones GNU/Linux. Más información en este enlace web.
Tal vez, cuando estéis más avezado o avezada con ImageMagick, necesitareís instalar las librearías avanzadas (una de tantas que existen) con el siguiente comando:
apt-get install graphicsmagick-imagemagick-compat
Como vosotros podéis ver, de primero utilizamos el comando convert el cual pasamos a describir en la siguiente sección.
Comando «convert».
El comando que nos interesa para redimensionar de manera masiva -y a nuestra manera- una gran cantidad de imágenes es el comando «convert«. Específicamente para redimensionar lo acompañamos del argumento «-resize» y de seguido los dos valores de ancho y alto deseados. Sin embargo, debemos conocer un poco más acerca de algunos de los otros argumentos disponibles:
- Lo más básico: renombrar imágenes de manera masiva seleccionando un patrón de búsqueda y un prefijo que automáticamente numerará el comando. Por ejemplo si introducimos la orden «convert *.jpg fotos.jpg» ImageMagick renombrará todos los archivos jpg en la carpeta donde estemos ubicados en la linea de comandos de la siguiente manera: foto-1.jpg , foto-2.jpg , foto-3.jpg , etc.
- Ya vimos cómo renombrar masivamente un grupo de imágenes pero para convertir una sola solo debemos, desde luego, indicarle su nombre específico, y si queremos o necesitamos, otro nombre específico de salida para mantener el original; es decir, si omitimos el segundo nombre ImageMagick reemplazará el archivo de imagen original -cuidado con esto-. Las siguientes opciones soportan ambas maneras en este párrafo descritas y renombran masivamente según el párrafo anterior.
- Para rotar una imagen utilizamos el argumento «-rotate» seguido del ángulo a rotar, por ejemplo «convert imagen.jpg -rotate 90 nueva_imagen_rotada.jpg«.
- Si queremos convertir a otro formato de archivo simplemente especificamos el o los archivos deseados acompañado del nombre con la extensión deseada. Por ejemplo «convert imagen.jpg imagen.png» o si queremos convertir todas las imágenes jpg en una carpeta: «convert *.jpg imagen.png» (recordad que ImageMagick agregará un sufijo numerado a cada archivo convertido: imagen-1.png , imagen-2.png , imagen-3.png , etc.)
- También podemos bajarle calidad a una imagen utilizando el argumento «-quality» acompañado del porcentaje deseado -formato jpg-.
- Si necesitamos redimensionar utilizamos, por ejemplo, «convert imagen.jpg -resize 1024×768» con lo cual obtendremos una imagen de tamaño 1024 píxeles de ancho por 768 píxeles de alto sin conservar el archivo original. Para obtener un archivo nuevo (otro ejemplo) emplearíamos «convert imagen.jpg -resize 1024×768 imagen_redimensionada.jpg«.
- Por último podemos combinar los diferentes argumentos, teniendo en cuenta el problema con el que nosotros nos tropezamos: el redimensionamiento masivo de imágenes puede hacer que nuestro ordenador quede bloqueado durante un buen tiempo, por eso decidimos utilizar un «script» que procesa uno a uno cada archivo.
- Actualizado el miércoles 18 de septiembre de 2019: el comando convert es compatible con gif animados como el siguiente que rotamos 180° para mostrar el signo de interrogación de apertura:

Uso de ImageMagick en un «bash script».
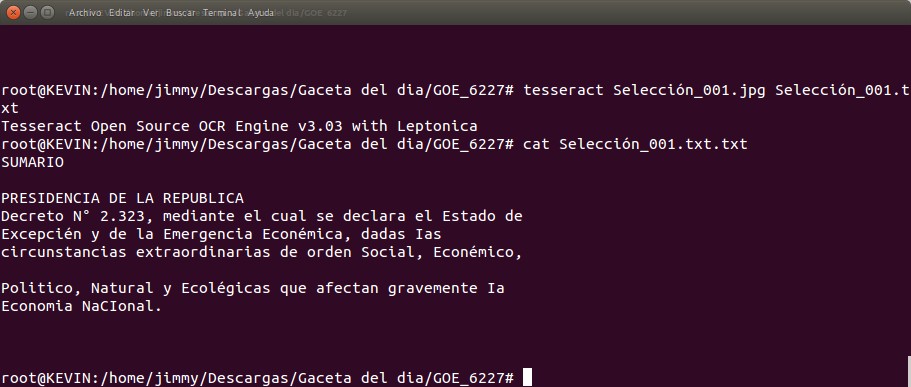
Ya en una entrada anterior hablamos procesar una serie de imágenes y aplicarle Reconocimiento óptico de caracteres con el programa Tesseract y vamos a reutilizar el «script bash» o proceso por lotes allí muy bien explicado, así que si os gusta id, leedlo y volved.
#!/bin/sh ####Licencia de uso### # Copyright 2016 Jimmy Olano at ks7000.net.ve # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. ###################### patron="P*.JPG" nomarch="lista.txt" clear ls $patron > $nomarch while read linea do echo "Procesando "$linea convert $linea -resize 1024x768 $linea echo "aplicando logotipo a "$linea php funde_logo.php $linea rm $linea done <$nomarch rm $nomarch echo "Trabajo terminado, imagenes redimensionadas e insertadas con logotipo."
Como veís publicamos de una buena vez el script y pasamos a describirlo linea por linea para su rápida comprensión:
- En la línea N° 1 especificamos que es un archivo de procesos por lotes.
- De la línea 2 a la 16 le establecemos la licencia Apache la cual es adecuada para pequeños proyectos y así garantizamos legalmente que nuestro trabajo se podrá seguir compartiendo y ampliando con el tiempo y se impedirá la creación de patentes hechas a base del mismo.
- En la línea 17, entre paréntesis, colocamos el patrón de archivos a buscar para redimensionar. Nosotros utilizamos «P*.JPG» por nuestra cámara marca Panasonic que le agrega ese prefijo seguido de una numeración única y consecutiva.
- Línea 18: asignamos el nombre del archivo donde guardaremos los nombres de los archivos a redimensionar. Nota: de hecho sabemos que hay una estructura alterna más eficiente para procesar archivos: «for file in *.png; do comando; done», la idea de utilizar un archivo auxiliar es para, a futuro, poder llevar auditoría o registro de los archivos modificados. Es así que podemos, por ejemplo, cambiar el nombre de «lista.txt» a «archivos_redimensionados_dia_mes_año.log» por la extensión utilizada en inglés para el verbo «to log» o registrar o llevar un registro.
- En la línea 19 limpiamos la consola para legibilidad en la ejecución de la tarea.
- En la línea 20 buscamos los archivos que cumplan con el patrón de búsqueda de la línea 17 y guardamos sus nombres -para posterior uso- en el archivo nombrado de la línea 18.
- De la línea 22 a la 28 se encuentra el ciclo o rutina principal deseado. En la línea 20 borramos -a menos que debamos hacer auditoría- (ver explicación de la línea 18). Con la línea 21 notificamos al usuario que la tarea ha finalizado (más sin embargo no llevamos una variable lógica -verdadero o falso- con los resultados de cada uno de los comando ejectuados, es susceptible de ser emjorado). A continuación mostramos las líneas debidamentes numeradas, trabajo hecho y alojado cortesía de Github:
Ahora pasamos a describir la rutina principal:
- En la línea 21 comenzamos a leer el archivo «lista.txt» el cual contiene los nombres de los archivos con los cuales trabajaremos.
- Entre la línea 21 y 28 establecemos el ciclo que se ejecutará hasta que hallamos leído de manera secuencial todos y cada uno de los nombres almacenados.
- En la línea 23 le indicamos al usuari sobre cual archivo vamos procesando.
- Línea 24: aquí es donde utilizaremos a imageMagick con la variable «$linea» que contiene el archivo que redimensionaremos (ver línea 23). Usamos el argumento «-resize» para obtener una imagen de 1024 por 768 píxeles reemplazando el archivo original.
- Línea 26: llamamos a un «script» o guión en lenguaje PHP. Lo explicaremos en la sección siguiente, pero os adelanto que de allí obtendremos un archivo totalmente nuevo.
- Línea 27: borramos el archivo original a fin de ahorrar en espacio en disco (no, no importa si ya tenemos discos duros con decenas de terabytes: cuando montamos un servidor web que reciba decenas de miles o incluso millones de visitas el ahorro de espacio en disco en muy importante).
Uso de PHP en un guión o archivo de proceso por lotes.
Aunque a la fecha no hemos escrito un tutorial sobre lenguaje PHP podemos adelantar que es un lenguaje de proceso por lotes de lado del servidor lo cual lo convierte en una poderosa herramienta para realizar páginas web de manera dinámica e interactiva con el usuario.
Ya vimos cómo con el lenguaje de marcación HTML5 podemos «escribir» o hacer páginas web pero limitadas a presentar siempre el mismo aspecto, y para cambiarlo debemos tomar el archivo, editarlo y guardarlo para, por ejemplo, agregar una nueva imagen o texto a nuestra web. Con el lenguaje PHP podremos, mediante un guión -con extensión .php- insertar comandos que responden a variables para, por ejemplo, mostrar diferentes logotipos según el tamaño de pantalla del dispositivo con la cual visitan nuestra página e incluso conectarnos a una base de datos para extraer texto, imágenes o cualquier otra información allí almacenada y así «personalizar» nuestro portal web. Es por ello que se habla de «páginas web estáticas» y «páginas web dinámicas»: con PHP obtenemos HTML según lo que necesitemos exhibir de acuerdo a variables de tiempo o valores específicos.
De hecho, el lenguaje con que funciona este blog está escrito en PHP y al conjunto de guiones -o procesos por lote- se denomina WordPress y estas líneas están guardadas en una base de datos MySQL. Hay muchísimos tutoriales sobre lenguaje PHP que podéis buscar con DuckDuckGo así que no profundizaremos demasiado en esta presentación pero es necesario que para continuar nuestra enseñanza visitéis, leed y comprended nuestra entrada sobre creación de imágenes CAPTCHA ya que las librerías que utilizaremos son las mismas. Y no os preocupéis, no vamos a montar un servidor web en el estricto sentido de la palabra, pero si usaremos elementos que se usan de manera común en ellos pero con la novedad de que lo ejecutaremos con la línea de comandos.
Línea de comandos en PHP.
En el sitio web oficial de PHP se describe detalladamente el uso de archivos PHP en una ventana terminal (linea de comandos). Allí detallan que hay tres maneras de ejecutar archivos con contenido PHP (no necesariamente con extensión «.php») desde la línea de comandos:
- Decirle a PHP que ejecute un archivo específico, por ejemplo «php archivo.php».
- Decirle a PHP que ejecute lo que a continuación se escribe, siempre colocandolo entre comillas simples, por ejemplo «php -r ‘$algo=4; print_r($algo);’».
- Concatenar comandos «bash» con el símbolo de tubería «|», eso en GNU/Linux es llamado standard input (stdin), por ejemplo «php -r ‘phpinfo();’ | grep «GD»»
En la tercera opción colocamos un ejemplo para conocer si tenemos instaladas las librerías GD necesarias para nuestro caso: insertar un logo en todos de cada una de las imágenes que deseamos redimensionar. Al ejecutarlo podremos ver algo como esto:
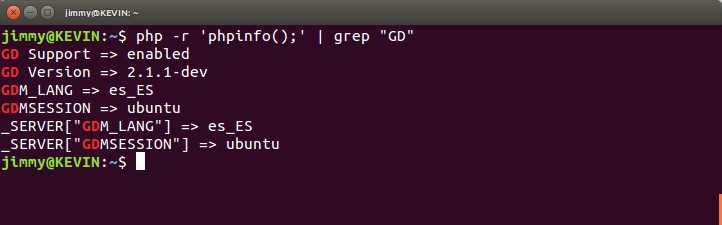
Buscamos que «GD Support» esté habilitado, «enabled»; caso contrario debemos instalarlo con la siguiente orden:
sudo apt-get install php5-gd
Asimismo se indica que se le pueden pasar argumentos dados al ejecutar un guión PHP invocandolos dentro del guión con el comando «$argv[]». Se debe colocar entre corchetes el número de argumento en el mismo orden que se escribe en la línea de comandos, haciendo la salvedad que $argv[0] siempre será el nombre del archivo que contiene las instrucciones en lenguaje PHP.
Veamos unos sencillos ejemplos:
- Creamos un archivo php con el siguiente contenido:
<?php print_r($argv[0]) ?>
- Luego llamamos al script con la siguiente orden «php archivo.php»
- Por pantalla veremos algo parecido a esto:

Explicación de nuestro bash en PHP.
Como ya estudiamos de manera resumida y rápida el uso de la línea de comandos con guiones PHP, a continuación mostramos de manera numerada -cortesía de Github- el archivo de proceso por lotes «funde_logo.php«:
Y describimos línea por línea su funcionamiento:
- En la línea 1 declaramos que usaremos el lenguaje PHP entre esta línea y la línea 46 (para este caso todo el archivo).
- De la línea 2 a la 27 insertamos las licencias de uso, son dos porque la primera aplica al guión en sí, su código fuente, y la segunda para indicar que estamos utilizando código escrito en PHP que de por sí tiene su propia licencia de uso.
- En las líneas 28~30 insertamos un comentario sobre lo que realizaremos.
- En la línea 31 cargamos el archivo que recibimos desde el primera argumento externo (argumento externo) al guión mediante el comando imagecreatefromjpeg en la variable $destino .
- En las líneas 32~33 insertamos comentarios adicionales.
- En la línea 34 cargamos el archivo de imagen (que contiene el logotipo deseado en la imagen redimensionada creada con anterioridad fuera del guión PHP) en la variable $origen.
- Líneas 35 y 36 más comentarios.
- En la línea 37 se hace el trabajo principal: insertamos el logotipo en la imagen con el comando imagecopymerge. Este comando merece una explicación detallada a continuación.
- El comando imagecopymerge tiene los siguientes argumentos:
- El nombre del archivo que le insertaremos el logotipo.
- El nombre del archivo del logotipo.
- La coordenada X donde insertaremos el logotipo en la imagen.
- La coordenada Y donde insertaremos el logotipo en la imagen.
- La coordenada X del logotipo en si mismo.
- La coordenada Y del logotipo en si mismo.
- La anchura deseada del logotipo.
- La altura deseada del logotipo.
- El porcentaje de transparencia del logotipo: 100 es completamente opaco, no se mostrará nada el archivo original en el logotipo insertado
- Líneas 38 a 40: comentarios.
- Línea 41: preparamos lo que tenemos en memoria para volcarlo al disco duro con el comando imagejpeg con los argumentos siguientes: la variable $destino (a la cual le insertamos el logotipo), el nombre con el que queremos guardar el archivo (un prefijo llamado «CTL2016-» junto al nombre del archivo original pasado por el argumento externo al script PHP) y, por último, el nivel de calidad deseado, en este caso un 80%.
- Líneas 42, 43, comentarios.
- Líneas 44 y 45 liberamos la memoria donde almacenamos las imágenes.
Debemos aclarar que para saber las coordenadas donde insertaremos el logotipo, pues simplemente abrimos una de las fotografías tomadas con el software Pinta, luego abrimos el logotipo con el mismo programa en otra ventana, seleccionamos todo y copiamos, volvemos a la primera venta y pegamos y arrastramos a la posición deseada y tomamos nota de las coordenadas, hágase según arte como dicen en farmacia.
En cuanto a las coordenadas del logotipo pues sencillamente es TODO: de [0, 0] hasta [370, 150] : el ancho y alto total del mismo.
El comando «mogrify».
Uno de nuestros «faros» en el mundo específico de Ubuntu es la página web Ubunlog.com quienes publicaron un mini tutorial con otro comando de ImageMagick: el comando mogrify.
Cómo redimensionar fotos en bloque en Ubuntu – https://t.co/FoTg9q230h pic.twitter.com/w61EL2uX0O
— Ubunlog (@Ubunlog) 1 de julio de 2016
Podéis ir a ese sitio web y leer (y aprender) sobre ese otro comando que nos permite redimensionar de manera masiva nuestras imágenes. Un detalle que notamos con este comando es que podemos redimensionar a cualquier tamaño específico pero si queremos -o necesitamos- que la imagen se ajuste (encoja y alargue, según sea el caso) debemos acompañar del signo de cierre de admiración para denotar esto. Es una ligera diferencia, he aquí un ejemplo de cada uno de los dos comandos:
mogrify -resize 800x200! prueba.jpg
El comando redimensionará exactamente a 800 píxeles de ancho por 200 píxeles de alto y la imagen se expandirá (en nuestro caso nuestra imagen original era de 3504×2332 píxeles) en ambas direcciones, por lo que se verá deformada.
mogrify -resize 800x200 prueba.jpg
En este caso NO utilizamos el signo de cierre de admiración (con la misma imagen de 3504×2332 píxeles) y al ejecutar el comando anterior nos produce una imagen de 201×200 píxeles lo cual respeta la relación ancho contra altura de la imagen original.
Converseen: interfaz gráfica basada en ImageMagick.
Como ImageMagick es Software Libre y está escrito en lenguaje C, el equipo de programación de fasterland.net en la persona de Francesco Mondello, sacaron partido de esto y desarrollaron una interfaz gráfica para otros sistemas operativos, con ustedes un bonito vídeo de presentación de Converseen:
Converseen, thanks to ImageMagick, the powerful image manipulation library on which the program leans it’s basis, can supports more than 100 image formats including DPX, EXR, GIF, JPEG, JPEG-2000, PhotoCD, PNG, Postscript, SVG, TIFF and many others.
Converseen is very easy to use, it’s designed to be fast, practical and, overall, you can get it for free!
Converseen incluso va más allá y le da valor agregado al permitir convertir un archivo en formato pdf en una serie de imágenes (por ahora desconocemos si las utilerías para manejar archivos en formato pertenecen a ImageMagick y por eso decimos que es un valor agregado):
Como podéis observar, Converseen PERMITE redimensionar de manera masiva las imágenes de una o varias carpetas e incluso ofrece una vista previa, prefijo para nombres de archivos (y ubicarlos en otra carpeta) y mucho más, ¡es como una navaja suiza!
Por último en esta sección, os dejamos el vídeo tutorial sobre cómo instalarlo en Ubuntu y el enlace hacia la propia página web del autor donde publica una entrada al respecto:
A nosotros en lo particular nos encanta la línea de comandos, donde para instalar Converseen solo debemos introducir estas dos sentencias (puede tardar algo de tiempo, dependiendo de su velocidad de descarga de internet):
sudo apt-get update sudo apt-get install converseen
ImageMagick y la seguridad informática.
El Señor Pablo González, Ingeniero Informático, autor de numerosos libros en España y asesor de seguridad de reconocidas empresas radicadas en ese reino, publicó el jueves cinco de mayo de dosmildieciséis un artículo titulado «Command injection en ImageMagick: Actualiza todos tus servers GNU/Linux o te podrían hackear con una imagen» donde indica un fallo de seguridad en ImageMagick que permitiría ejecutar comandos bash con el nivel de usuario que hayamos colocado en nuestro servidor GNU/Linux.
Aunque esta parte es algo más avanzada para este humilde tutorial, dado lo delicado del asunto procedemos a explicarlo «en cristiano» o en castellano llano para que lo tengáis presente y trataremos de explicarlo lo más simple posible.
Como mencionamos ImageMagick está ampliamente extendido del mundo Unix de donde nació y tal como lo relatamos lo incorporaron a Linux y otros sistemas operativos. Pero bajo linux la potencia de ImageMagick se elevó a nivel tal que se usa mucho en servidores web con ayuda de otros lenguajes tales como (no limitados y/o combinados) HTML, PHP, PYTHON, etc.
He aquí que hay páginas web que ofrecen herramientas de edición y/o creación de imágenes a los usuarios. De hecho nosotros aprovechamos el código existente para crear CAPTCHAS para distintas páginas web de nuestros clientes (de nuevo, humildemente desarrolladas). En este caso es bastante seguro la creación de imágenes con PHP y sus librerías pero con ImageMagick hasta podemos permitir que nuestros usuarios web «suban» imágenes a nuestro servidor y allí es donde radica el problema.
Si un atacante malicioso -o no- subiera una imágen con código embebido meticulosamente manipulado para tal efecto al aplicarle el comando convert que estudiamos permite ejecutar el comando «infectado» en la línea de comandos.
El caso está ampliamente documentado en el siguiente enlace, pero no pudimos reproducir el comportamiento del fallo esperado porque regularmente mantenemos actualizados nuestros equipos a los repositorios oficiales.
Convertir una imagen PNG en SVG
Actualizado el día domingo 2 de diciembre de 2018
En esta oportunidad tuvimos la necesidad de convertir un hermoso gráfico con la arquitectura de funcionamiento de un popular sistema de monitorización, OpenNMS e intentamos con varias páginas web que prometen «villas y castillos» pero los resultados fueron pésimos.
«Si quieres que se haga bien, hágalo usted mismo» así que investigando conseguimos que se puede lograr convertir primero la imagen de PNG a PNM y luego con otro programa de PNM a SVG. para la primera tarea ¡cómo no! ImageMagick:
convert archivo.png archivo.pnm # PNG a PNM potrace archivo.pnm -s -o archivo.svg # PNM a SVG
El resultado es el mismo pésimo trabajo que obtuvimos en línea, pero al menos no dependemos de terceros para futuras labores, esperamos sea útil a alguien en la red.
Enlaces relacionados.
Enlaces en idioma castellano:
- «Cómo editar, convertir y redimensionar varias imágenes al mismo tiempo en Ubuntu» por Pablo Aparicio en Ubunlog.
- «Command injection en ImageMagick: Actualiza todos tus servers GNU/Linux o te podrían hackear con una imagen» por Pablo González en elladodelmal.com
- «Cómo redimensionar fotos en bloque en Ubuntu» por Joaquín García en Ubunlog.com
Enlaces en idioma inglés:
- «The ImageMagick command-line tools» at ImageMagick.org.
- ImageMagick at Wikipedia.
- «Fred’s ImageMagick Scripts» by Fred Weinhaus.
- «PHP 5» at W3schools.com
- «Image Magick» by John Cristy.
- «Converseen» por Francesco Mondello en fasterland.net